|
|
首先,本文感激 @白小鱼 白小鱼:联邦学习开源框架(2022.05.22)的贡献。
在此基础上,打开了各家联邦学习框架的源码,过了下 repo 中的一些架构说明,以及涉及到 train 流程的关键代码,基本上对各家框架的内部运行机制就有了较整体的认识。同时,给各家框架评了个分,供参考。有时间再补充更多实现细节,这里先挖坑~
0、竞品对照
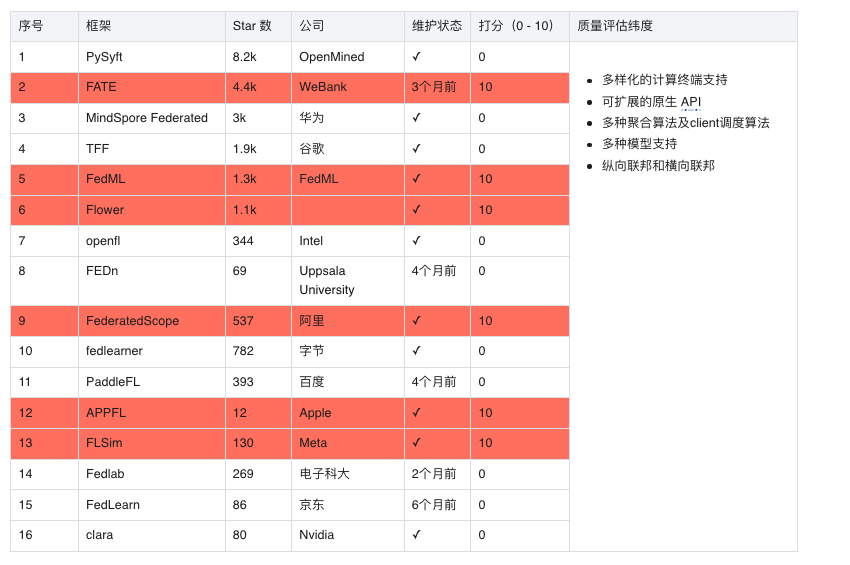
- 统计截止时间 2022/7/12
- 打分纯凭笔者爱好~
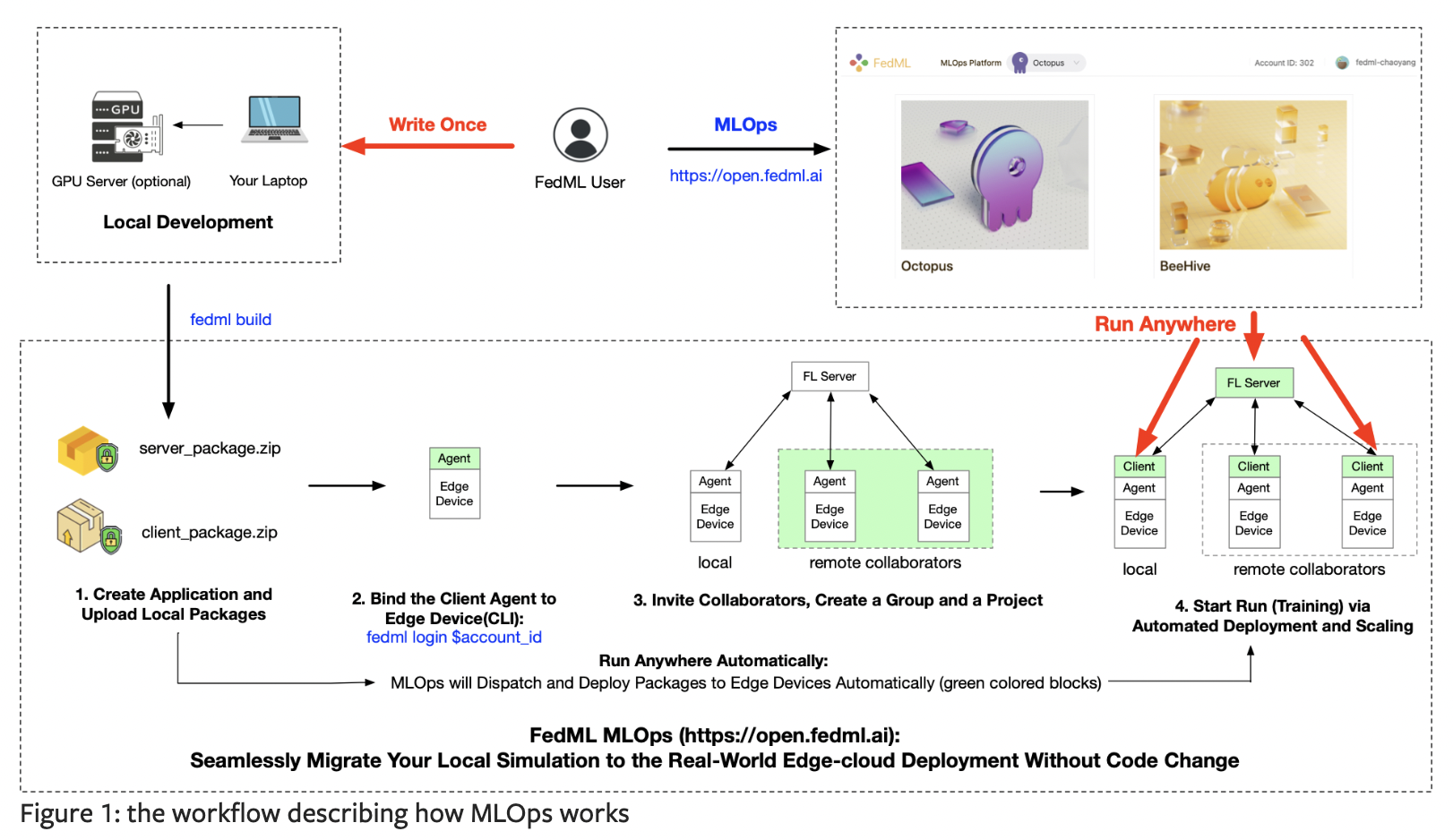
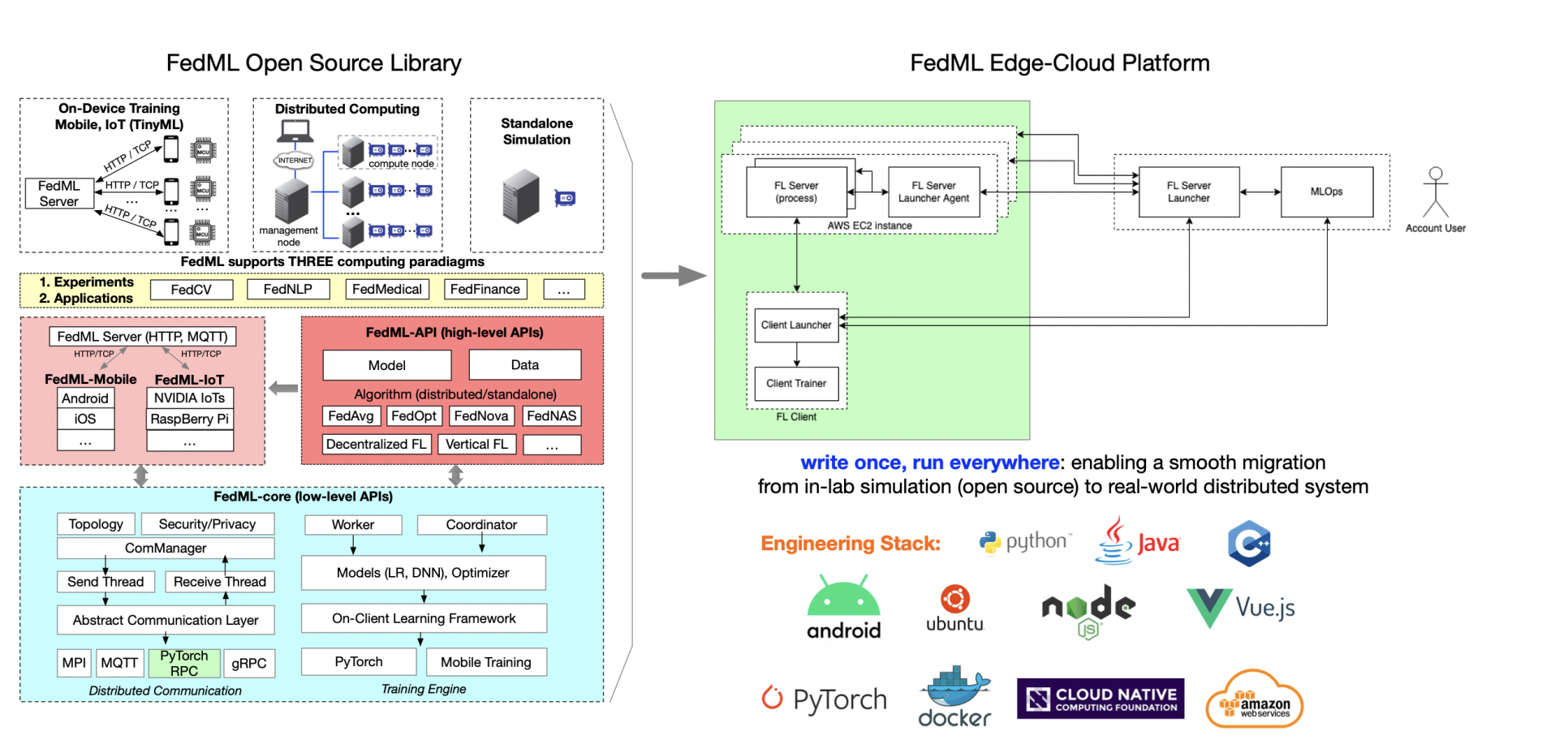
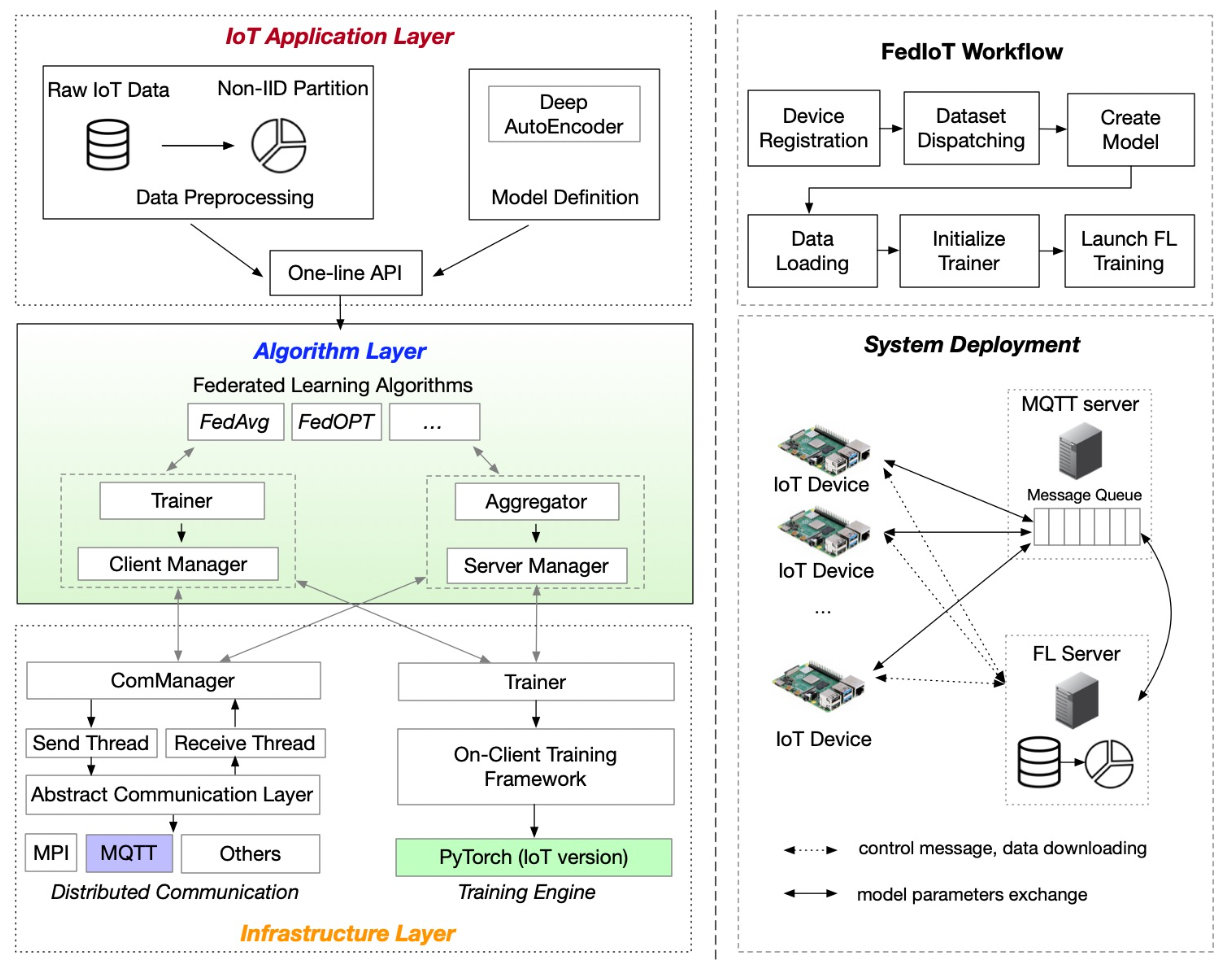
1、FedML https://fedml.ai/
- 关键 code
- FedML/python/fedml/simulation/nccl/base_framework/Server.py
- FedML/python/examples/centralized/main.py
- FedML/python/fedml/cli/edge_deployment/client_runner.py
def on_message(self, client, userdata, msg):
fedml.logger.info(f”on_message({msg.topic}, {str(msg.payload)})”)
_listener = self._listeners.get(msg.topic, None)
if _listener is not None and callable(_listener):
_listener(msg.topic, str(msg.payload))
# ... #
def add_message_listener(self, topic, listener):
fedml.logger.info(f”add_message_listener({topic})”)
self._listeners[topic] = listener
def remove_message_listener(self, topic):
fedml.logger.info(f”remove_message_listener({topic})”)
del self._listeners[topic]
- MLOps(APIs related to machine learning operation platform)
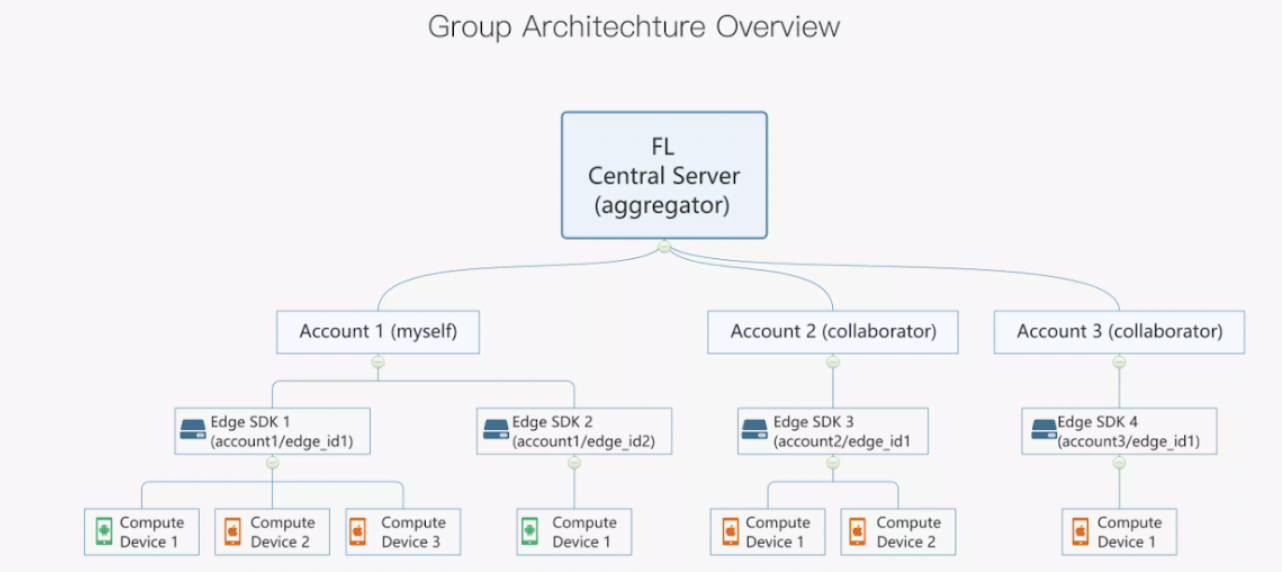
2、flower https://github.com/adap/flower/tree/main
- 关键 code
- flower/src/py/flwr/client/app.py
def start_client(
server_address: str,
client: Client,
grpc_max_message_length: int = GRPC_MAX_MESSAGE_LENGTH,
root_certificates: Optional[bytes] = None,
) -> None:
”””Start a Flower Client which connects to a gRPC server.
Parameters
----------
server_address: str. The IPv6 address of the server. If the Flower
server runs on the same machine on port 8080, then `server_address`
would be `”[::]:8080”`.
client: flwr.client.Client. An implementation of the abstract base
class `flwr.client.Client`.
grpc_max_message_length: int (default: 536_870_912, this equals 512MB).
The maximum length of gRPC messages that can be exchanged with the
Flower server. The default should be sufficient for most models.
Users who train very large models might need to increase this
value. Note that the Flower server needs to be started with the
same value (see `flwr.server.start_server`), otherwise it will not
know about the increased limit and block larger messages.
root_certificates: bytes (default: None)
The PEM-encoded root certificates as a byte string. If provided, a secure
connection using the certificates will be established to a
SSL-enabled Flower server.
Returns
-------
None
Examples
--------
Starting a client with insecure server connection:
>>> start_client(
>>> server_address=localhost:8080,
>>> client=FlowerClient(),
>>> )
Starting a SSL-enabled client:
>>> from pathlib import Path
>>> start_client(
>>> server_address=localhost:8080,
>>> client=FlowerClient(),
>>> root_certificates=Path(”/crts/root.pem”).read_bytes(),
>>> )
”””
while True:
sleep_duration: int = 0
with grpc_connection(
server_address,
max_message_length=grpc_max_message_length,
root_certificates=root_certificates,
) as conn:
receive, send = conn
while True:
server_message = receive()
client_message, sleep_duration, keep_going = handle(
client, server_message
)
send(client_message)
if not keep_going:
break
if sleep_duration == 0:
log(INFO, ”Disconnect and shut down”)
break
# Sleep and reconnect afterwards
log(
INFO,
”Disconnect, then re-establish connection after %s second(s)”,
sleep_duration,
)
time.sleep(sleep_duration)
- flower/src/py/flwr/client/grpc_client/message_handler.py
def handle(
client: Client, server_msg: ServerMessage
) -> Tuple[ClientMessage, int, bool]:
”””Handle incoming messages from the server.
Parameters
----------
client : Client
The Client instance provided by the user.
Returns
-------
client_message: ClientMessage
The message comming from the server, to be processed by the client.
sleep_duration : int
Number of seconds that the client should disconnect from the server.
keep_going : bool
Flag that indicates whether the client should continue to process the
next message from the server (True) or disconnect and optionally
reconnect later (False).
”””
field = server_msg.WhichOneof(”msg”)
if field == ”reconnect”:
disconnect_msg, sleep_duration = _reconnect(server_msg.reconnect)
return disconnect_msg, sleep_duration, False
if field == ”properties_ins”:
return _get_properties(client, server_msg.properties_ins), 0, True
if field == ”get_parameters”:
return _get_parameters(client), 0, True
if field == ”fit_ins”:
return _fit(client, server_msg.fit_ins), 0, True
if field == ”evaluate_ins”:
return _evaluate(client, server_msg.evaluate_ins), 0, True
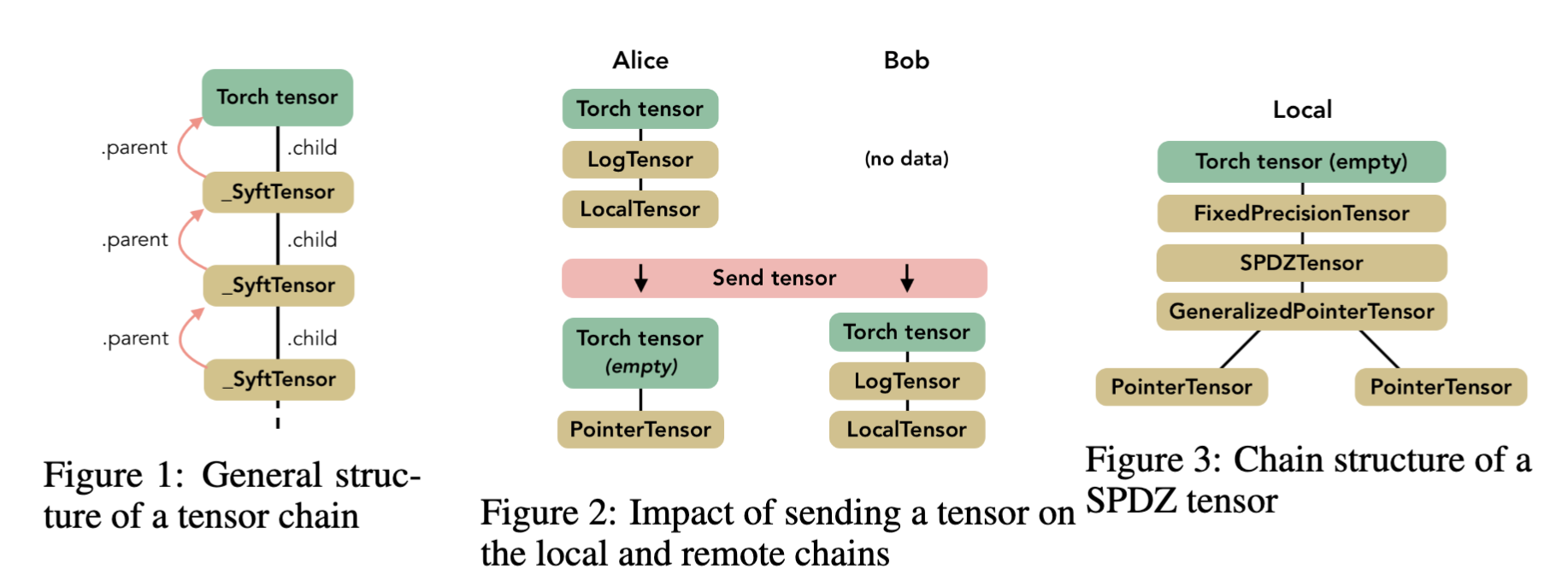
raise UnknownServerMessage()3、pysft https://github.com/OpenMined/PySyft
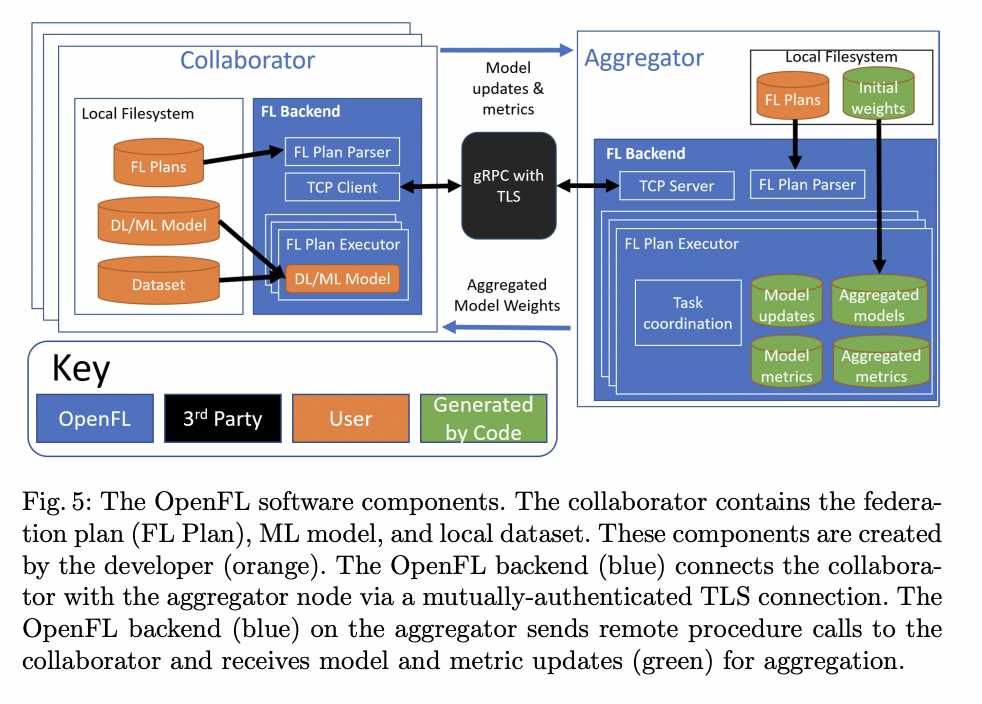
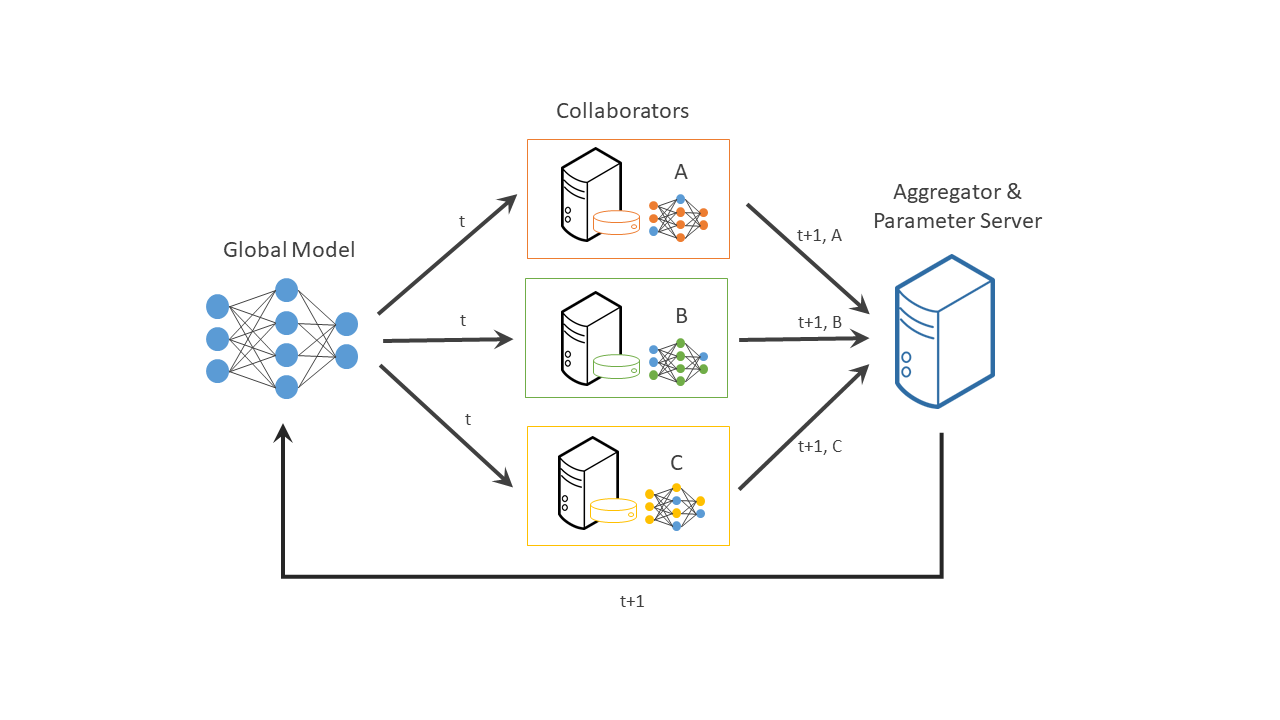
4、openfl https://github.com/intel/openfl/blob/develop/openfl/component/collaborator/collaborator.py
def run(self):
”””Run the collaborator.”””
while True:
tasks, round_number, sleep_time, time_to_quit = self.get_tasks()
if time_to_quit:
break
elif sleep_time > 0:
sleep(sleep_time) # some sleep function
else:
self.logger.info(f'Received the following tasks: {tasks}')
for task in tasks:
self.do_task(task, round_number)
# Cleaning tensor db
self.tensor_db.clean_up(self.db_store_rounds)
self.logger.info('End of Federation reached. Exiting...')5、FEDn https://github.com/scaleoutsystems/fedn/blob/master/fedn/fedn/client.py
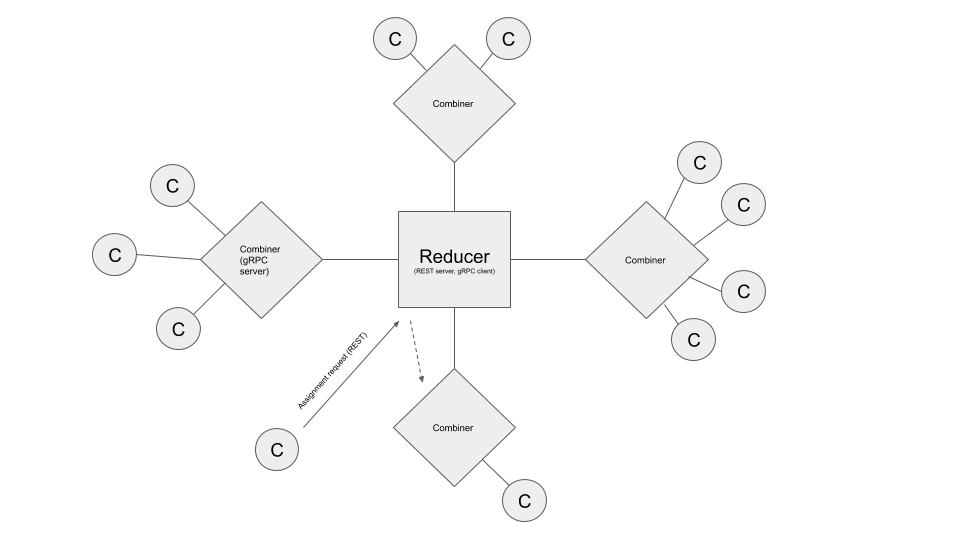
def _process_training_request(self, model_id):
”””Process a training (model update) request.
Parameters
----------
model_id : Str
The id of the model to update.
”””
self._send_status(”\t Starting processing of training request for model_id {}”.format(model_id))
self.state = ClientState.training
try:
meta = {}
tic = time.time()
mdl = self.get_model(str(model_id))
meta['fetch_model'] = time.time() - tic
inpath = self.helper.get_tmp_path()
with open(inpath, 'wb') as fh:
fh.write(mdl.getbuffer())
outpath = self.helper.get_tmp_path()
tic = time.time()
# TODO: Check return status, fail gracefully
self.dispatcher.run_cmd(”train {} {}”.format(inpath, outpath))
meta['exec_training'] = time.time() - tic
tic = time.time()
out_model = None
with open(outpath, ”rb”) as fr:
out_model = io.BytesIO(fr.read())
# Push model update to combiner server
updated_model_id = uuid.uuid4()
self.set_model(out_model, str(updated_model_id))
meta['upload_model'] = time.time() - tic
os.unlink(inpath)
os.unlink(outpath)
except Exception as e:
print(”ERROR could not process training request due to error: {}”.format(e), flush=True)
updated_model_id = None
meta = {'status': 'failed', 'error': str(e)}
self.state = ClientState.idle
return updated_model_id, meta6、FederatedScope https://federatedscope.io/refs/core.html && https://github.com/alibaba/FederatedScope
- 核心模块
- configs
- monitors
- FedRunner(This class is used to construct an FL course, which includes _set_up and run)
- Client
- Server
broadcast_client_address、broadcast_model_para、callback_funcs_for_join_in、callback_funcs_for_metrics(The handling function for receiving the evaluation results)、callback_funcs_model_para(The handling function for receiving model parameters)、check_client_join_in
- trainers.Context
- trainers.Trainer(Register, organize and run the train/test/val procedures, called by FL client)
- 关键 code
- FederatedScope/federatedscope/core/worker/client.py
def register_handlers(self, msg_type, callback_func):
”””
To bind a message type with a handling function.
Arguments:
msg_type (str): The defined message type
callback_func: The handling functions to handle the received message
”””
self.msg_handlers[msg_type] = callback_func
def _register_default_handlers(self):
self.register_handlers('assign_client_id',
self.callback_funcs_for_assign_id)
self.register_handlers('ask_for_join_in_info',
self.callback_funcs_for_join_in_info)
self.register_handlers('address', self.callback_funcs_for_address)
self.register_handlers('model_para',
self.callback_funcs_for_model_para)
self.register_handlers('ss_model_para',
self.callback_funcs_for_model_para)
self.register_handlers('evaluate', self.callback_funcs_for_evaluate)
self.register_handlers('finish', self.callback_funcs_for_finish)
def callback_funcs_for_join_in_info(self, message: Message):
”””
The handling function for receiving the request of join in information (such as batch_size, num_of_samples) during the joining process.
Arguments:
message: The received message
”””
requirements = message.content
join_in_info = dict()
for requirement in requirements:
if requirement.lower() == 'num_sample':
if self._cfg.federate.batch_or_epoch == 'batch':
num_sample = self._cfg.federate.local_update_steps * self._cfg.data.batch_size
else:
num_sample = self._cfg.federate.local_update_steps * self.trainer.ctx.num_train_batch
join_in_info['num_sample'] = num_sample
else:
raise ValueError(
'Fail to get the join in information with type {}'.format(
requirement))
self.comm_manager.send(
Message(msg_type='join_in_info',
sender=self.ID,
receiver=[self.server_id],
state=self.state,
content=join_in_info))
- FederatedScope/federatedscope/core/worker/server.py
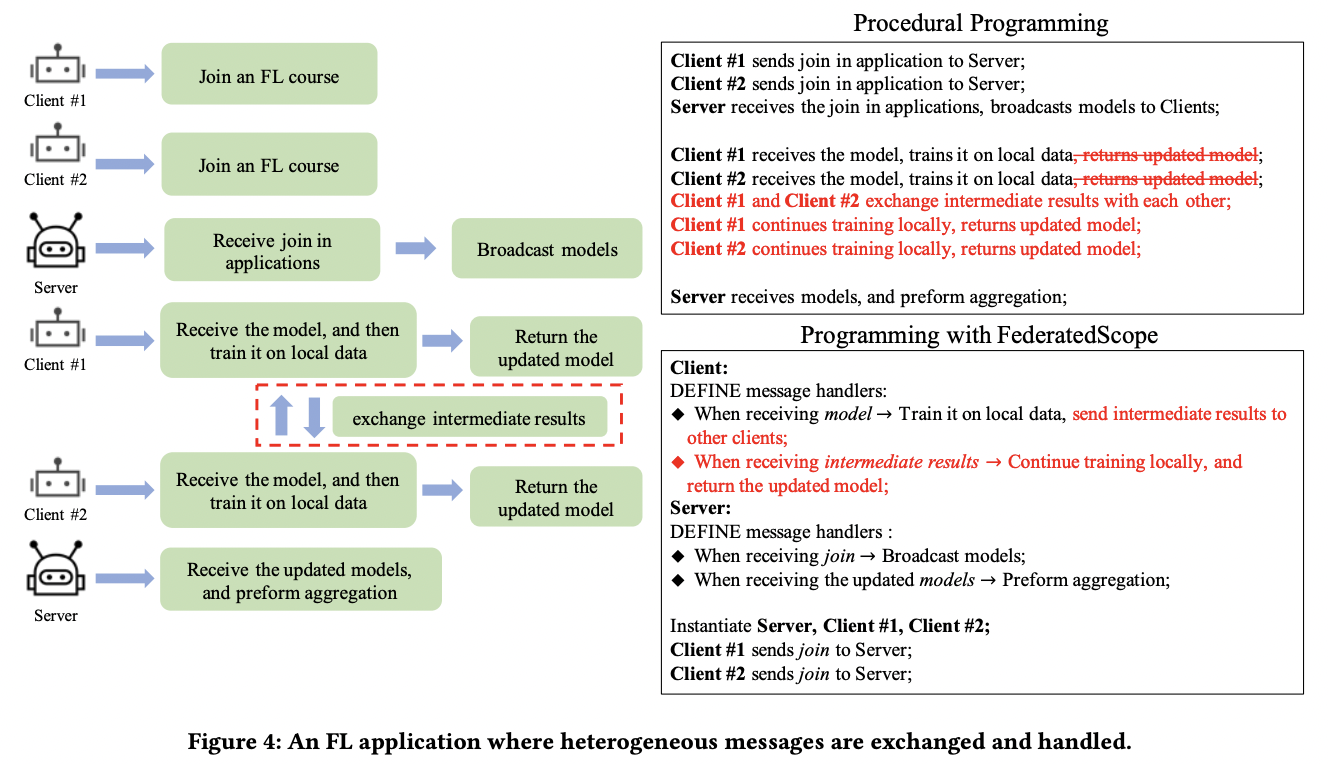
7、FATE https://github.com/FederatedAI/FATE
def run(self, start_serving=0):
config_dir_path = self._make_runtime_conf()
time_print('Start task: {}'.format(”job submit”))
stdout = flow_client.job.submit(config_data=get_config_file(config_dir_path),
dsl_data=get_config_file(self.dsl_file))
self.task_status(stdout, ”Training task exec fail”)
print(json.dumps(stdout, indent=4))
job_id = stdout.get(”jobId”)
self.model_id = stdout['data']['model_info']['model_id']
self.model_version = stdout['data']['model_info']['model_version']
self._check_status(job_id)
auc = self._get_auc(job_id)
if auc < self.auc_base:
time_print(”[Warning] The auc: {} is lower than expect value: {}”.format(auc, self.auc_base))
else:
time_print(”[Train] train auc:{}”.format(auc))
time.sleep(WAIT_UPLOAD_TIME / 100)
self.start_predict_task()
if start_serving:
self._load_model()
self._bind_model()
def start_predict_task(self):
self._deploy_model()
config_dir_path = self._make_runtime_conf(”predict”)
time_print('Start task: {}'.format(”job submit”))
stdout = flow_client.job.submit(config_data=get_config_file(config_dir_path))
self.task_status(stdout, ”Training task exec fail”)
job_id = stdout.get(”jobId”)
self._check_status(job_id)
time_print(”[Predict Task] Predict success”)8、fedlearner https://github.com/bytedance/fedlearner
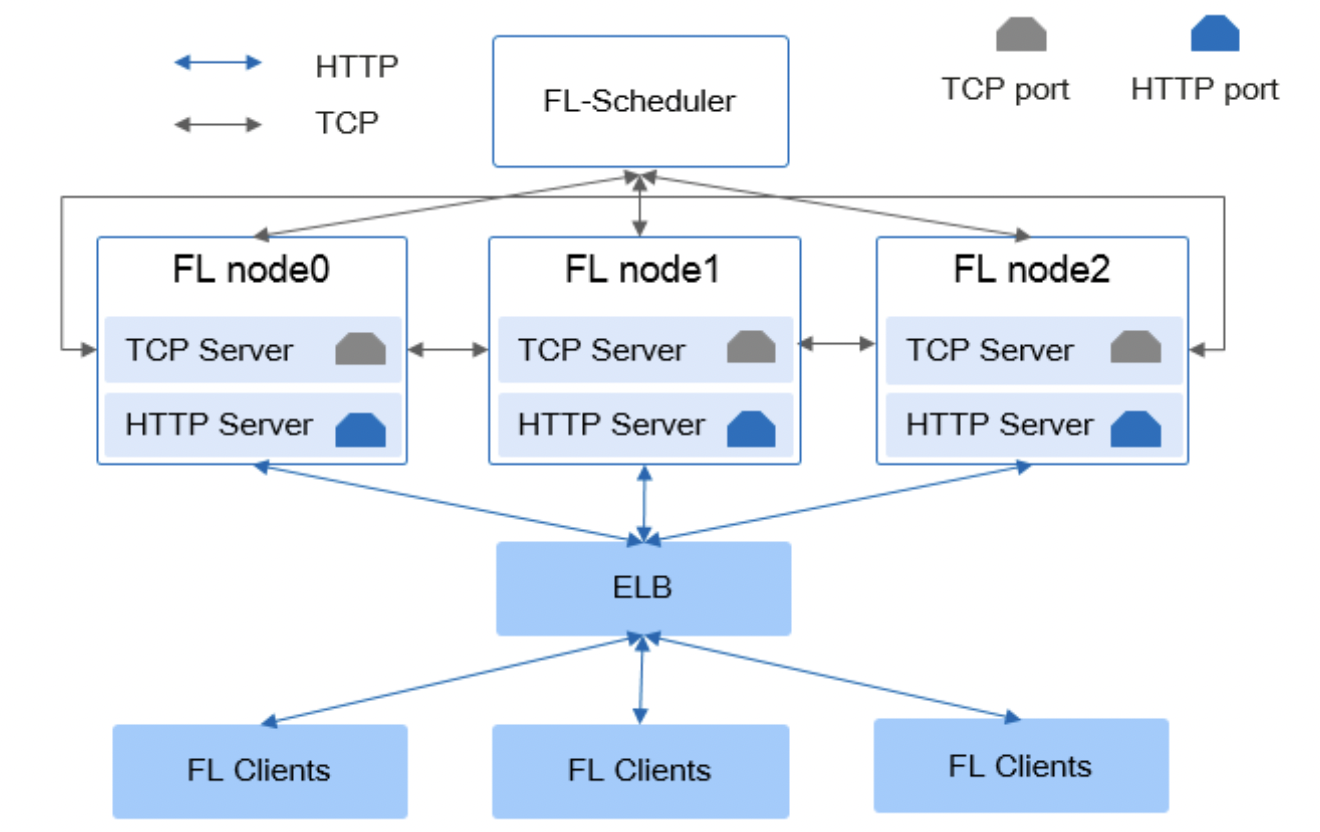
9、MindSpore Federated https://github.com/mindspore-ai/mindspore/tree/master/tests/st/fl
10、PaddleFL https://github.com/PaddlePaddle/PaddleFL
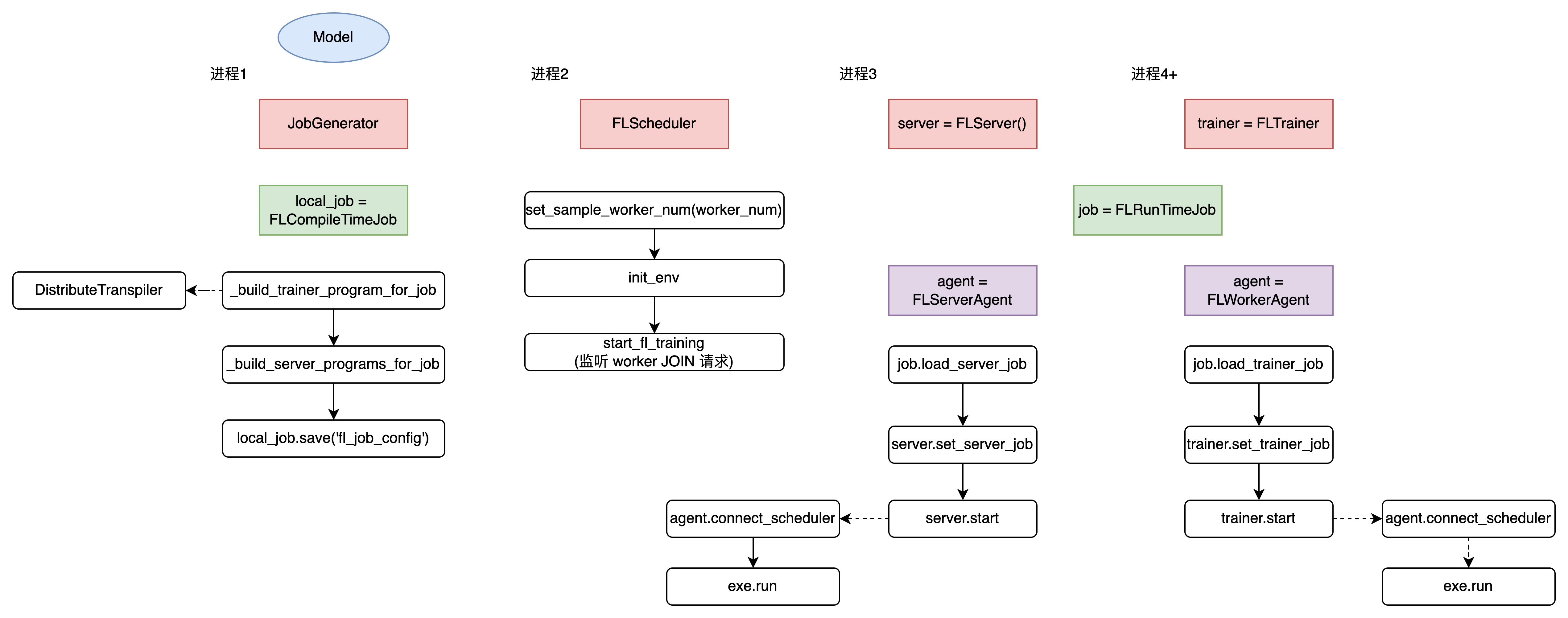
上图是我一横一竖画出来的,双击屏幕点个赞不外分吧 ~
11、APPFL https://github.com/APPFL/APPFL
def run_client(
cfg: DictConfig,
cid: int,
model: nn.Module,
loss_fn: nn.Module,
train_data: Dataset,
gpu_id: int = 0,
test_data: Dataset = Dataset(),
) -> None:
”””Launch gRPC client to connect to the server specified in the configuration.
Args:
cfg (DictConfig): the configuration for this run
cid (int): cliend_id
model (nn.Module): neural network model to train
loss_fn (nn.Module): loss function
train_data (Dataset): training data
gpu_id (int): GPU ID
”””
logger = logging.getLogger(__name__)
if cfg.server.use_tls == True:
uri = cfg.server.host
else:
uri = cfg.server.host + ”:” + str(cfg.server.port)
## We assume to have as many GPUs as the number of MPI processes.
if cfg.device == ”cuda”:
device = f”cuda:{gpu_id}”
else:
device = cfg.device
””” log for clients”””
output_filename = cfg.output_filename + ”_client_%s” % (cid)
outfile = client_log(cfg.output_dirname, output_filename)
batch_size = cfg.train_data_batch_size
if cfg.batch_training == False:
batchsize = len(train_data)
logger.debug(
f”[Client ID: {cid: 03}] connecting to (uri,tls)=({uri},{cfg.server.use_tls}).”
)
comm = FLClient(
cid,
uri,
cfg.server.use_tls,
max_message_size=cfg.max_message_size,
api_key=cfg.server.api_key,
)
# Retrieve its weight from a server.
weight = -1.0
i = 1
logger.info(f”[Client ID: {cid: 03}] requesting weight to the server.”)
try:
while True:
weight = comm.get_weight(len(train_data))
logger.debug(
f”[Client ID: {cid: 03}] trial {i}, requesting weight ({weight}).”
)
if weight >= 0.0:
break
time.sleep(5)
except KeyboardInterrupt:
logger.info(f”[Client ID: {cid: 03}] terminating the client.”)
return
if weight < 0.0:
logger.error(f”[Client ID: {cid: 03}] weight ({weight}) retrieval failed.”)
return
”Run validation if test data is given or the configuration is enabled.”
if cfg.validation == True and len(test_data) > 0:
test_dataloader = DataLoader(
test_data,
num_workers=cfg.num_workers,
batch_size=cfg.test_data_batch_size,
shuffle=cfg.test_data_shuffle,
)
else:
cfg.validation = False
test_dataloader = None
fed_client = eval(cfg.fed.clientname)(
cid,
weight,
copy.deepcopy(model),
loss_fn,
DataLoader(
train_data,
num_workers=cfg.num_workers,
batch_size=batch_size,
shuffle=cfg.train_data_shuffle,
pin_memory=True,
),
cfg,
outfile,
test_dataloader,
**cfg.fed.args,
)
## name of parameters
model_name = []
for name, _ in fed_client.model.named_parameters():
model_name.append(name)
# Start federated learning.
cur_round_number, job_todo = comm.get_job(Job.INIT)
prev_round_number = 0
learning_time = 0.0
send_time = 0.0
cumul_learning_time = 0.0
while job_todo != Job.QUIT:
if job_todo == Job.TRAIN:
if prev_round_number != cur_round_number:
logger.info(
f”[Client ID: {cid: 03} Round #: {cur_round_number: 03}] Start training”
)
update_model_state(comm, fed_client.model, cur_round_number)
logger.info(
f”[Client ID: {cid: 03} Round #: {cur_round_number: 03}] Received model update from server”
)
prev_round_number = cur_round_number
time_start = time.time()
local_state = fed_client.update()
time_end = time.time()
learning_time = time_end - time_start
cumul_learning_time += learning_time
if (
cur_round_number % cfg.checkpoints_interval == 0
or cur_round_number == cfg.num_epochs
):
”””Saving model”””
if cfg.save_model == True:
save_model_iteration(cur_round_number, fed_client.model, cfg)
time_start = time.time()
comm.send_learning_results(
local_state[”penalty”],
local_state[”primal”],
local_state[”dual”],
cur_round_number,
)
time_end = time.time()
send_time = time_end - time_start
logger.info(
f”[Client ID: {cid: 03} Round #: {cur_round_number: 03}] Trained (Time %.4f, Epoch {cfg.fed.args.num_local_epochs: 03}) and sent results back to the server (Elapsed %.4f)”,
learning_time,
send_time,
)
else:
logger.info(
f”[Client ID: {cid: 03} Round #: {cur_round_number: 03}] Waiting for next job”
)
time.sleep(5)
cur_round_number, job_todo = comm.get_job(job_todo)
if job_todo == Job.QUIT:
logger.info(
f”[Client ID: {cid: 03} Round #: {cur_round_number: 03}] Quitting... Learning %.4f Sending %.4f Receiving %.4f Job %.4f Total %.4f”,
cumul_learning_time,
comm.time_send_results,
comm.time_get_tensor,
comm.time_get_job,
comm.get_comm_time(),
)
# Update with the most recent weights before exit.
update_model_state(comm, fed_client.model, cur_round_number)
outfile.close()12、FLSim https://github.com/facebookresearch/FLSim/blob/main/examples/cifar10_example.py
- 关键 code
- FLSim/flsim/utils/async_trainer/device_state.py
class TrainingState(Enum):
# Orderinig is important
# For devices that have the same next_event_time(), we want devices that
# ”further along” in training to be chosen first
# hence, TRAINING_FINISHED < TRAINING < WAITING_FOR_START
TRAINING_FINISHED = auto()
TRAINING = auto()
WAITING_FOR_START = auto()
# https://docs.python.org/3/library/enum.html#orderedenum
def __lt__(self, other):
if self.__class__ is other.__class__:
return self.value < other.value
return NotImplemented
- FLSim/flsim/utils/async_trainer/async_user_selector.py
class AsyncUserSelectorInfo:
r”””
Dataclass to encapsulate a selected user for async training
user_data (IFLUserData): seleected user data in the dataset
user_index (int): the index for user_data assuming IFLDataProvider.train_users is a List
”””
user_data: IFLUserData
user_index: int
class AsyncUserSelector(abc.ABC):
def __init__(self, data_provider: IFLDataProvider):
self.data_provider: IFLDataProvider = data_provider
@abc.abstractmethod
def get_random_user(self) -> AsyncUserSelectorInfo:
r”””
Returns a random IFLUserData from the dataset and the user index (for testing)
”””
pass
class RandomAsyncUserSelector(AsyncUserSelector):
def __init__(self, data_provider: IFLDataProvider):
super().__init__(data_provider)
def get_random_user(self) -> AsyncUserSelectorInfo:
user_index = np.random.randint(0, self.data_provider.num_train_users())
return AsyncUserSelectorInfo(
user_data=self.data_provider.get_train_user(user_index),
user_index=user_index,
)
class RoundRobinAsyncUserSelector(AsyncUserSelector):
r”””
Chooses users in round-robin order, starting from user=0.
Particularly useful for testing.
”””
def __init__(self, data_provider: IFLDataProvider):
super().__init__(data_provider)
self.current_user_index: int = 0
def get_random_user(self) -> AsyncUserSelectorInfo:
user_index = self.current_user_index
self.current_user_index = (
self.current_user_index + 1
) % self.data_provider.num_train_users()
return AsyncUserSelectorInfo(
user_data=self.data_provider.get_train_user(user_index),
user_index=user_index,
)
class AsyncUserSelectorType(Enum):
RANDOM = auto()
ROUND_ROBIN = auto()
class AsyncUserSelectorFactory:
@classmethod
def create_users_selector(
cls, type: AsyncUserSelectorType, data_provider: IFLDataProvider
):
if type == AsyncUserSelectorType.RANDOM:
return RandomAsyncUserSelector(data_provider)
elif type == AsyncUserSelectorType.ROUND_ROBIN:
return RoundRobinAsyncUserSelector(data_provider)
else:
raise AssertionError(f”Unknown user selector type: {type}”)13、Fedlab https://github.com/SMILELab-FL/FedLab/tree/master/examples/cross-process-mnist
- 纵向联邦
- 关键 code FedLab/fedlab/core/client/manager.py
class ActiveClientManager(ClientManager):
”””Active communication :class:`NetworkManager` for client in asynchronous FL pattern.
Args:
network (DistNetwork): Network configuration and interfaces.
trainer (ClientTrainer): Subclass of :class:`ClientTrainer`. Provides :meth:`local_process` and :attr:`uplink_package`. Define local client training procedure.
logger (Logger, optional): Object of :class:`Logger`.
”””
def __init__(self, network, trainer, logger=None):
super().__init__(network, trainer)
self._LOGGER = Logger() if logger is None else logger
def main_loop(self):
”””Actions to perform on receiving new message, including local training
1. client requests data from server (ACTIVELY).
2. after receiving data, client will train local model.
3. client will synchronize with server actively.
”””
while True:
# request model actively
self.request()
# waits for data from server
_, message_code, payload = self._network.recv(src=0)
if message_code == MessageCode.Exit:
# client exit feedback
if self._network.rank == self._network.world_size - 1:
self._network.send(message_code=MessageCode.Exit, dst=0)
break
elif message_code == MessageCode.ParameterUpdate:
self._trainer.local_process(payload)
self.synchronize()
else:
raise ValueError(
”Invalid MessageCode {}. Please check MessageCode Enum.”.
format(message_code))
def request(self):
”””Client request”””
self._LOGGER.info(”request parameter procedure.”)
self._network.send(message_code=MessageCode.ParameterRequest, dst=0)
def synchronize(self):
”””Synchronize with server”””
self._LOGGER.info(”Uploading information to server.”)
self._network.send(content=self._trainer.uplink_package,
message_code=MessageCode.ParameterUpdate,
dst=0)14、FedLearn https://github.com/cyqclark/fedlearn-algo/blob/master/core/client/client.py
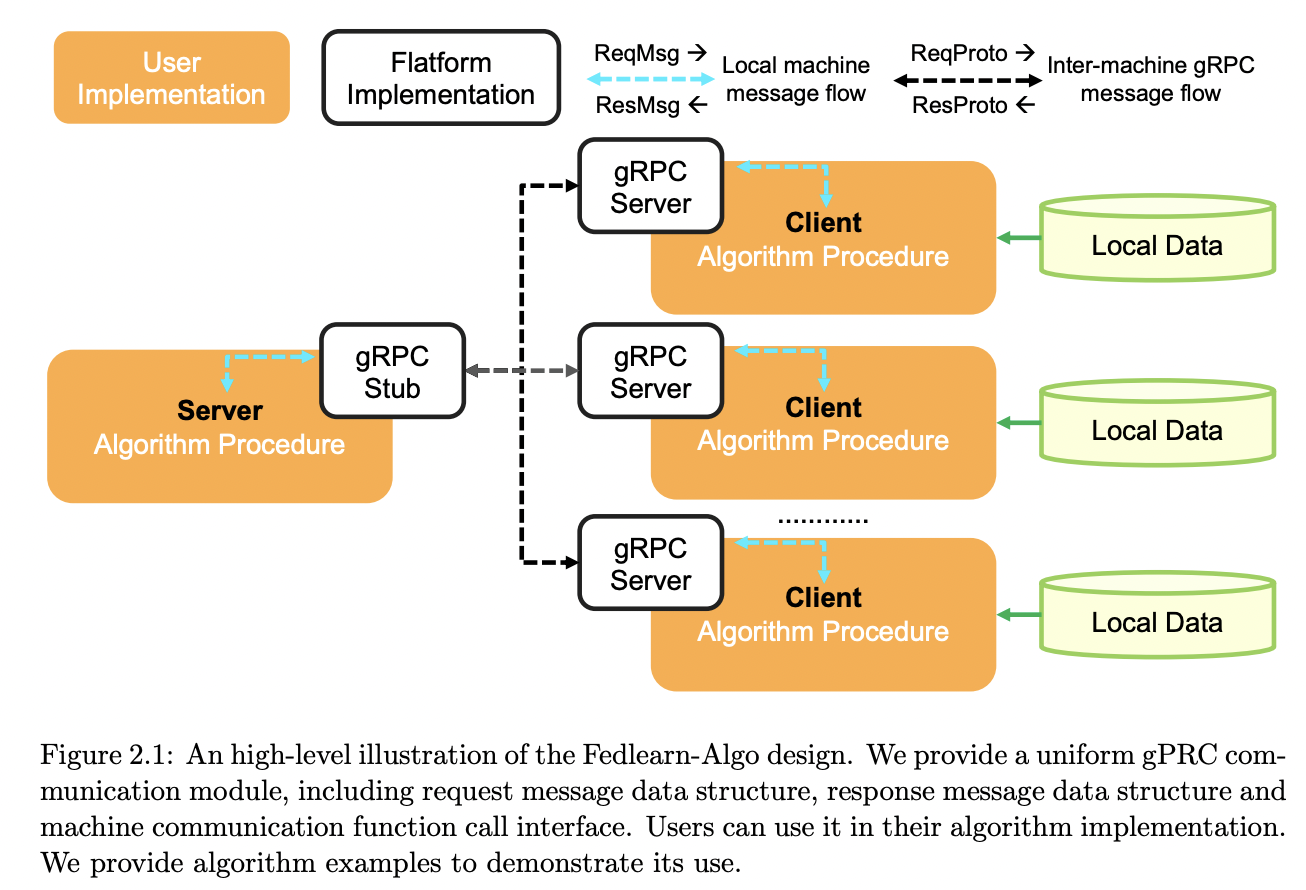
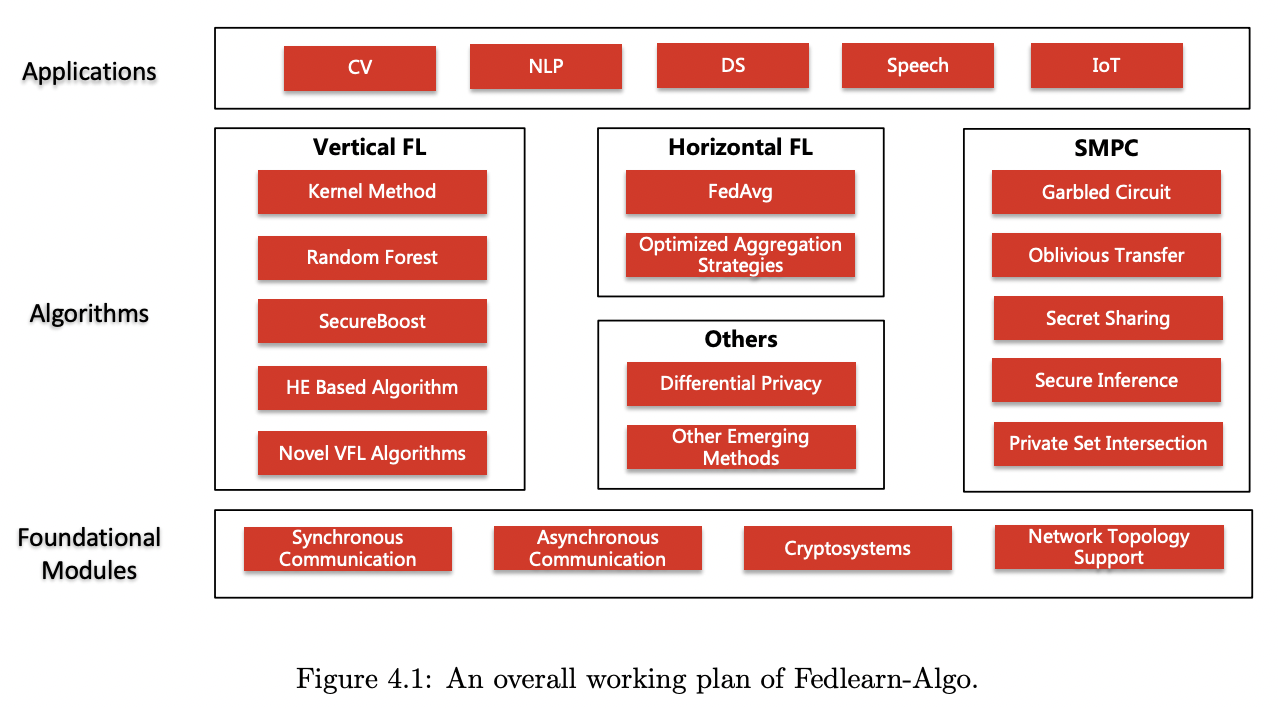
def _exp_training_pipeline(self, init_phase: str, is_parallel=False) -> None:
”””
Main training pipeline. The protocol includes the following steps:
1) Initialization
2) While loop of training
3) Post processing after training
Parameters:
-----------
clients: list
List of MachineInfo object that contains the connect information of each client.
Returns
-------
None
”””
# Training initialization. Send initialization signal to all clients.
if not hasattr(self, ”_has_coordinator”):
raise ValueError(”The running client does not have coordinator addon!”)
phase = init_phase
requests = self.coordinator.init_training_control()
responses = self._exp_call_grpc_client(requests, is_parallel)
requests, phase = self.coordinator.synchronous_control(responses, phase)
# Training loop. parallel sending requests
while self.coordinator.is_training_continue():
responses = self._exp_call_grpc_client(requests, is_parallel)
requests, phase = self.coordinator.synchronous_control(responses, phase)
# Training process finish. Send finish signal to all clients.
requests = self.coordinator.post_training_session()
responses = self._exp_call_grpc_client(requests, is_parallel)
def start_serve_termination_block(self):
self.grpc_node.start_serve_termination_block(self.grpc_servicer)15、clara https://github.com/NVIDIA/clara-train-examples/blob/master/Tensorflow-Deprecated/FL/FederatedLearning.ipynb
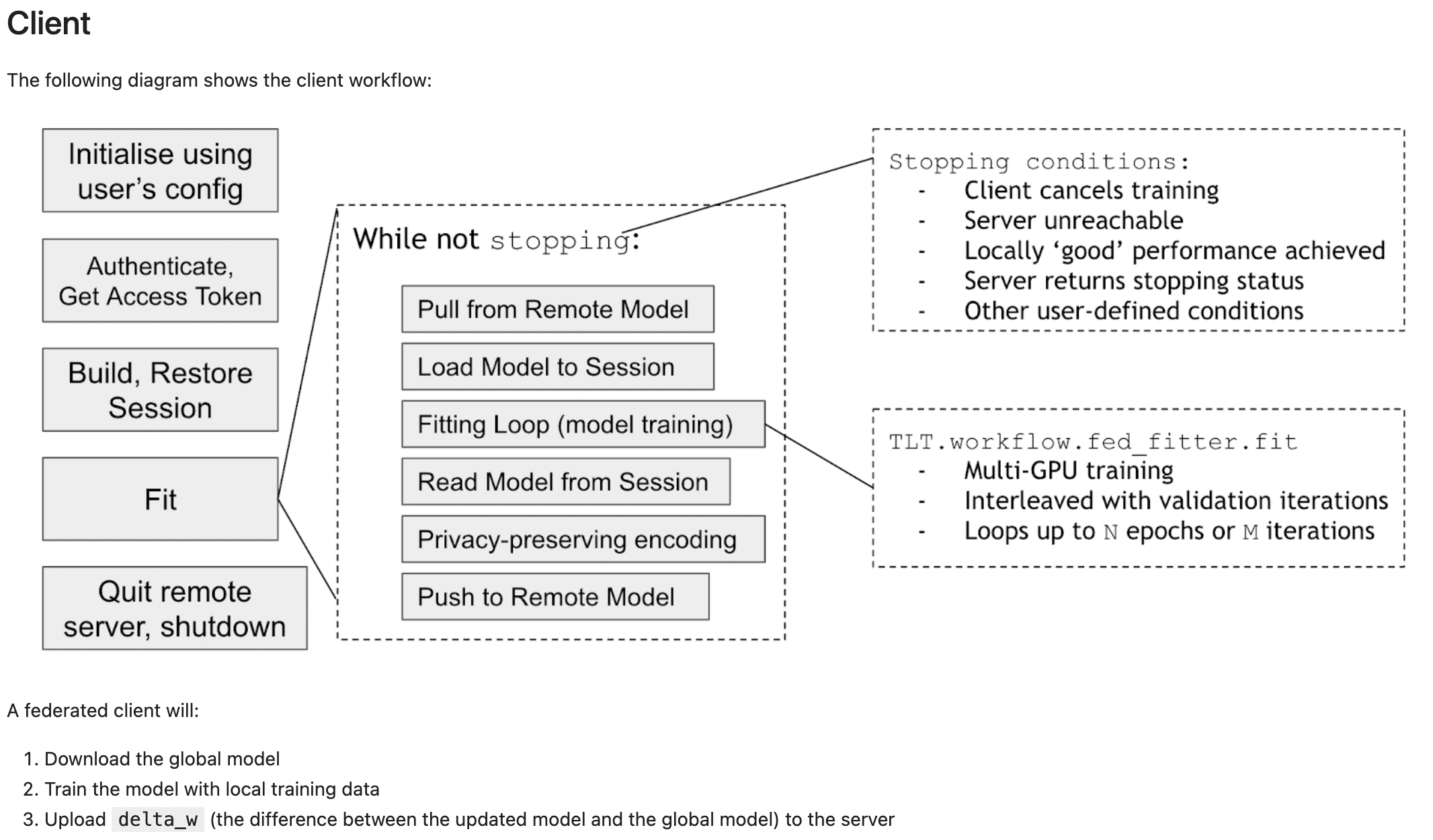
16、TTF(TensorFlow Federated) https://github.com/tensorflow/federated/tree/main
- 关键 code: federated/tensorflow_federated/examples/simple_fedavg/emnist_fedavg_main.py
def main(argv):
if len(argv) > 1:
raise app.UsageError('Too many command-line arguments.')
# If GPU is provided, TFF will by default use the first GPU like TF. The
# following lines will configure TFF to use multi-GPUs and distribute client
# computation on the GPUs. Note that we put server computatoin on CPU to avoid
# potential out of memory issue when a large number of clients is sampled per
# round. The client devices below can be an empty list when no GPU could be
# detected by TF.
client_devices = tf.config.list_logical_devices('GPU')
server_device = tf.config.list_logical_devices('CPU')[0]
tff.backends.native.set_local_python_execution_context(
server_tf_device=server_device, client_tf_devices=client_devices)
train_data, test_data = get_emnist_dataset()
def tff_model_fn():
”””Constructs a fully initialized model for use in federated averaging.”””
keras_model = create_original_fedavg_cnn_model(only_digits=True)
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metrics = [tf.keras.metrics.SparseCategoricalAccuracy()]
return tff.learning.from_keras_model(
keras_model,
loss=loss,
metrics=metrics,
input_spec=train_data.element_type_structure)
iterative_process = simple_fedavg_tff.build_federated_averaging_process(
tff_model_fn, server_optimizer_fn, client_optimizer_fn)
server_state = iterative_process.initialize()
# Keras model that represents the global model we'll evaluate test data on.
keras_model = create_original_fedavg_cnn_model(only_digits=True)
for round_num in range(FLAGS.total_rounds):
sampled_clients = np.random.choice(
train_data.client_ids,
size=FLAGS.train_clients_per_round,
replace=False)
sampled_train_data = [
train_data.create_tf_dataset_for_client(client)
for client in sampled_clients
]
server_state, train_metrics = iterative_process.next(
server_state, sampled_train_data)
print(f'Round {round_num}')
print(f'\tTraining metrics: {train_metrics}')
if round_num % FLAGS.rounds_per_eval == 0:
server_state.model.assign_weights_to(keras_model)
accuracy = evaluate(keras_model, test_data)
print(f'\tValidation accuracy: {accuracy * 100.0:.2f}%')
if __name__ == '__main__':
app.run(main) |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
×
|

 发表于 2023-6-7 17:56:40
发表于 2023-6-7 17:56:40
 变色卡
变色卡