这篇文章斗劲了Copilot和Codeium,它们在使用场景和预算方面存在很大差异。如果您不介意付出每年100美元或者不需要在在线笔记软件或Web IDE(如Gitpod)等平台上使用,那么Copilot可能更适合您。虽然其他选项也很有潜力,但目前看来还不及Copilot。
我们还没有评估这些产物的增长潜力。Copilot已经存在了一年半,由OpenAI和Github共同推出,这两家公司可能在持续的开发方面没有对齐的动机。另一方面,Codeium在几个月内就赶上了,这主要归功于我们的完全垂直整合,可以跨整个仓库做出决策优化,从而实现了非常流畅的体验。与Copilot分歧,我们积极听取并采纳用户反馈,并成立了一个活跃的Discord社区。值得一提的是,自从发布该文章以来,Codeium还推出了自然语言搜索功能,更多功能即将推出。而Copilot的项目,如Copilot for X,还未从Beta版转入出产。
总之,这种评估方式本质上是有限的。虽然它可能在必然程度上改变您的不雅概念,但我们认为,只有亲自测验考试Codeium才能确信它是并将继续成为适用于您的情况的#1 IDE AI动力代码辅助东西。请记住,我们是免费的,安装时间不超过2分钟,因此请在我们的Web Playground中测验考试,无需任何安装。如果您喜欢我们的内容,请点击下面的按钮获取Codeium。
七、如何选择

 发表于 2023-5-20 20:06:58
发表于 2023-5-20 20:06:58


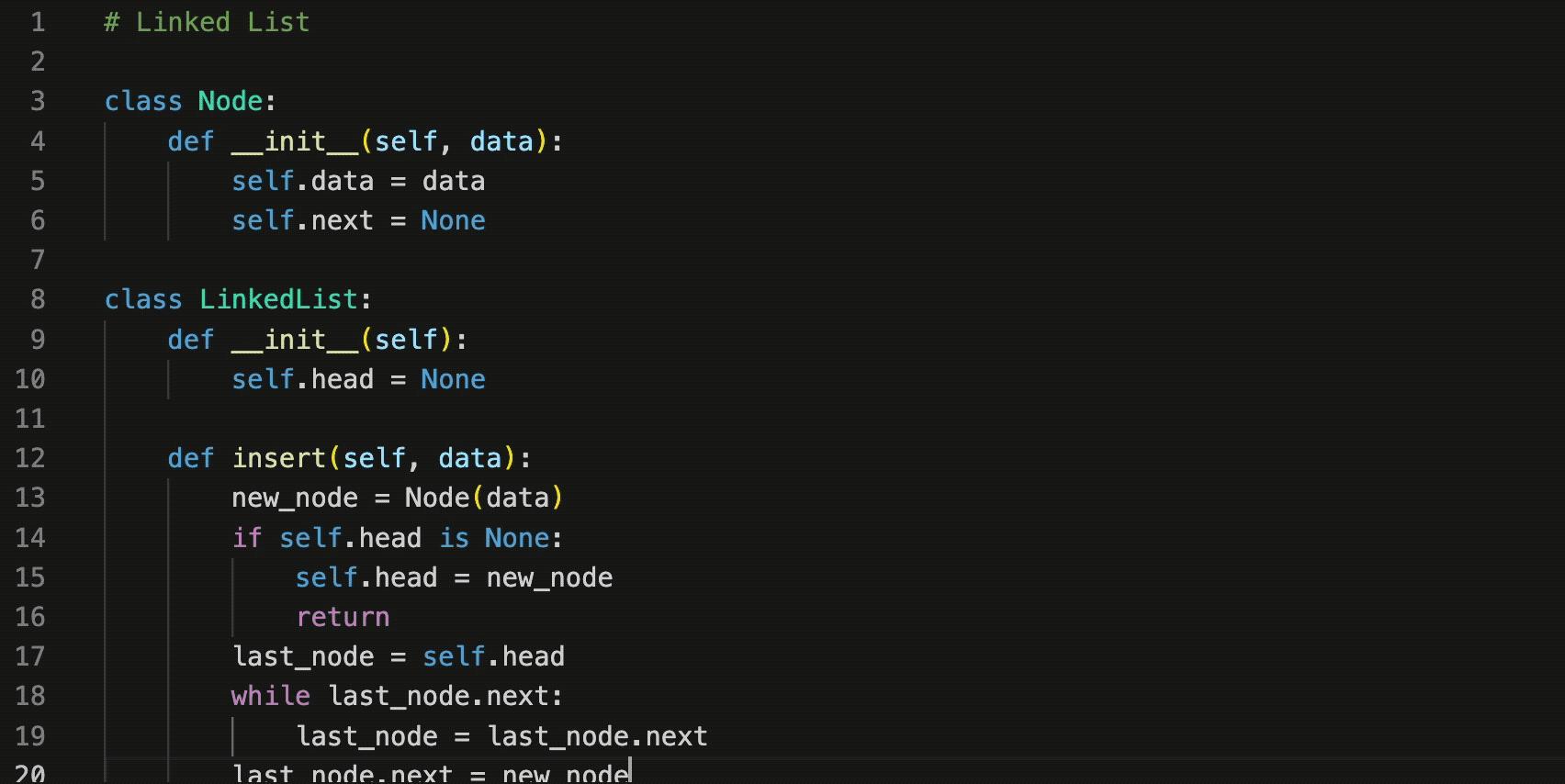
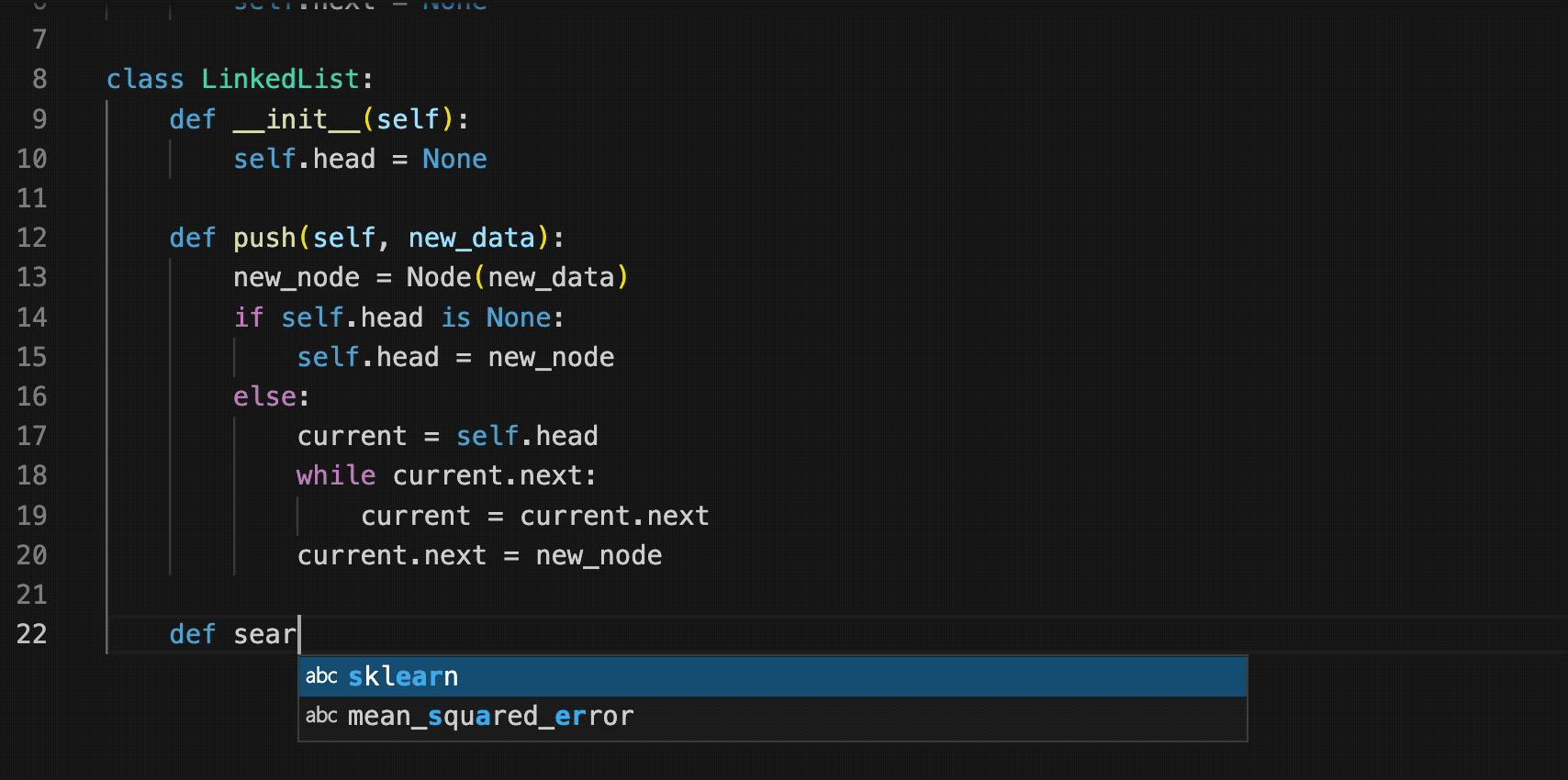

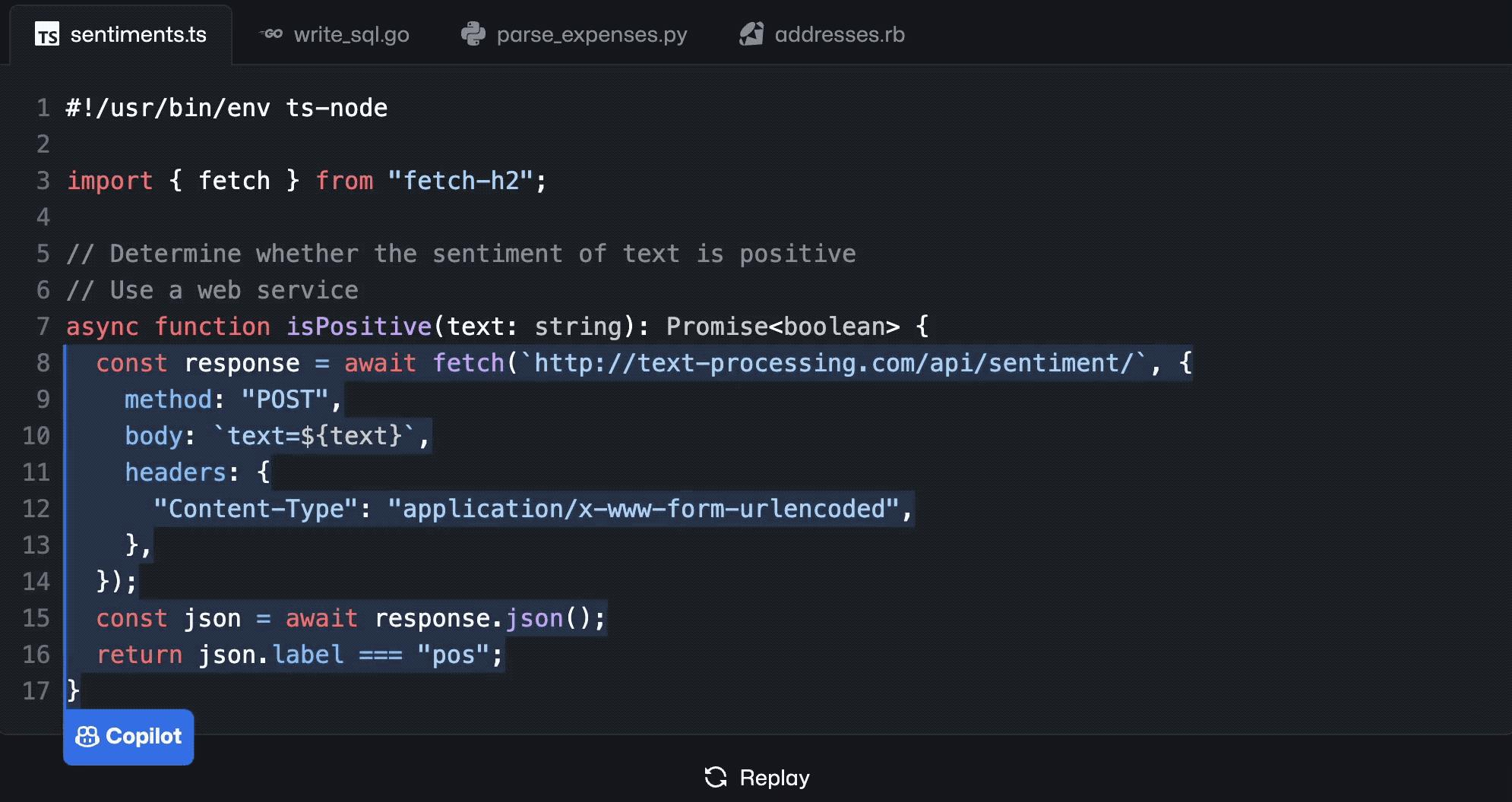
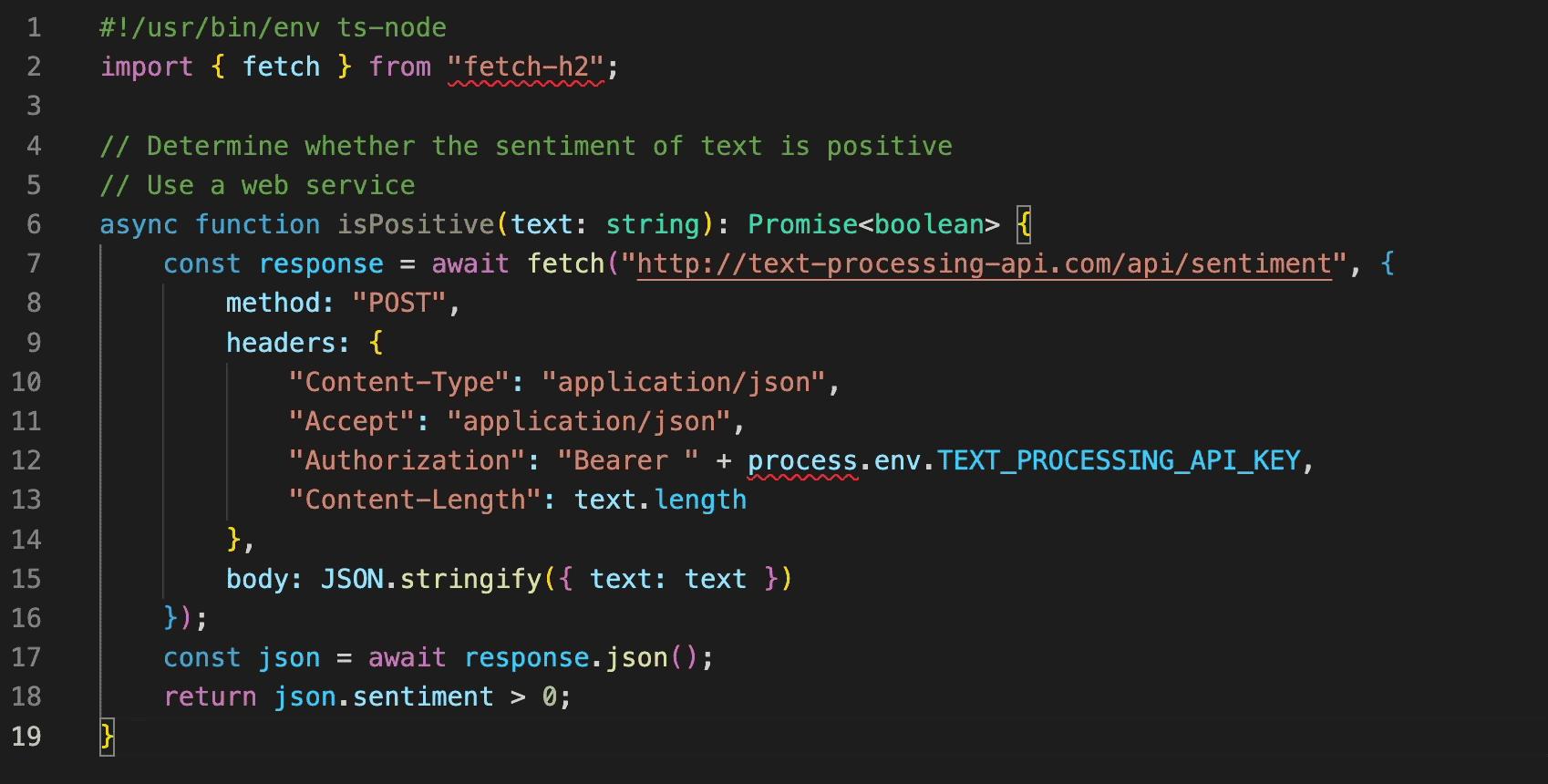
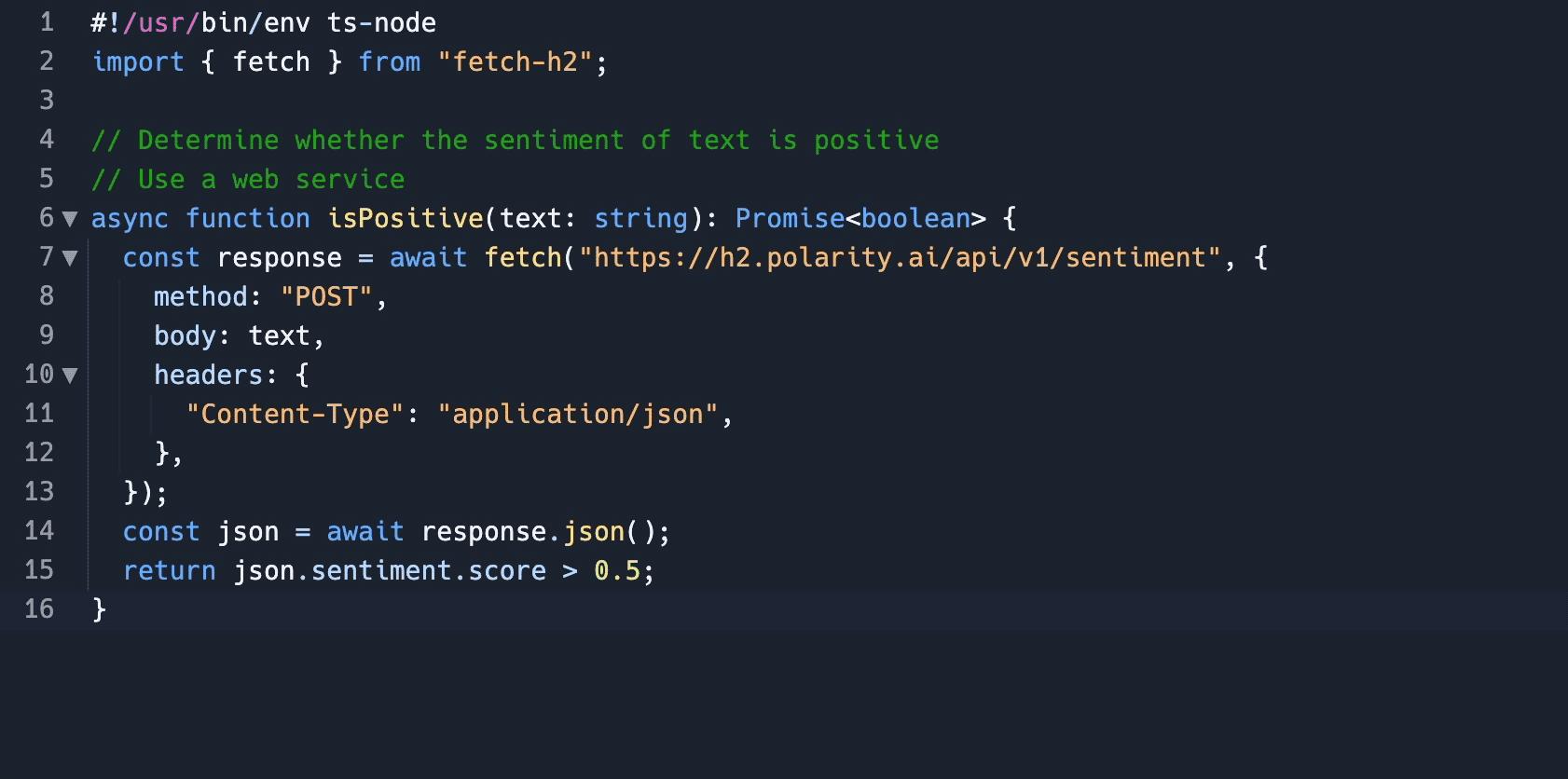
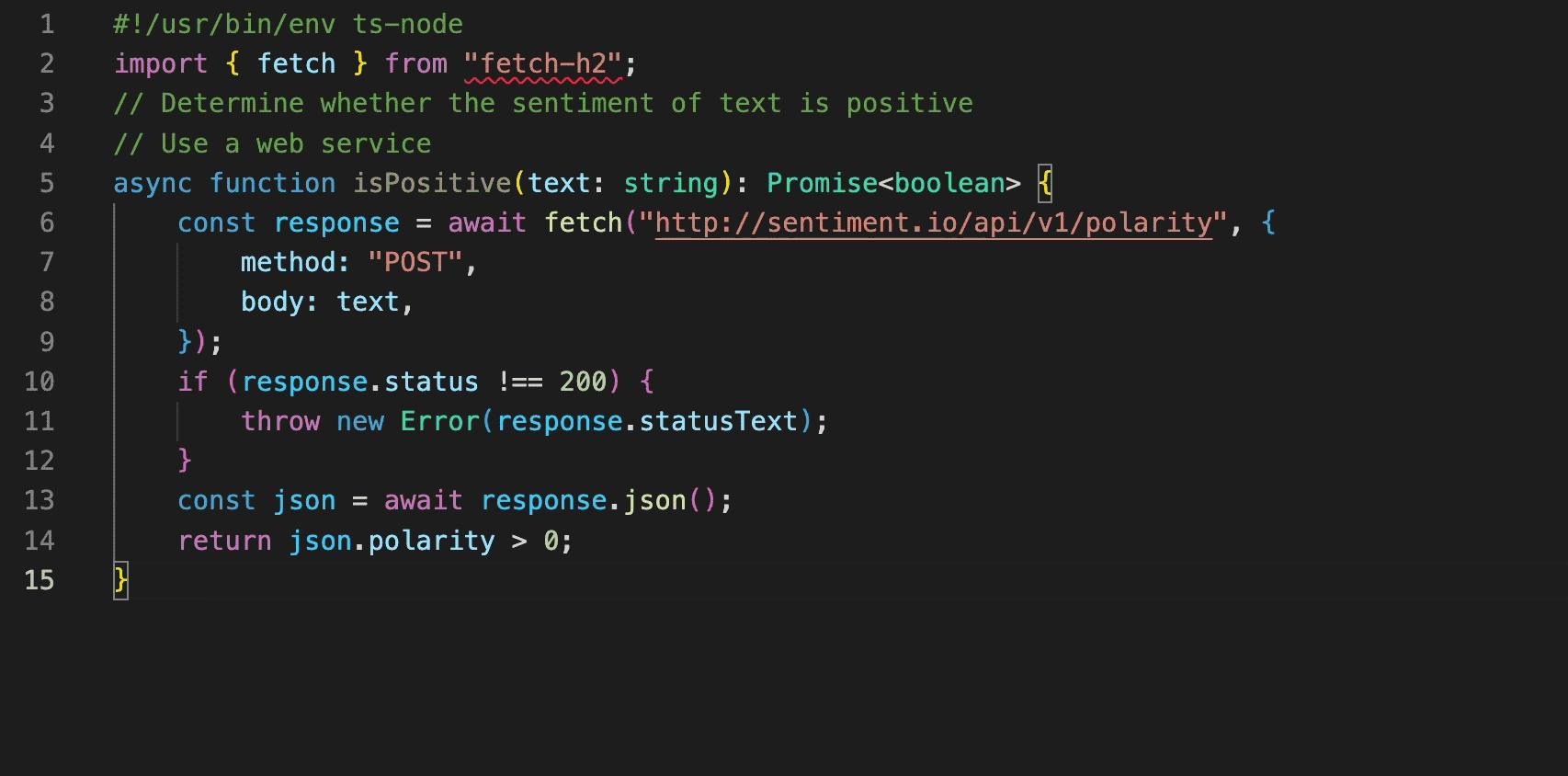
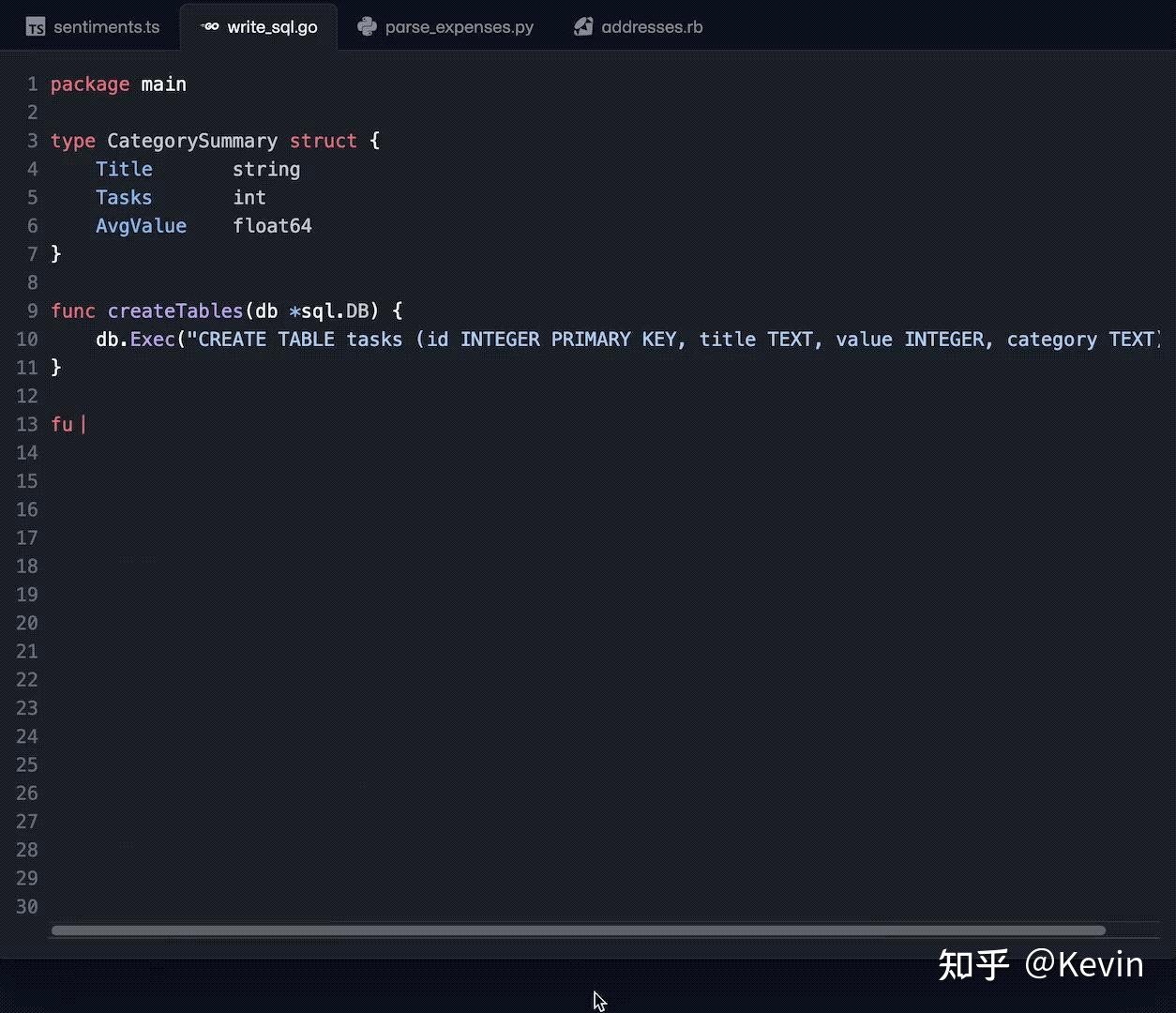
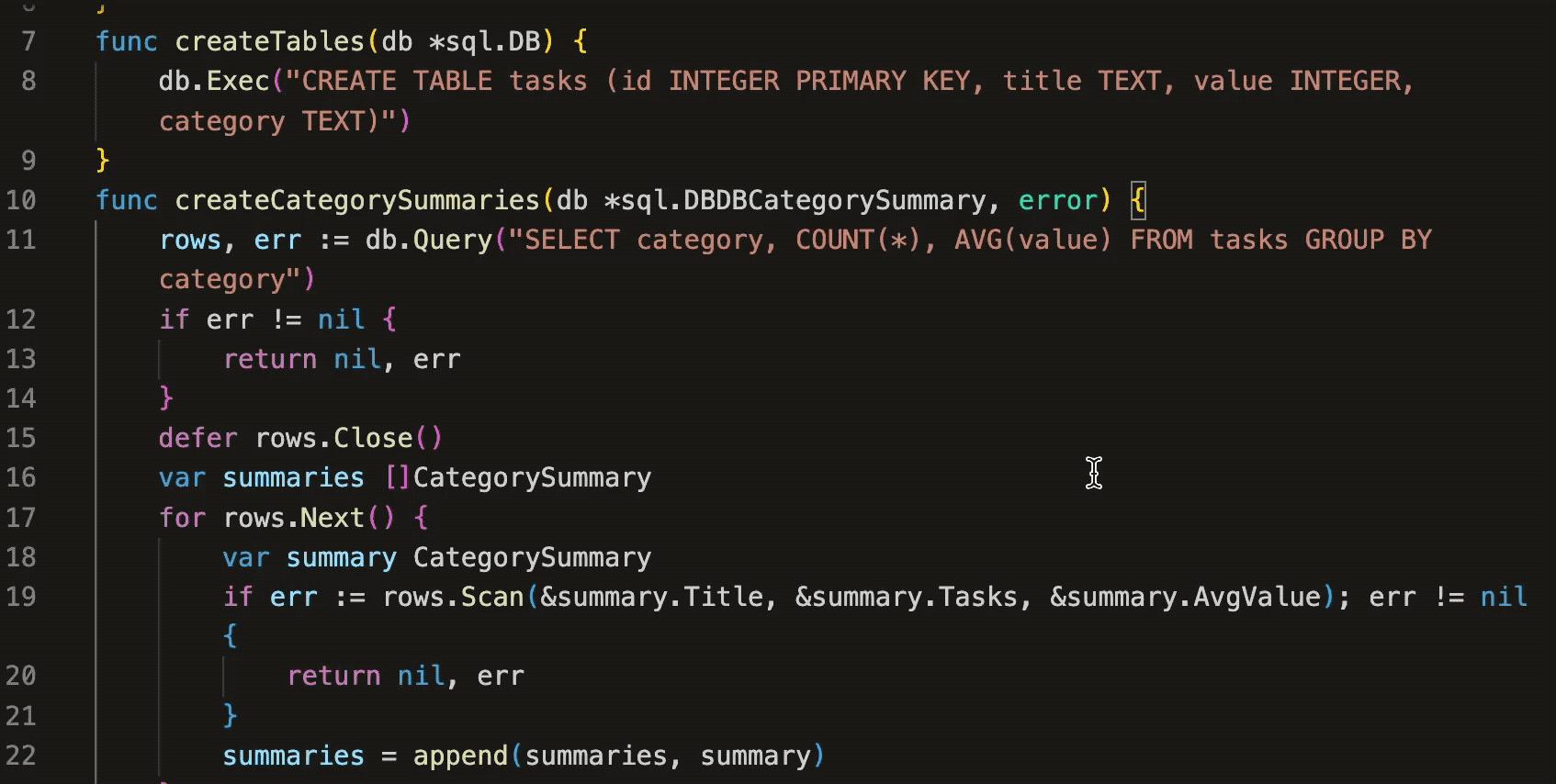
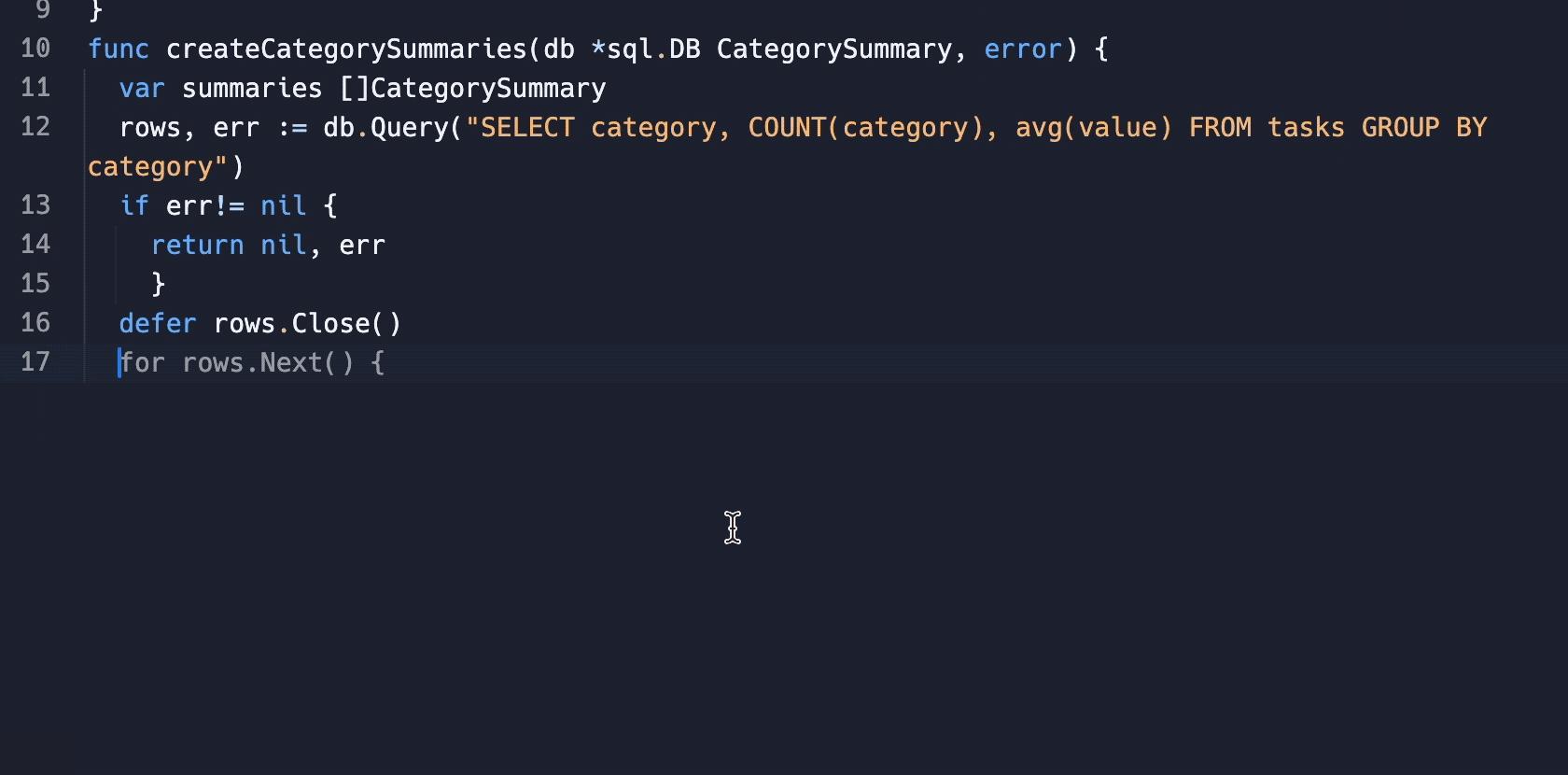
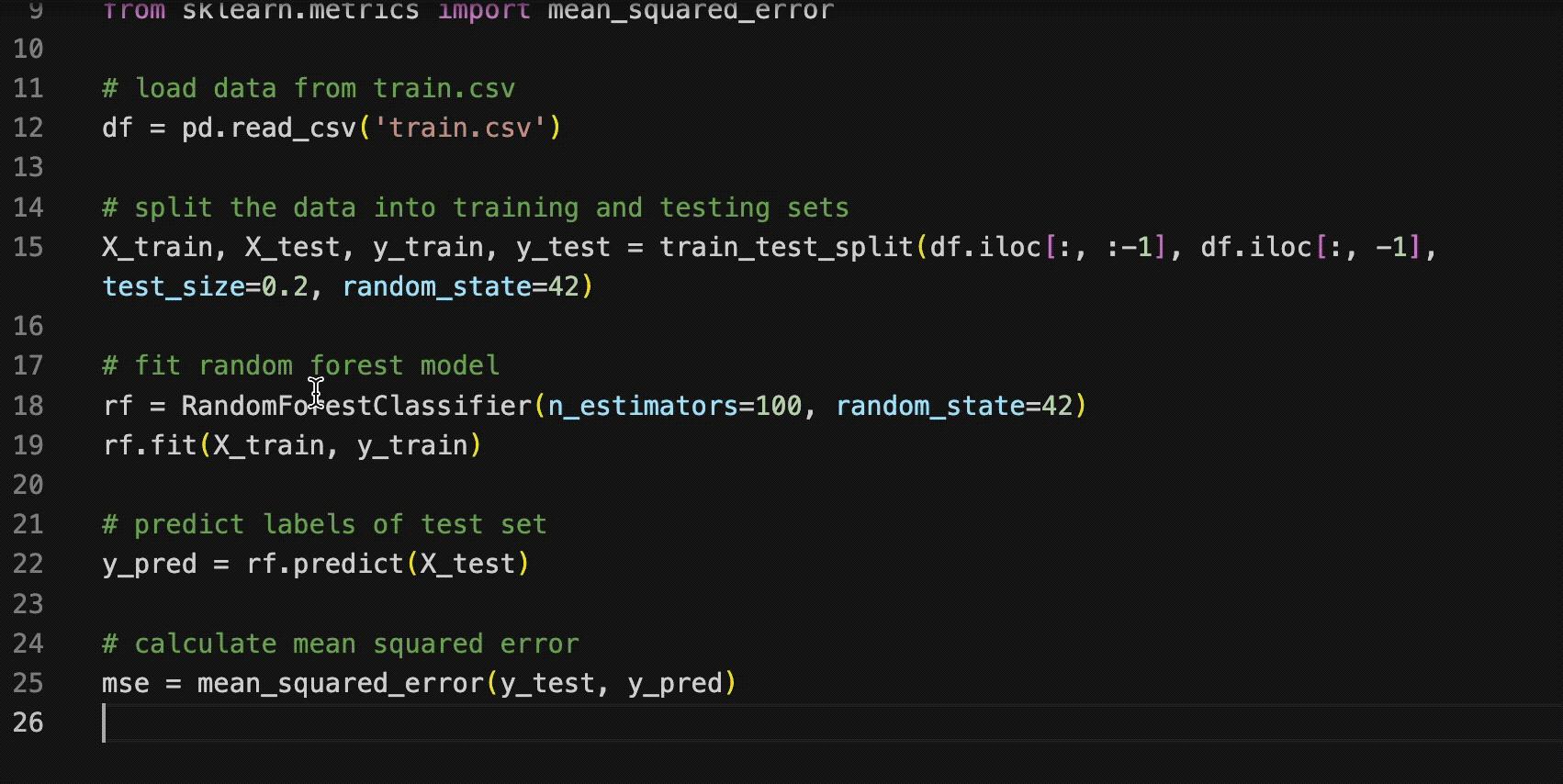
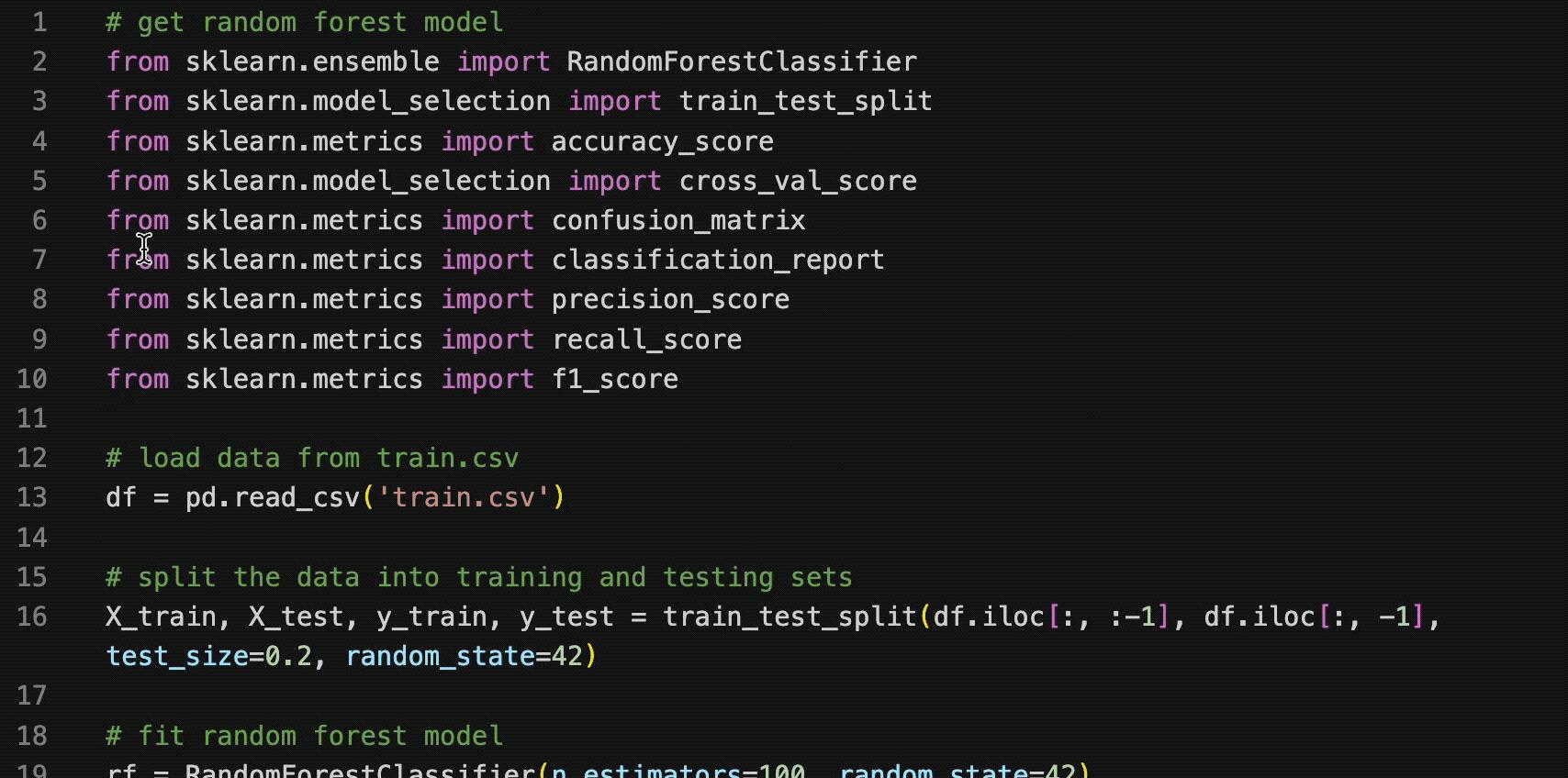
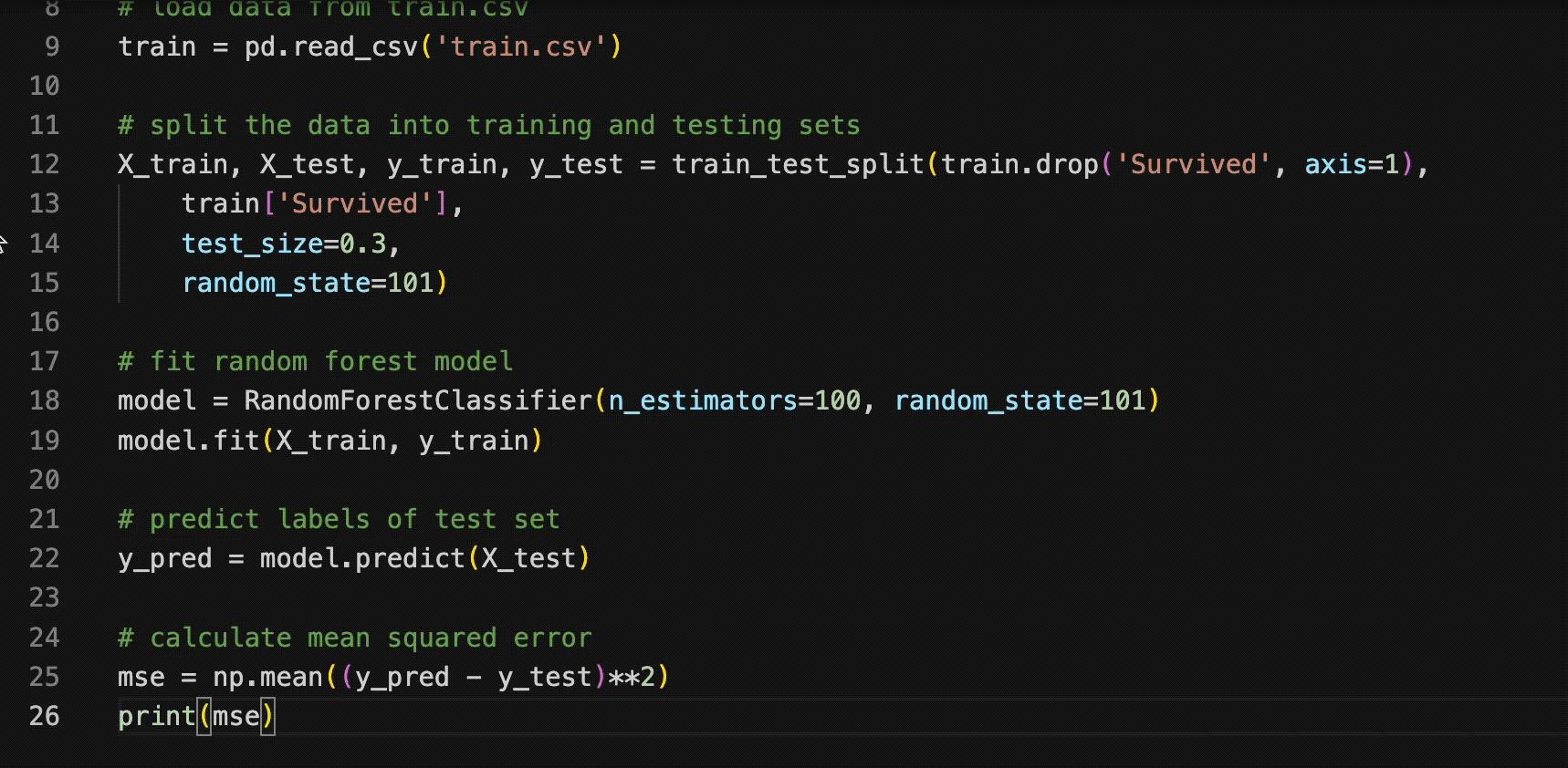
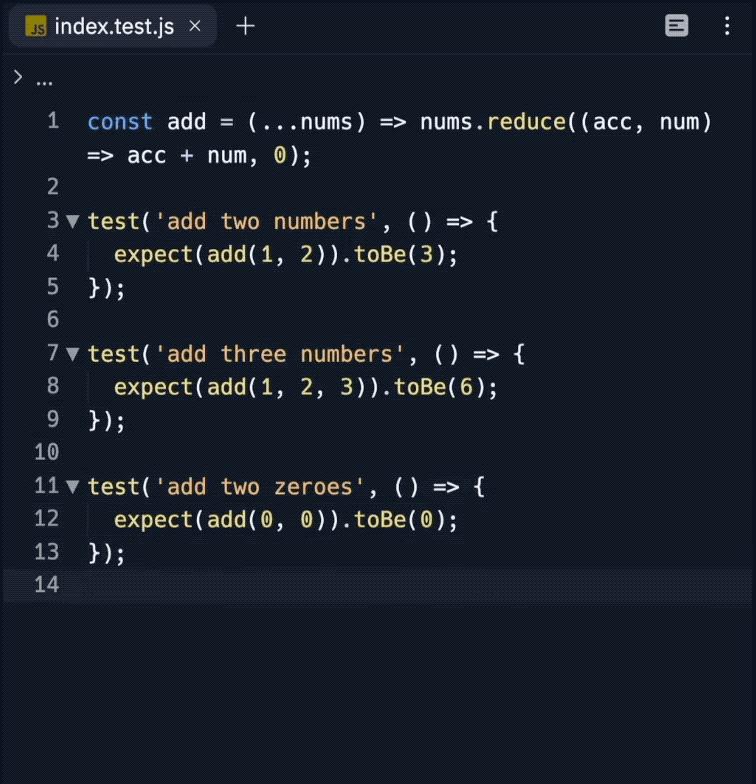
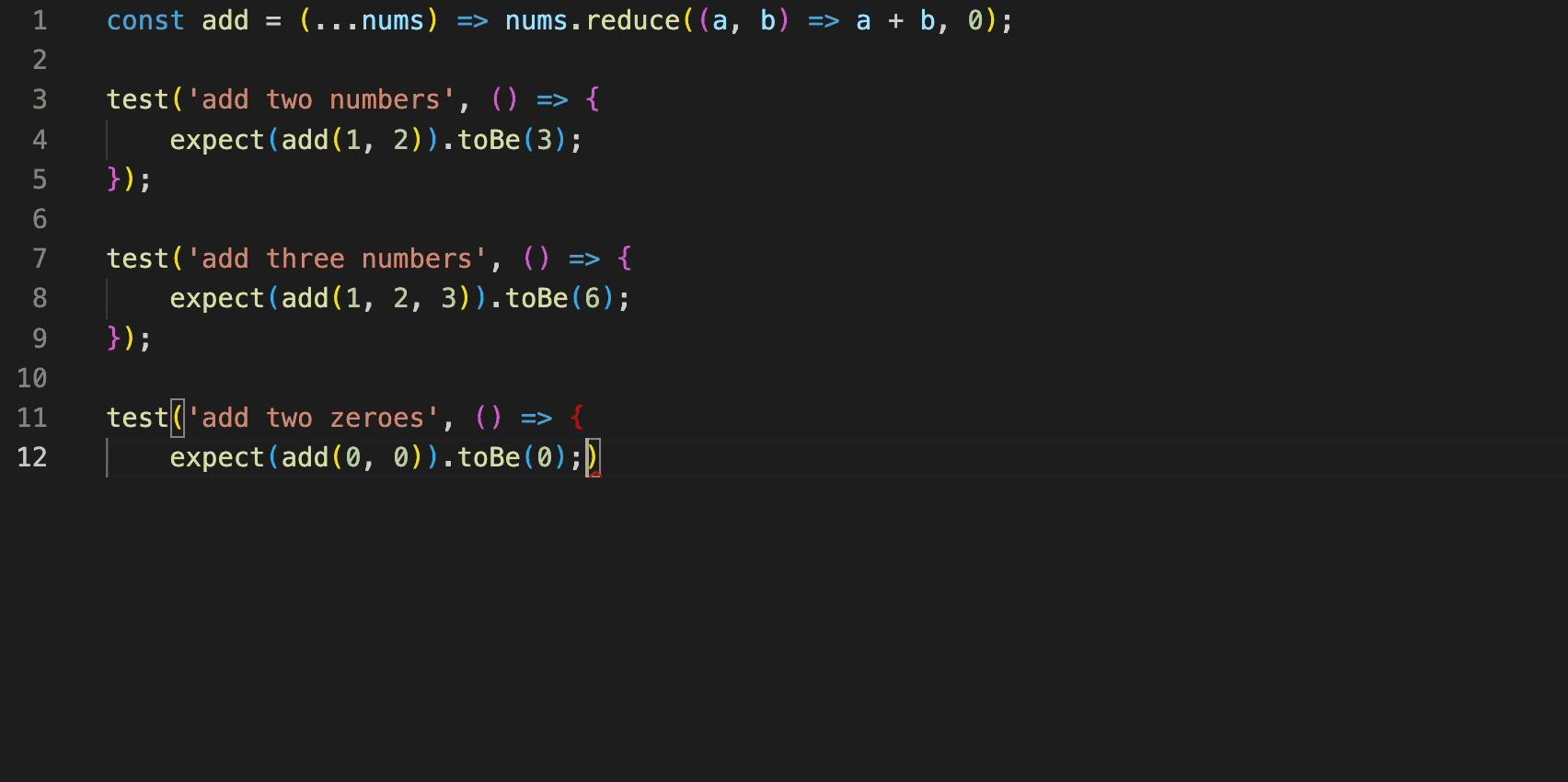
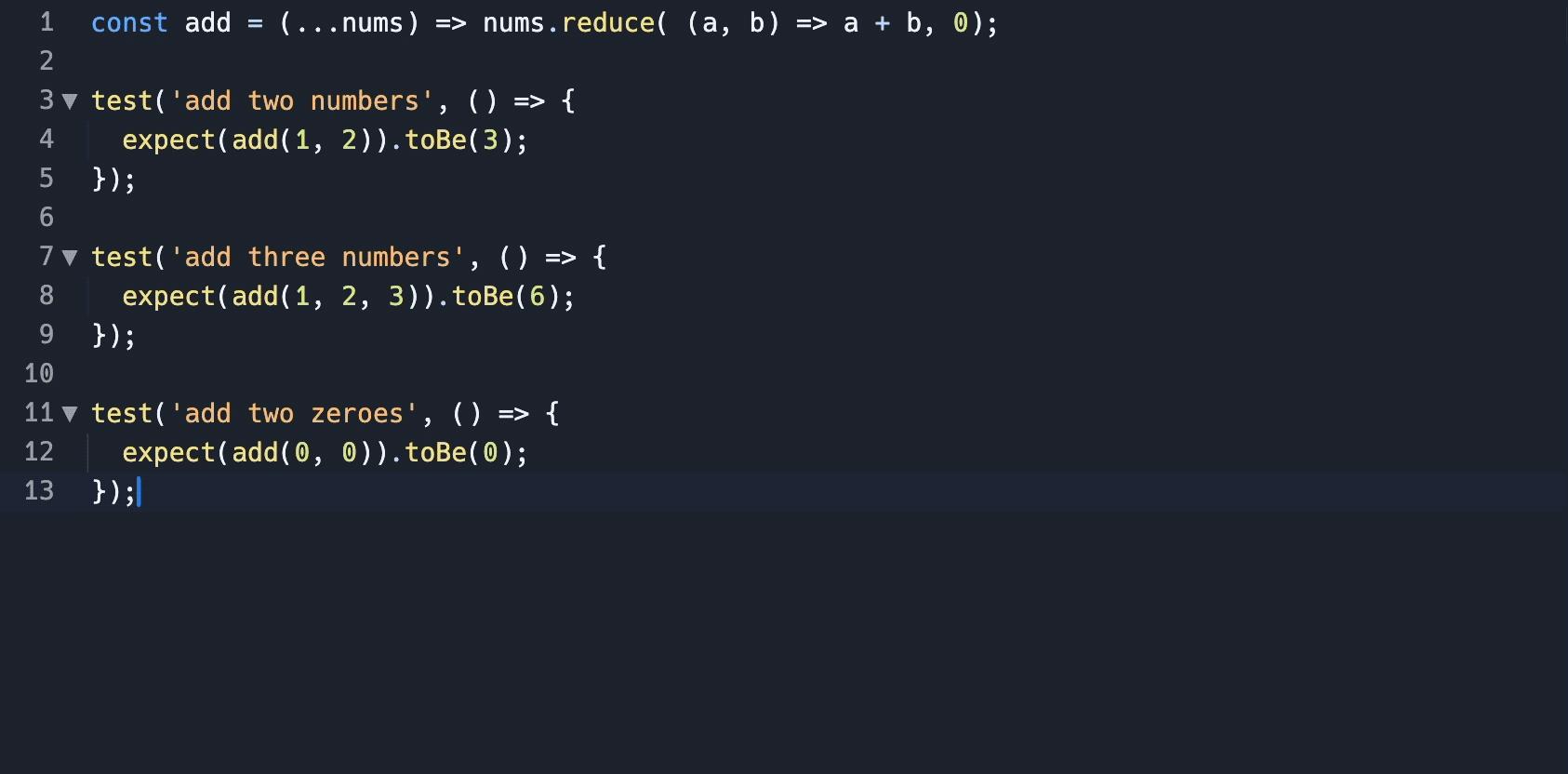


 变色卡
变色卡