1
0
23
新手上路
使用道具 举报
2
3
8
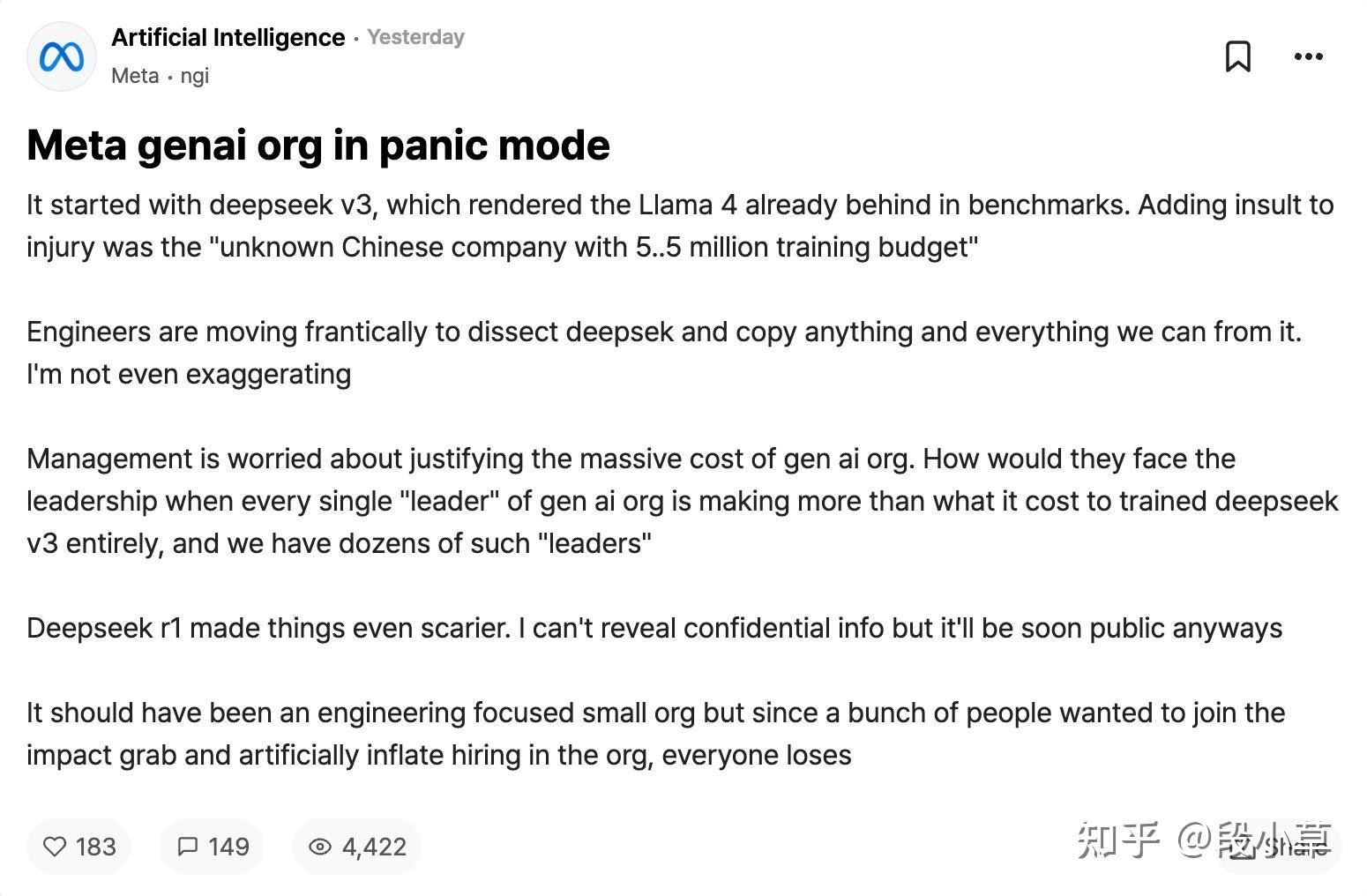
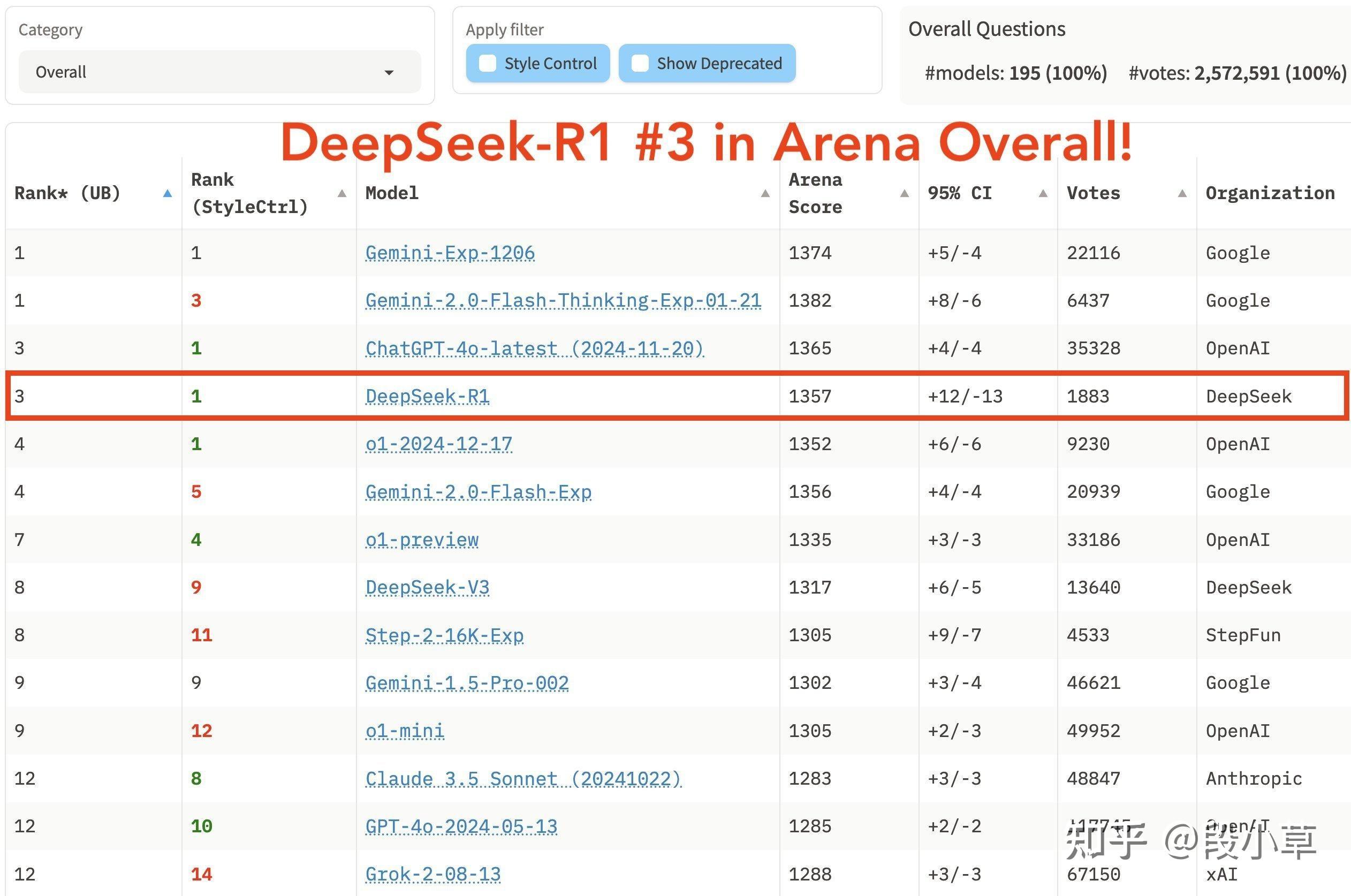
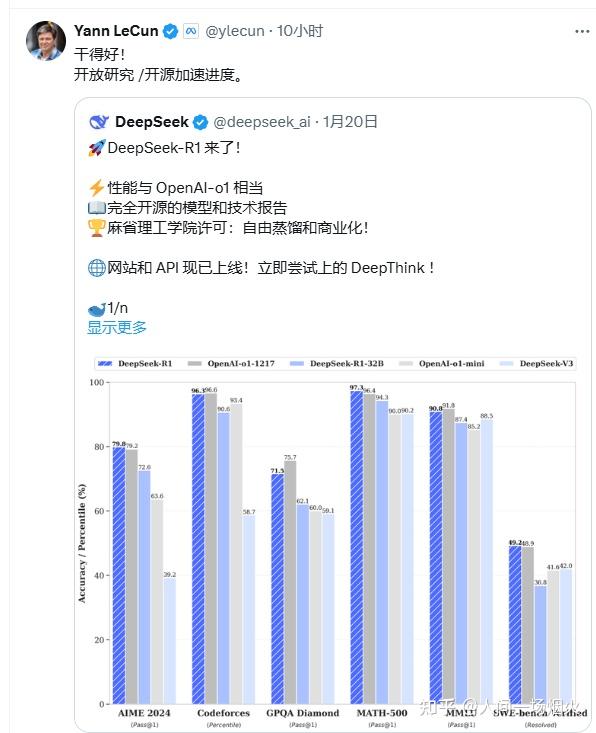
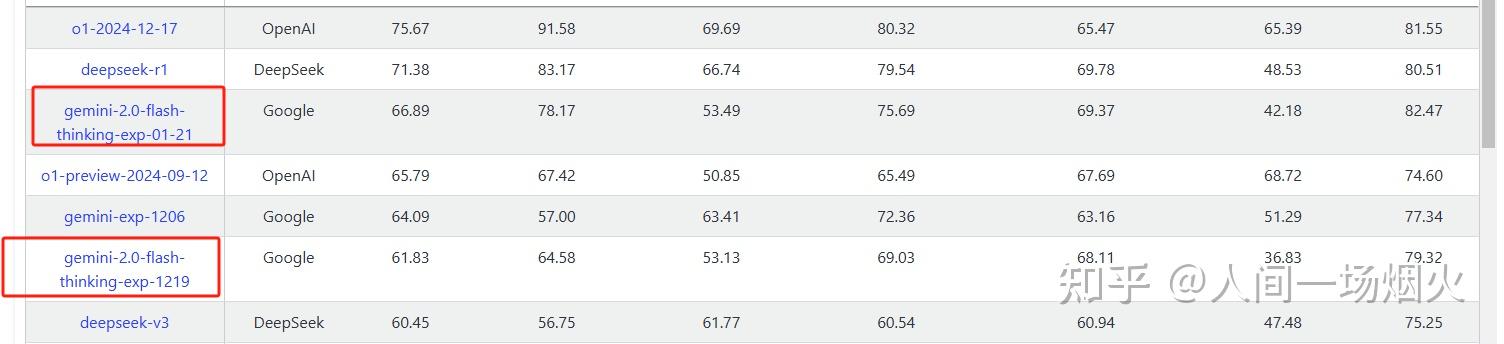
对于那些看到 DeepSeek 表现出色并认为「中国在人工智能上超越了美国」的人,你们理解错了。正确的理解应该是: 「开源模型正在超越私有模型。」 DeepSeek 受益于开放研究和开源(例如 Meta 的 PyTorch 和 Llama)。他们提出了新想法,并在他人的基础上进行构建。因为他们的工作是公开发布并开源的,每个人都能从中获益。 这就是开放研究和开源的力量。
DeepSeek V3 总训练成本为 278.8 万 H800 GPU 小时,仅 557.6 万美元。
您需要 登录 才可以下载或查看,没有账号?立即注册
4
10
6
16
19
本版积分规则 发表回复 回帖后跳转到最后一页
Archiver|手机版|小黑屋|T9AI - 深度人工智能平台 ( 沪ICP备2023010006号 )
GMT+8, 2025-7-19 01:42 , Processed in 0.051815 second(s), 20 queries .
Powered by Discuz! X3.5
© 2001-2025 Discuz! Team.

 发表于 2025-7-8 17:55:35
发表于 2025-7-8 17:55:35
 变色卡
变色卡