|
|
 发表于 2023-12-20 11:00:34
|
显示全部楼层
发表于 2023-12-20 11:00:34
|
显示全部楼层
人工智能的浪潮正在席卷全球,诸多词汇时刻萦绕在我们耳边:人工智能(Artificial Intelligence)、机器学习(Machine Learning)、深度学习(Deep Learning)。不少人对这些高频词汇的含义及其背后的关系总是似懂非懂、一知半解。
为了帮助大家更好地理解人工智能,这篇文章用最简单的语言解释了这些词汇的含义,理清它们之间的关系,希望对刚入门的同行有所帮助。
图一 人工智能的应用
人工智能:从概念提出到走向繁荣
1956年,几个计算机科学家相聚在达特茅斯会议,提出了“人工智能”的概念,梦想着用当时刚刚出现的计算机来构造复杂的、拥有与人类智慧同样本质特性的机器。其后,人工智能就一直萦绕于人们的脑海之中,并在科研实验室中慢慢孵化。之后的几十年,人工智能一直在两极反转,或被称作人类文明耀眼未来的预言,或被当成技术疯子的狂想扔到垃圾堆里。直到2012年之前,这两种声音还在同时存在。
2012年以后,得益于数据量的上涨、运算力的提升和机器学习新算法(深度学习)的出现,人工智能开始大爆发。据领英近日发布的《全球AI领域人才报告》显示,截至2017年一季度,基于领英平台的全球AI(人工智能)领域技术人才数量超过190万,仅国内人工智能人才缺口达到500多万。
人工智能的研究领域也在不断扩大,图二展示了人工智能研究的各个分支,包括专家系统、机器学习、进化计算、模糊逻辑、计算机视觉、自然语言处理、推荐系统等。
图二 人工智能研究分支
但目前的科研工作都集中在弱人工智能这部分,并很有希望在近期取得重大突破,电影里的人工智能多半都是在描绘强人工智能,而这部分在目前的现实世界里难以真正实现(通常将人工智能分为弱人工智能和强人工智能,前者让机器具备观察和感知的能力,可以做到一定程度的理解和推理,而强人工智能让机器获得自适应能力,解决一些之前没有遇到过的问题)。
弱人工智能有希望取得突破,是如何实现的,“智能”又从何而来呢?这主要归功于一种实现人工智能的方法——机器学习。
机器学习:一种实现人工智能的方法
机器学习最基本的做法,是使用算法来解析数据、从中学习,然后对真实世界中的事件做出决策和预测。与传统的为解决特定任务、硬编码的软件程序不同,机器学习是用大量的数据来“训练”,通过各种算法从数据中学习如何完成任务。
举个简单的例子,当我们浏览网上商城时,经常会出现商品推荐的信息。这是商城根据你往期的购物记录和冗长的收藏清单,识别出这其中哪些是你真正感兴趣,并且愿意购买的产品。这样的决策模型,可以帮助商城为客户提供建议并鼓励产品消费。
机器学习直接来源于早期的人工智能领域,传统的算法包括决策树、聚类、贝叶斯分类、支持向量机、EM、Adaboost等等。从学习方法上来分,机器学习算法可以分为监督学习(如分类问题)、无监督学习(如聚类问题)、半监督学习、集成学习、深度学习和强化学习。
传统的机器学习算法在指纹识别、基于Haar的人脸检测、基于HoG特征的物体检测等领域的应用基本达到了商业化的要求或者特定场景的商业化水平,但每前进一步都异常艰难,直到深度学习算法的出现。
深度学习:一种实现机器学习的技术
深度学习本来并不是一种独立的学习方法,其本身也会用到有监督和无监督的学习方法来训练深度神经网络。但由于近几年该领域发展迅猛,一些特有的学习手段相继被提出(如残差网络),因此越来越多的人将其单独看作一种学习的方法。
最初的深度学习是利用深度神经网络来解决特征表达的一种学习过程。深度神经网络本身并不是一个全新的概念,可大致理解为包含多个隐含层的神经网络结构。为了提高深层神经网络的训练效果,人们对神经元的连接方法和激活函数等方面做出相应的调整。其实有不少想法早年间也曾有过,但由于当时训练数据量不足、计算能力落后,因此最终的效果不尽如人意。
深度学习摧枯拉朽般地实现了各种任务,使得似乎所有的机器辅助功能都变为可能。无人驾驶汽车,预防性医疗保健,甚至是更好的电影推荐,都近在眼前,或者即将实现。
三者的区别和联系
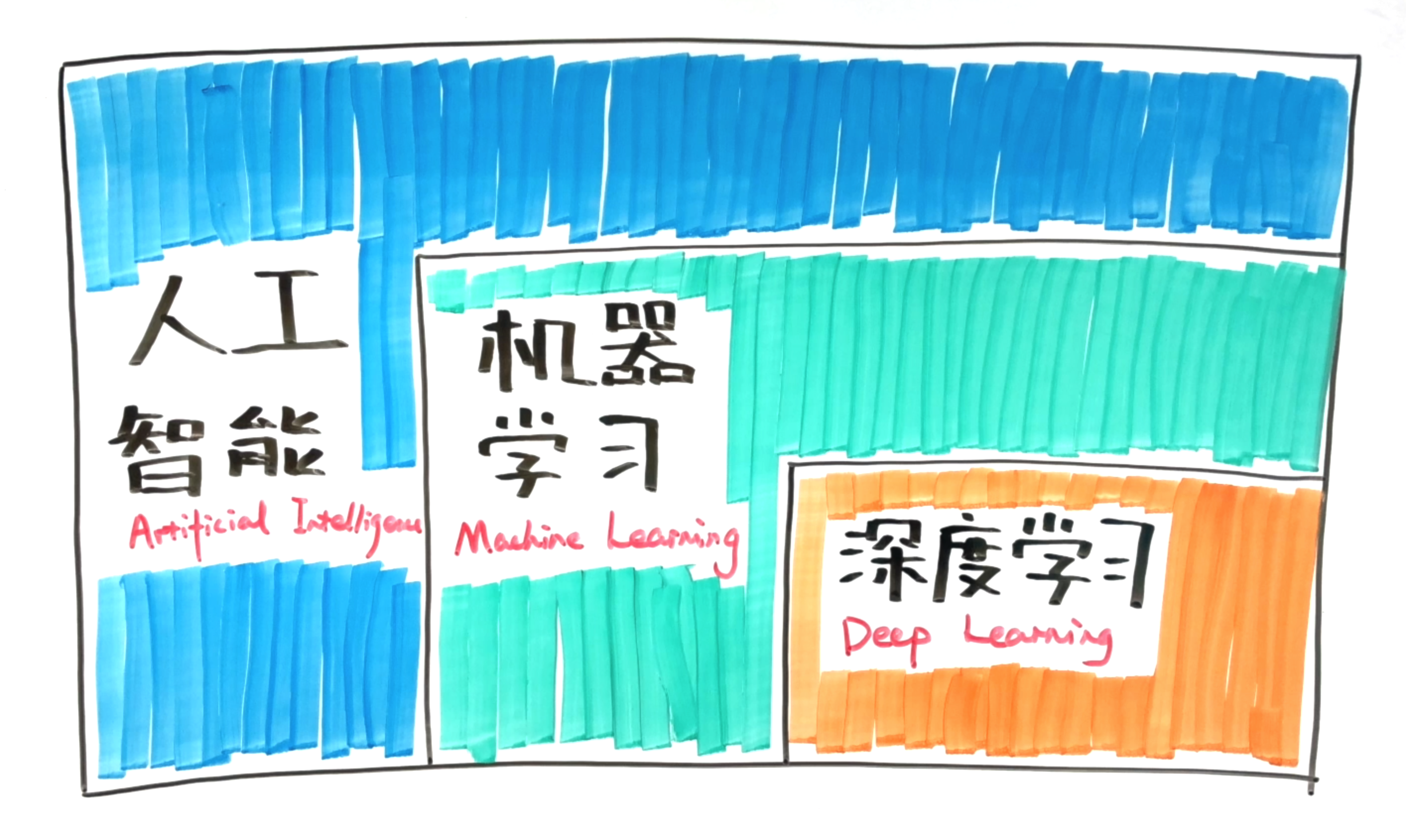
机器学习是一种实现人工智能的方法,深度学习是一种实现机器学习的技术。我们就用最简单的方法——同心圆,可视化地展现出它们三者的关系。
图三 三者关系示意图
目前,业界有一种错误的较为普遍的意识,即“深度学习最终可能会淘汰掉其他所有机器学习算法”。这种意识的产生主要是因为,当下深度学习在计算机视觉、自然语言处理领域的应用远超过传统的机器学习方法,并且媒体对深度学习进行了大肆夸大的报道。
深度学习,作为目前最热的机器学习方法,但并不意味着是机器学习的终点。起码目前存在以下问题:
1. 深度学习模型需要大量的训练数据,才能展现出神奇的效果,但现实生活中往往会遇到小样本问题,此时深度学习方法无法入手,传统的机器学习方法就可以处理;
2. 有些领域,采用传统的简单的机器学习方法,可以很好地解决了,没必要非得用复杂的深度学习方法;
3. 深度学习的思想,来源于人脑的启发,但绝不是人脑的模拟,举个例子,给一个三四岁的小孩看一辆自行车之后,再见到哪怕外观完全不同的自行车,小孩也十有八九能做出那是一辆自行车的判断,也就是说,人类的学习过程往往不需要大规模的训练数据,而现在的深度学习方法显然不是对人脑的模拟。
深度学习大佬 Yoshua Bengio 在 Quora 上回答一个类似的问题时,有一段话讲得特别好,这里引用一下,以回答上述问题:Science is NOT a battle, it is a collaboration. We all build on each other's ideas. Science is an act of love, not war. Love for the beauty in the world that surrounds us and love to share and build something together. That makes science a highly satisfying activity, emotionally speaking!
结合机器学习2000年以来的发展,再来看Bengio的这段话,深有感触。进入21世纪,纵观机器学习发展历程,研究热点可以简单总结为2000-2006年的流形学习、2006年-2011年的稀疏学习、2012年至今的深度学习。未来哪种机器学习算法会成为热点呢?深度学习三大巨头之一吴恩达曾表示,“在继深度学习之后,迁移学习将引领下一波机器学习技术”。但最终机器学习的下一个热点是什么,谁又能说得准呢。
近期,深蓝学院推出『深度学习:从理论到实践』在线课程,将从基础的数学模型以及算法实现出发,详细讲解CNN、 RNN、 LSTM等常见的深度神经网络模型,以及在计算机视觉、自然语言处理等领域经典任务中的应用。详情如下:
深度学习理论与实践 - 深蓝学院 - 专注人工智能的在线教育<hr/>深蓝学院(https://www.shenlanxueyuan.com/)是专注于人工智能的在线教育平台,致力于构建前沿科技课程培养体系的业界标准,涵盖机器学习、计算机视觉、智能语音、智能机器人等领域。 |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
×
|

 变色卡
变色卡