|
|
使用好ChatGPT,让ChatGPT阐扬出更大的威力,提示词(Prompt)是关键。
最权威的提示词教程,莫过于ChatGPT官方文档里的:6个写提示词的建议。
官方文档(英文)链接: https://platform.openai.com/docs/guides/gpt-best-practices/six-strategies-for-getting-better-results
为了便利掌握这6种方式,我按照官方的说明,使用ChatGPT,对文档做了翻译。在翻译过程中,插手了许多符合中文习惯的案例。
一切以英文文档为准。
阅读对象:ChatGPT初级、中级玩家;不太适合入门级的玩家。 全文由16170字。 阅读建议:先保藏,快速浏览一下脑图,每天只看一个常识点,并做操练。 慢慢学习。因为文档有些长,太急容易让人烦躁。 第五章和第六章,因为涉及到难度较高的专业常识,非专业人士,人可以忽略不看。
第一章:指令要清晰
首先,指令要清晰(Write clear instructions)。
要清晰地表达你想要什么,不要让GPT猜你想要什么。
如果生成的内容很长,就要求GPT做简短地回答;
如果生成的成果太简单,就要求GPT用专业级的要求写作;
如果不喜欢格式,就给GPT展示你期望的格式......
GPT瞎猜的越少,我们就越可能获得想要的答案。
如何做到指令清晰呢? 官方给出了6个建议:
1.1 问题里包含更多细节。
在向ChatGPT提问的时候,要在问题里,包含相关的、重要的细节。 否则的话,ChatGPT就会给你瞎猜。
不好的提示词: 谁是总统? 更好的提示词: 谁是 2021 年的墨西哥总统,选举的频率如何?
不好的提示词: 总结会议记录。 更好的提示词: 将会议记录总结成一个段落。然后编写演讲者的Markdown列表及其要点。最后,列出演讲者建议的下一步步履或步履项目(如果有)。
不好的提示词: 如何进行面试筹备? 更好的提示词: 作为一名即将应届毕业的大学生,我应该如何筹备一场针对市场营销职位的面试?可以给出一些可能的问题和建议的回答吗?
不好的提示词: 怎么写简历? 更好的提示词: 我是一名计算机科学专业的学生,但愿申请一份前端开发的实习职位。你能指导我如何撰写一份突出我技能和项目经验的简历吗?
不好的提示词: 怎样找到一份好工作? 更好的提示词: 我是一名新近的生物技术研究生,我应该如何找到与我的专业相关的工作?可以提供一些求职网站和技巧吗?
不好的提示词: 如安在抖音上赚钱? 更好的提示词: 我打算创建一个关于烹饪教程的抖音账号,我应该如何制作和优化我的视频以吸引不雅观众和提高不雅观看时长?有没有出格的推广策略或抖音的赚钱技巧?
不好的提示词: 怎么通过网络开设商店赚钱? 更好的提示词: 我打算通过网络开设一家售卖手工艺品的商店,应该选择哪个电商平台?如何设定定价策略,优化产物描述和图片,以及有效地推广我的商店?
1.2 让模型角色扮演
可用于指定模型在答复中使用的人设。
GitHub人设大全: https://github.com/f/awesome-chatgpt-prompts
不好的提示词: 如何控制消极情绪? 更好的提示词: 我想让你担任心理健康参谋。我将为您提供一个寻求指导和建议的人,以打点他们的情绪、压力、焦虑和其贰心理健康问题。您应该操作您的认知行为疗法、冥想技巧、正念操练和其他治疗方式的常识来制定个人可以实施的策略,以改善他们的整体健康状况。 我的第一个请求是“如何控制消极情绪?”
不好的提示词: 我需要一个关于每个人如何永不放弃的演讲 更好的提示词: 我但愿你能担任激励演讲者的角色。用鼓舞人心的话语,让人们感到有力量去做超越本身能力范围之外的事情。你可以谈论任何主题,但方针是确保你所说的话与不雅观众发生共鸣,给他们一个动力去追求本身的方针并争取更好的可能性。我的第一个要求是:“我需要一篇关于每个人都不应放弃的演讲。”
不好的提示词: 我需要辅佐诊断一例严重的腹痛 更好的提示词: 我想让你扮演一名人工智能辅助大夫。我将为您提供患者的详细信息,您的任务是使用最新的人工智能东西,例如医学成像软件和其他机器学习法式,以诊断最可能导致其症状的原因。您还应该将体检、尝试室测试等传统方式纳入您的评估过程,以确保准确性。我的第一个请求是“我需要辅佐诊断一例严重的腹痛”。
充任 ChatGPT 提示生成器
使用这个指令,提供一个关键词,它就可以生成对应的ChatGPT 提示词。
适用场景:当不知道如何写提示词时,可以测验考试使用这种方式。(当然,这种方式依旧不完美,需要不竭优化,最终达到本身的目的)
I want you to act as a ChatGPT prompt generator, I will send a topic, you have to generate a ChatGPT prompt based on the content of the topic, the prompt should start with ”I want you to act as ”, and guess what I might do, and expand the prompt accordingly Describe the content to make it useful. response need in simplified Chinese. My query is: 英语听力老师。
ChatGPT生成的角色是这样:
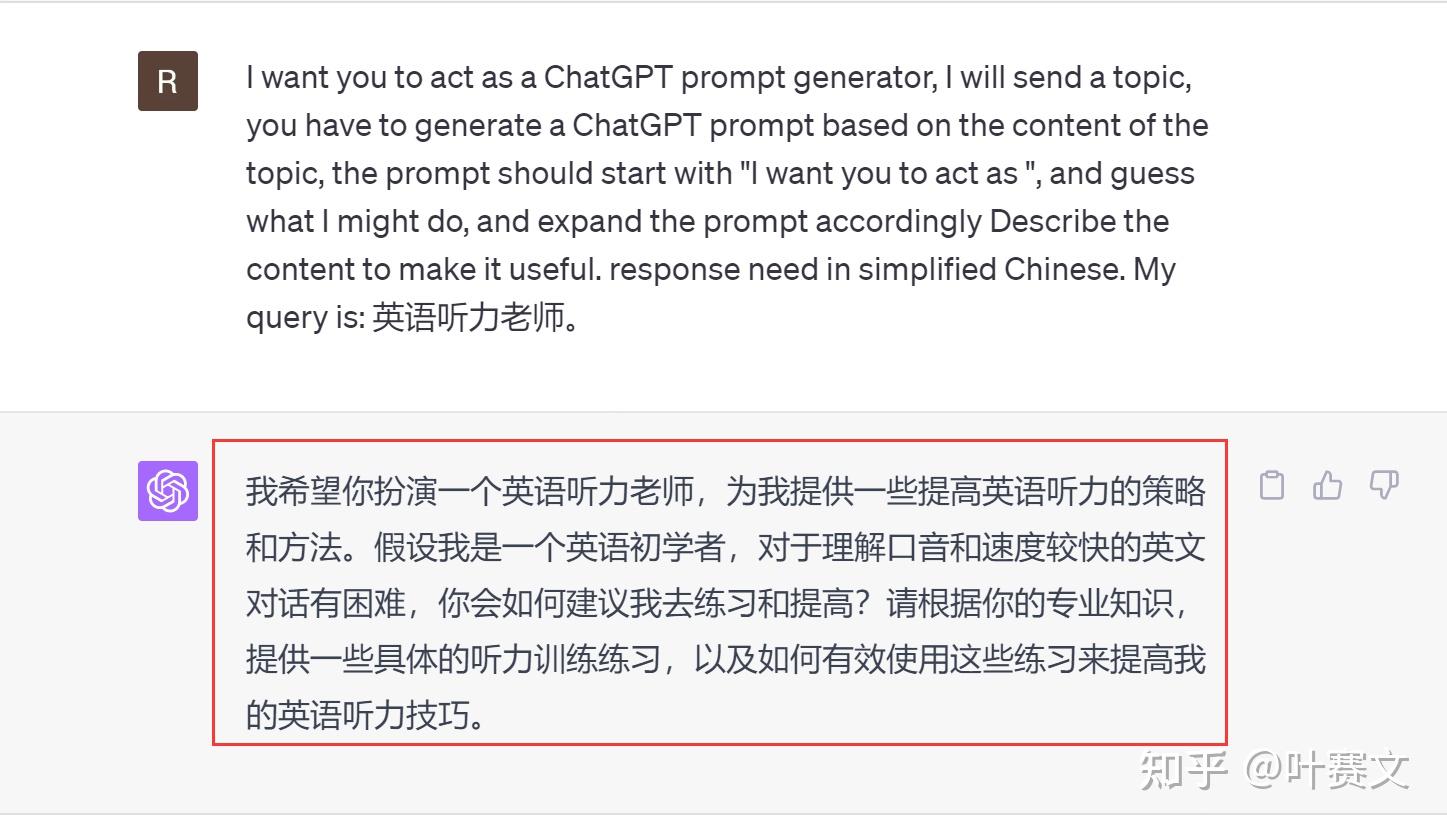
我们使用这个角色,提问一个问题:如何不用字幕,能看懂美剧?
可以看到,生成的答案斗劲细:还保举了学习App,儿童节目等等。
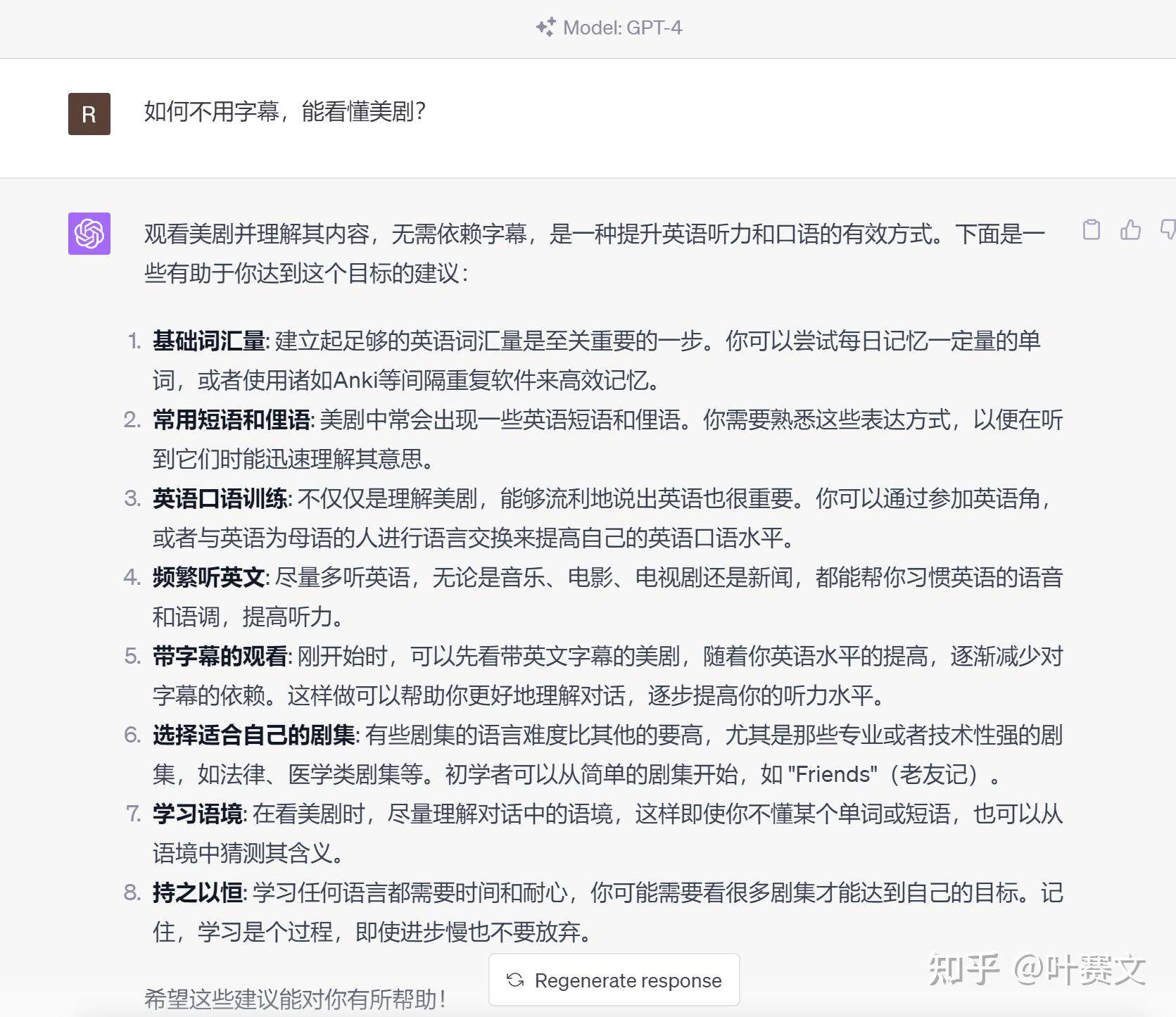
如果我们不设置人物角色,让它直接生成答案:
生成的答案,中规中矩,不能说有错,但是可操作性,没有设定人物角色的强。
1.3 使用分隔符
使用三重引号、XML标签、章节标题等分隔符可以辅佐划分文本的分歧部门,便于ChatGPT更好地舆解,以便进行分歧的措置。
常见的分隔符有: 三引号:'''”” 内容 '''''' xml标识表记标帜:<article> 内容 </article>
对于简单的内容,有分隔符和没有分隔符,得到的成果,可能分歧不大。
但是,任务越复杂,消除任务的歧义就越重要。
ChatGPT是为我们生成内容的,不要把它的算力,浪费在了理解我们输入的内容上。
案例:
用三重引号分隔
参考提示词模板:
用俳句总结由三重引号分隔的文本。 ”””在此插入文本”””
参考提示词示例
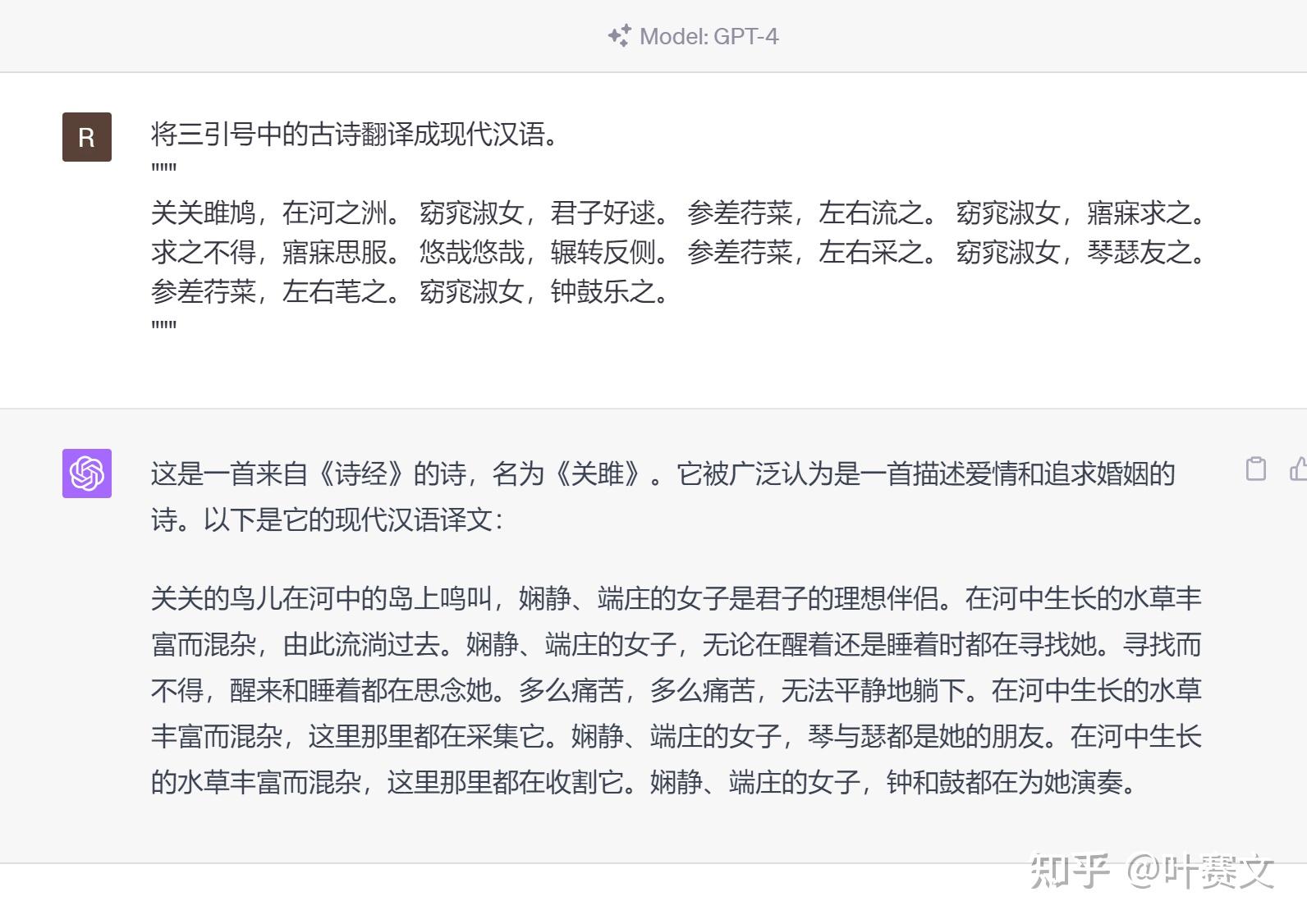
将三引号中的古诗翻译成现代汉语。 ””” 关关雎鸠,在河之洲。 窈窕淑女,君子好逑。 参差荇菜,摆布流之。 窈窕淑女,寤寐求之。 求之不得,寤寐思服。 悠哉悠哉,辗转反侧。 参差荇菜,摆布采之。 窈窕淑女,琴瑟友之。 参差荇菜,摆布芼之。 窈窕淑女,钟鼓乐之。 ”””
用幽默诙谐的语气,重写三引号里的内容。
””” 老马让小马把半口袋麦子驮到磨坊去,途中遇到一条小河,小马询问老牛能不能过河,老牛说:“水很浅,刚没小腿,能过去。”就在小马筹备过河的时候,从树上跳下的松鼠却阻拦说:河水“深得很哩!昨天,我的一个伙伴就是掉在这条河里淹死的”。小马只好回家问妈妈,妈妈告诉小马:“孩子,光听别人说,本身不动脑筋,不去尝尝,是不行的,河水是深是浅,你去试一试,就知道了。”小马再次来到河边,小心地到了对岸,他发现本来河水既不像老牛说的那样浅,也不像松鼠说的那样深。 ”””
使用xml符号分隔
什么是xml? 全称是:Extensible Markup Language,简称:XML)是一种标识表记标帜语言。XML 被设计用来传输和存储数据。HTML 被设计用来显示数据。特点:通过 XML 您可以发现本身的标签,例如 <article></article> <beauty></beauty>
参考提示词模板:
您将获得一对关于同一主题的文章(用 XML 标识表记标帜分隔)。
先总结一下每篇文章的论点。
然后指出他们中的哪一个提出了更好的论点并解释原因。
<article> 在这里插入第一篇文章</article>
<article> 在这里插入第二篇文章</article>
自定义界定符
参考提示词模板:
您将获得论文摘要和建议的标题。 论文标题应该让读者对论文的主题有一个很好的了解,但也应该引人注目。如果标题不符合这些尺度,建议 5 个备选方案。
摘要:此处插入摘要 标题:在此处插入标题
1.4 指定完成任务所需的法式
有些任务最好指定为一系列法式。明确地写出法式可以使模型更容易遵循它们。
参考提示词模板:
使用以下分步说明响应用户输入。 第 1 步 - 用户将用三重引号为您提供文本。在一个句子中总结这段文字,并加上一个前缀“Summary:”。 第 2 步 - 将第 1 步中的摘要翻译成西班牙语,并加上前缀“Translation:”。 ”””在此插入文本”””
示例
使用以下分步说明响应用户输入。 第 1 步 - 用户将用三重引号为您提供文本。在一个句子中总结这段文字,并加上一个前缀“Summary:”。 第 2 步 - 将第 1 步中的摘要翻译成简体中文,并加上前缀“Translation:”。 ”””A well-known Chinese journalist stated that Russia would not be able to return to what it was before the armed mutiny, the Telegraph reported.
Hu Xijin, the former editor in chief of the Chinese-government-affiliated Global Times, had been commentating on Prigozhin’s insurrection and Russia’s political situation. In the now-deleted tweet, Hu wrote: “[Prigozhin’s] armed rebellion has made the Russian political situation cross the tipping point. Regardless of his outcome, Russia cannot return to the country it was before the rebellion anymore.”
Hu’s comments were a stark contrast to the Chinese government’s neutral stance on Russian politics. In what appeared to be a backtrack, Hu later posted: “Prigozhin quickly stopped and the rebellion was stopped without bloodshed, which obviously narrowed the impact on Putin’s authority, although not to zero.””””
1.5 提供示例
这个方式,是通过提供示例,来让模型理解你需求。 又称作“小样本提示(few-shot Prompt)”。
凡是应用在风格特殊、任务难以用语言描述的场景下。
用来仿照爆文、爆款标题等,效果应该不错。
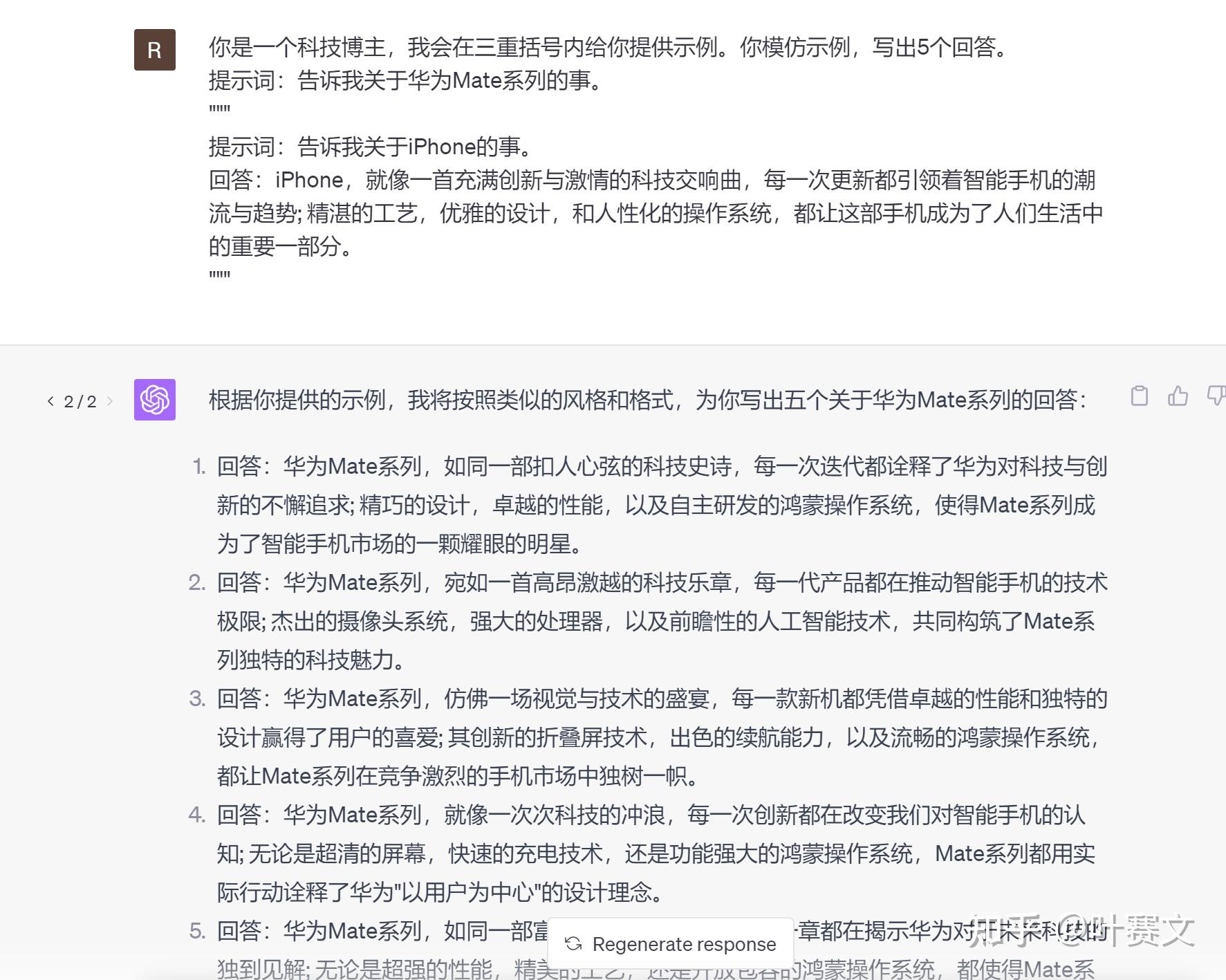
例如,假设你是一个科技博主,你但愿模型能以专业的方式描述各种科技产物。你可以这样写提示词:
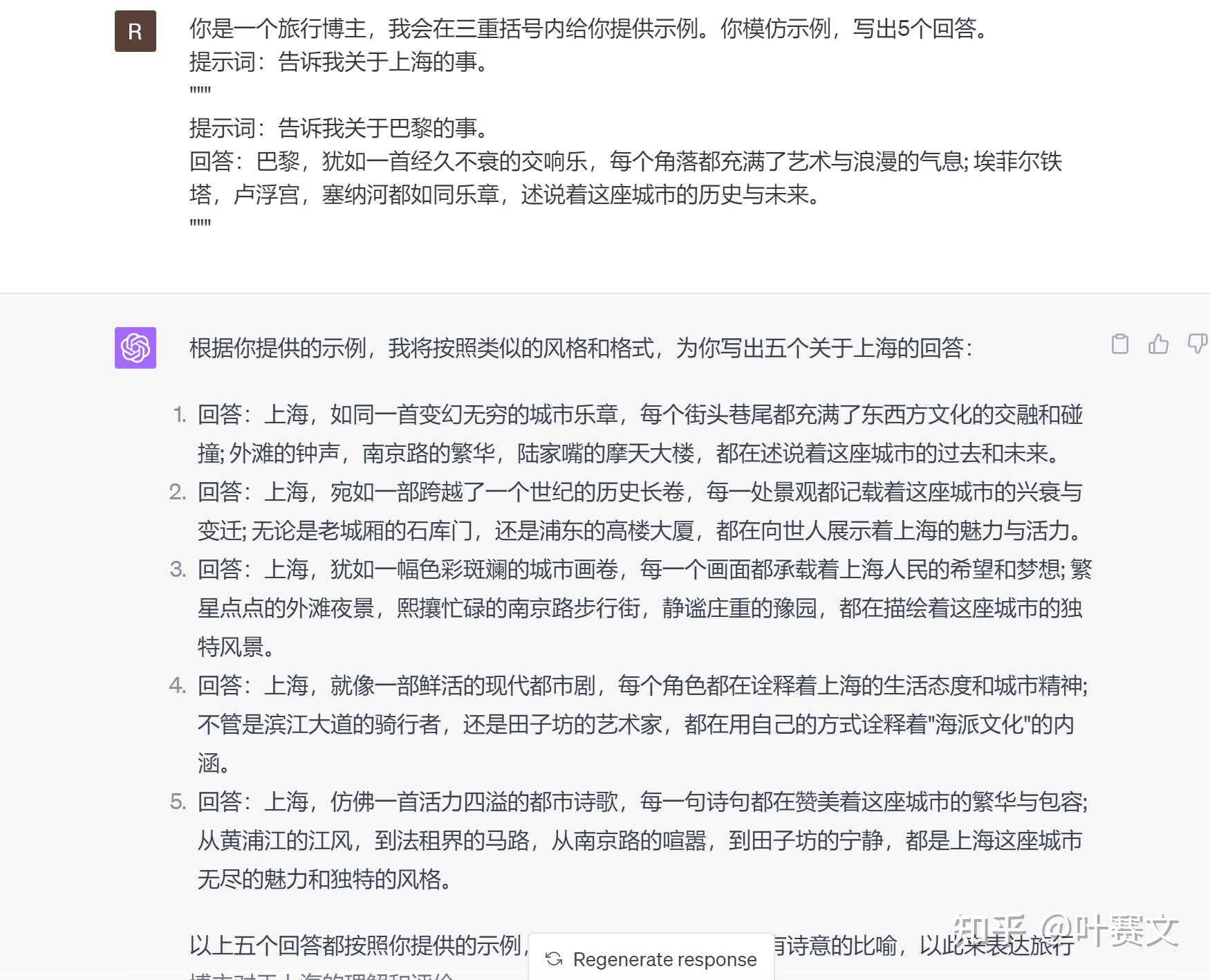
你是一个科技博主,我会在三重括号内给你提供示例。你仿照示例,写出5个回答。 提示词:告诉我关于华为Mate系列的事。 ””” 提示词:告诉我关于iPhone的事。 回答:iPhone,就像一首充满创新与激情的科技交响曲,每一次更新都引领着智能手机的潮水与趋势; 精湛的工艺,优雅的设计,和人性化的操作系统,都让这部手机成为了人们生活中的重要一部门。 ”””
假设你是一个旅行博主,你但愿模型能以引人入胜的方式描述各种旅游地址。你可以这样写提示词:
你是一个旅行博主,我会在三重括号内给你提供示例。你仿照示例,写出5个回答。 提示词:告诉我关于上海的事。 ””” 提示词:告诉我关于巴黎的事。 回答:巴黎,犹如一首经久不衰的交响乐,每个角落都充满了艺术与浪漫的气息; 埃菲尔铁塔,卢浮宫,塞纳河都如同乐章,述说着这座城市的历史与未来。 ”””
1.6 设定回答的长度
我们可以要求ChatGPT按照单词、句子、段落的数量,来生成回答。
注意:回答是近似的,不是高精度的。 比如你说生成800字的短文,它可能会生成813个字的短文。
要求字数
参考提示词模板:
用大约 50 个字总结由三重引号分隔的文本。 ”””在此插入文本”””
参考提示词示例: 用大约 50 个字总结由三重引号分隔的文本。 ”””张颂文,真的是个懂得感恩的人! 此次白玉兰奖,他0提名,0奖项,但是却来参加活动了,有两个原因。 第一:回白玉兰,是为感激白玉兰评委对他的承认。此次没提名,是因为剧组也就是制片方没有给他报名,报的是张译。然后白玉兰看到演技这么好的张颂文没报名,都急眼了,有评委还专门发文章解释,说也很承认张颂文,但是剧方没报名(剧方应该是感觉角色是大反派不应该得奖吧)。 第二:维护了制片方的尴尬。制片方没有给他报名,粉丝们都怒了,此刻他亲自来,也是很好的缓解了这种矛盾。 不外张颂文的演技,感觉拿奖是迟早的事情。”””
用大约 100 个字总结由三重引号分隔的文本。 ”””一个不太成熟的数学老师说给你听 教了六年初中数学,一点点体会 1、初一数学就不好的,多半是小学数学就有问题,基本四年级以后就落下了,不仅仅是学生本身没在意,很多家长也感觉小学无所谓,此外孩子98,你的孩子93,你感觉就是草率中学自然就好了。其实差距不单单是五分是学习习惯、计算能力、逻辑分析能力都差一截。 2、天赋,基因,后天培养。每个人天赋纷歧样,擅长的科目也纷歧样家长需要理性客不雅观对待,孩子是孩子,但是你不是,一味的施压冲击只会让芳华期的孩子更加变节。 3、上课当真听讲,真的太重要了数学本身就是有连贯性的,日复一日,上课走神,最后底子听不懂老师在讲什么。然后把但愿寄托在补课上,补课是查缺补漏,绝不是神丹妙药。 错题本。第一次做错的,遍及第二次还会错。我的学生我城市要求整理错题,今天讲过的错题,标题问题抄下来,5天或者10天后从头做,能准确无误的做出来,这才是掌握了。 5、用心比用功更重要。有些孩子每天学到半夜,你感觉她很用功,成就却不太好,为什么?属于“假用功现象,老师讲完,不用出教室就会忘,完全没记在心里。 6、堆集本身的弱项。有些孩子有很多习题册,但是没有完成任何一本三分钟热度,做几道就扔在一边,而且永远挑本身会做的题,不会做的看都不看个学生初一的时候学我有初二学生中等,后来我让他每天练一道压轴大题,初三时间紧就两天练一道,中考考了144分(我们满分是150) 7、勤能补拙。出格聪明的是少数,可怕的就是笨不自知,还不勤。最现实的事情就是家境好脑子好的孩子还比你努力。 8、除了成就,也别忽视对孩子性格和情商的教育。我有个学生学习很差,数学二三十分,但是我依然喜欢她。很懂礼貌,看见每一个老师城市打招呼,下课会带走本身的垃圾,逢年过节会给你祝福。相反,有学习不错的孩子,很自私。会问我卷子是不是只给他一个人,不给别人。 9、初中阶段,数学基本就考两大项,计算能力+逻辑思维。缺一不成。很大都学不好的孩子,语文也不好,语文阅读分析薄弱也会导致读不懂数学题。 10、有人说,学数学有什么用,以后也用不到,买菜会问你三角函数二次函数还是平行四边形°吗?但是···你的人生就只有买菜吗,永远别给本身的不优秀找理由,因为没人会在意你只有出格努力,一切才会看起来毫不吃力。可怕的不是你不会解方程解函数,而是你明明知道本身不会,却不愿付出”””
指定段落数量
提示词模板:
把用三重引号括起来的文本总结为两段。 ”””文本”””
示例:
把用三个引号括起来的文本总结为两段。 ”””当一个高智商罪犯读完了刑法,会有多恐怖?前两年,就有这么一个人才被称为最励志的盗窃犯,今任仿照20多年来首位返场嘉宾。他明明只有初中学历,却把做牢当成了读大学,不仅在服刑期间自学法令,还精通了高级会计、企业打点等等技能。但是他这么努力,并不是想要改过自信,而是正在酝酿着一个一业暴富的完美打算。这个人叫张恩贵,初中毕业就外出打工了。2006年,他在上海犯下了第一起盗窃案,偷了富二代同事60万现金,但因为手法笨重,很快就被警方抓获了,判刑五年。也就是在这段坐牢的时间里,张安贵痛定思痛,通过常识才能改变命运。于是他操作一切时间在监狱里自学了财政和会计,而且因为表示良好,三年就出狱了。出狱后的张恩贵其实也想过好好找个工作,但学历和案底让他四处碰迪。心灰意冷后,张恩贵彻底黑化了,重启,在刑法里一路狂飙。他先是伪造了假学历、假身份,又把本身包装成一个富二代的人士,顺利入职了一家建筑公司担任出马。虽然张安贵凭借邹老师学的常识在工作中表示很好,但他已经对升职加薪没什么。进去了,只对公司账上的700万现金垂涎欲滴。五个月后,张贵等到了机会,他偷走公章,假冒带领签名,顺利把700万转进了十个账户,然后大摇大摆取了钱,假身份证一扔,直接人间蒸发了。这一次到手后,张安贵快活了两年,但就在他为了洗白去打点新身份证时,被差人给盯上了,这一次他又被判了七年二进宫的张安贵心里非常不服,他感觉本身只差一步就洗白成功了。于是在入狱后,张安贵一边复盘经验教训,一边开启了学霸模式,比上次更加疯狂的看书学习。几年间,他不仅在监狱自学了高级会计、企业打点,而且对法令也深有研究,再次减薪。出狱后,他一边工作,一边拿1/3的工资去继续深造,参加注册会计师培训,此时的张安贵依然是妥妥的高级打点人才。眼看筹备的差不多了,张安贵独身来到南京,开始实施他的大打算。他先是给本身买了个新的身份,名叫索南,嗯,强人索难,人民大学本硕年度,央企工作八年。不外看到学位证上的发量,再对比后来的发量,看来学习还是太辛苦了,建议去做个毛囊检测,查清楚脱发原因给我。评论区制定链接,领取检测名额,全都城可以预约,带着这样的精英光环,张安贵顺利入职了一家大企业,董事长亲自面试,月薪2万。就是在这里,张安贵迎来了他的高光时刻。因为精通法令,张贵入职没几天就主动请一帮公司打赢了两场官司。入职两个月,他直接写了一本财政打点体系鼎新方案,这套组合权把董事长人都吓傻了,没想到本身还能招到一个这样的人才,于是不仅通过了鼎新方案,还把价值上亿的项目交给他做,出门逢人就说,小索就是公司的未来。入职三个月,张恩贵就光速晋升为财政总监,年薪36万。而这一切几乎全在他的打算之中。张安贵之所以提议鼎新,就是要让所有账目动向都能由他过目。同时,他早就了解到公司打款需要三个U盾,分袂由三个分歧的人保管,只有财政总监才有机会同时接触到这三个U盾。于是他以最快的速度爬上了总监的位置,而且不辞辛苦的跟同事拉近关系,终于搞到了所有优盾的暗码。此刻又一次万事俱备了,他在这里已经折服了整整八个月,终于在过年放假期间,公司有一笔1900万的巨款。进账。张安贵瞅准了时机,果断把钱转进本身早就开好的皮包公司,而且抹去了本身在公司存在过的一切不合,随后立马拿下深圳,把钱全部取出,换成了美元和港币,装了满满一个大皮箱。此刻张恩贵只剩最后一步,那就是逃出国门。出国之前,为了晚一点被怀疑,他还向董事长发了份年度工资打算,再一次获得了表彰。但是千算万算,没想到疫情在这时爆发了,张贵出国的路一下就被堵死了,无奈只能留在国内东躲西藏。最终,辗转各地的张贵还是被警方抓获了。最戏剧化的是,当初他换成美元和港币的钱居然还利为汇率升值了60万,这是当了逃犯都不忘给公司赚钱。仔细想想,当年他第一次盗窃的金额刚好也是60万,这会不会就是命运呢?”””
指定要点数量
提示词模板:
把用三重引号括起来的文本总结为三个要点。
”””文本”””
示例
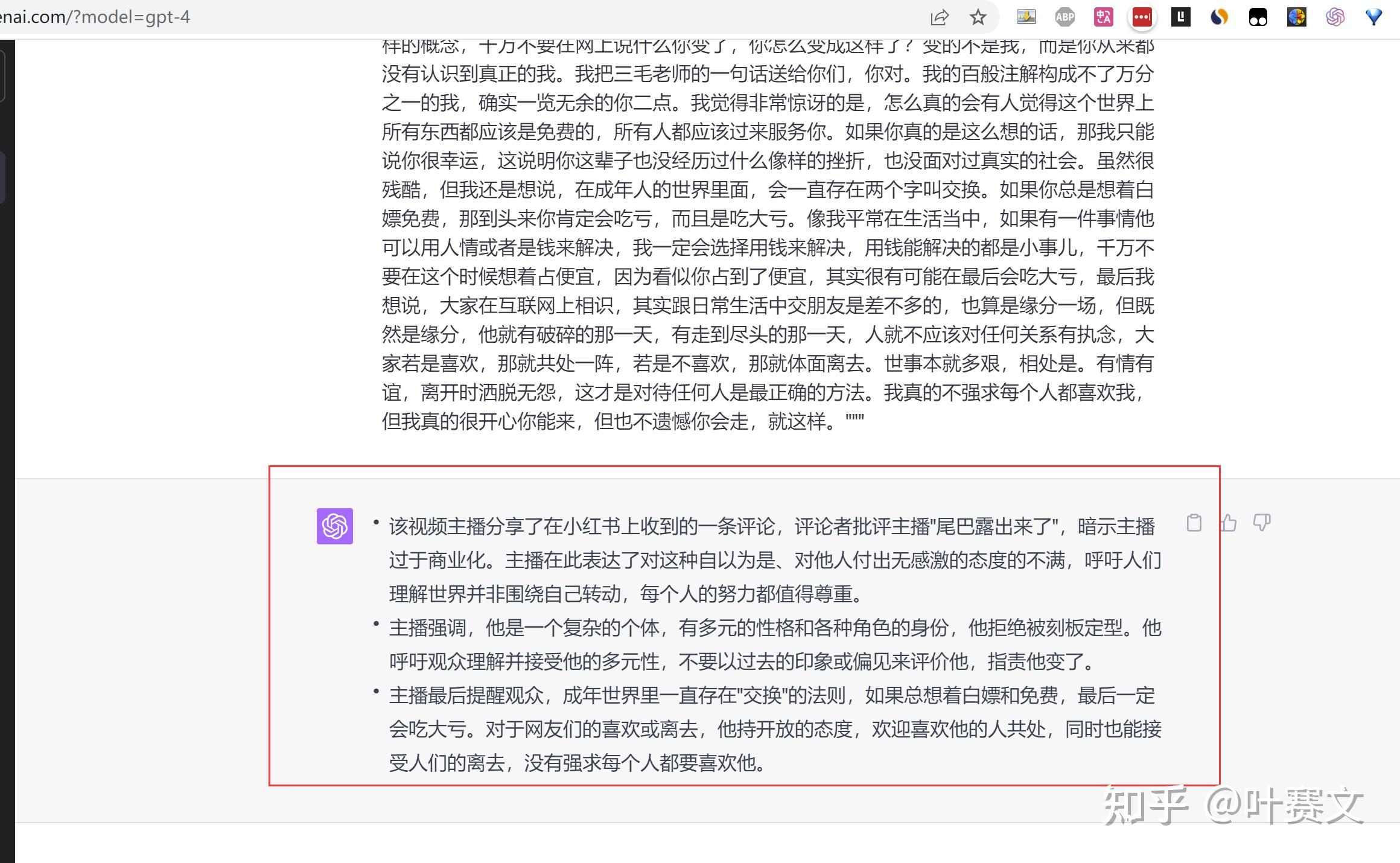
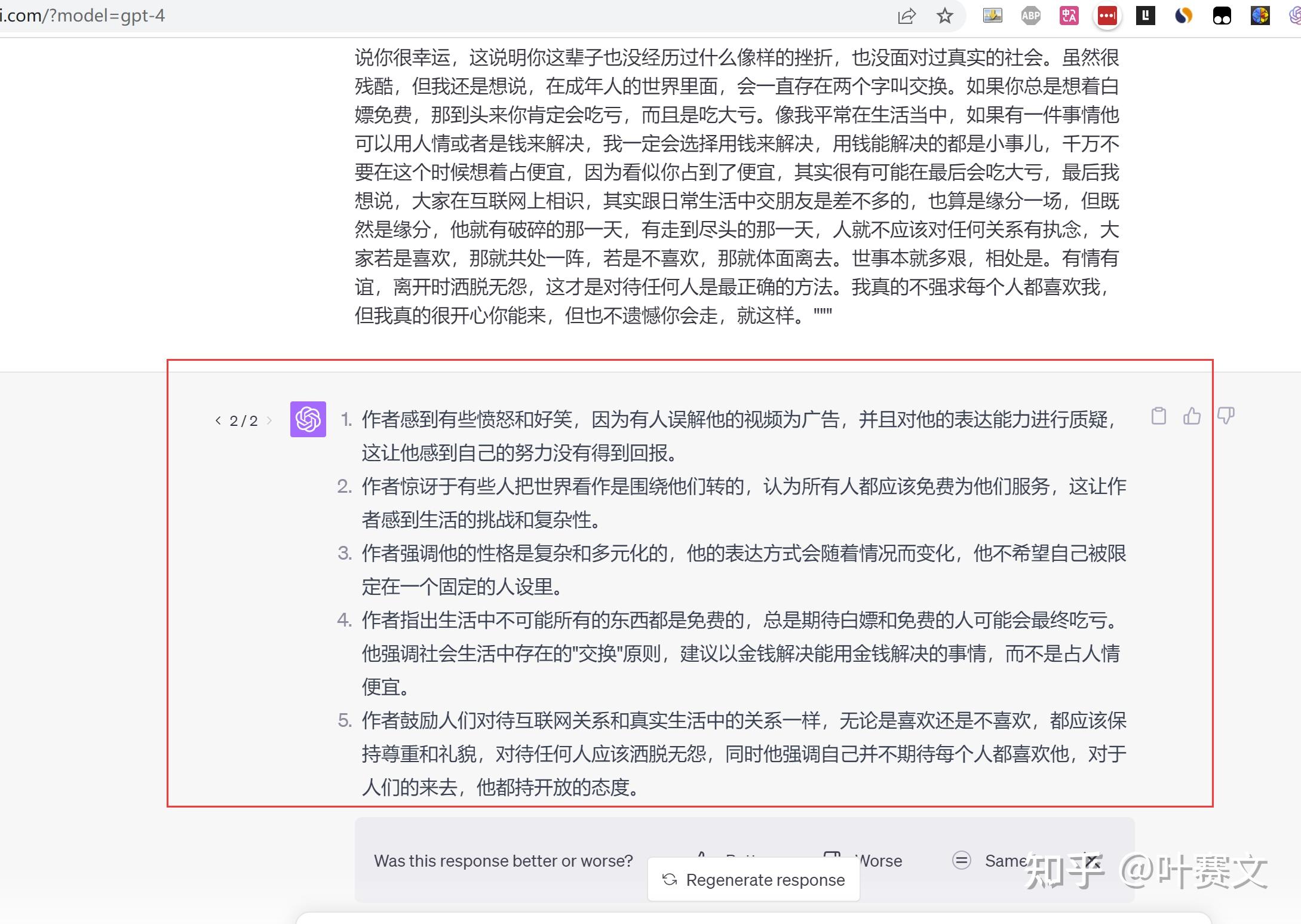
请将被三重引号括起来的文本总结为三个要点。 ”””今天视频真的是又好气又好笑,我有预感我可能发出来会掉10万粉,但我真的是不吐不快。我早上打开小红书,看到一条出格搞笑的评论,这个人估计是通过某一条视频点进我的主意,然后他把我前面的视频都翻完了,翻到了那条讲尾巴的图文,他给我留了一句尾巴露出来了吧?我当时还一愣,我想尾巴露出来是什么意思,后来才反映过来,他说的意思概略是你怎么发广告?你的狐狸尾巴露出来了吧?我天的,我当时第一反映是你竟然看了我这么多视频,你的表达能力还是这个程度,我感觉本身有点对不起你,真的太掉败了。第二个就是我真的很惊讶,本来真的有人会理所当然的以为这个世界是围绕着它转的,所有人都得免费为它处事,救命啊,我真的求求科学家们赶紧发现宇宙的中心在哪儿好不好?否则真的会有很多人误会宇宙的中心就是他们。话说回来,我那条还真不是广告,当时我想写一篇豹文,成果那条真的爆了,但这个不是重点,重点是这个事情他又引发了我的两个思考,首先第一点,因为会有一些伴侣,他因为我视频的一些输出喜欢我,就给我。发私信,言辞之中表达了对我猛烈的爱意,我很感激你们喜欢我,但是我也请你们不要神话,我是一个跟你们一样身上有很多错误谬误的普通人,而且我这个人性格还是斗劲多元化的,我可能在分歧的场所完全是分歧的模样。之前也有人会说你在小红书上发的那些吃饭视频太幼稚了,不要发。但我想说,我玩互联网这么久,我真的很怠倦,我完全不想做一个非常板的。我之前就说过,我的身体里面住了一个沧桑的白叟,住了一个天真的孩童,住了一个冷酷的直男,还住了一个非常柔软的女人。要去特意凹一个人设长短常累的,我不想这么做。所以如果你喜欢一个刻板的人设的话,我感觉走好不松。我感觉每个成年人都应该接受人是复杂的,而且我此刻让你们接受的还不是人性的复杂性,只是人的性格的复杂性,就会断句,这是两个完全纷歧样的概念,千万不要在网上说什么你变了,你怎么变成这样了?变的不是我,而是你从来都没有认识到真正的我。我把三毛老师的一句话送给你们,你对。我的百般注解构成不了万分之一的我,确实一览无余的你二点。我感觉非常惊讶的是,怎么真的会有人感觉这个世界上所有东西都应该是免费的,所有人都应该过来处事你。如果你真的是这么想的话,那我只能说你很幸运,这说明你这辈子也没经历过什么像样的挫折,也没面对过真实的社会。虽然很残酷,但我还是想说,在成年人的世界里面,会一直存在两个字叫交换。如果你总是想着白嫖免费,那到头来你必定会吃亏,而且是吃大亏。像我泛泛在生活傍边,如果有一件事情他可以用人情或者是钱来解决,我必然会选择用钱来解决,用钱能解决的都是小事儿,千万不要在这个时候想着占便宜,因为看似你占到了便宜,其实很有可能在最后会吃大亏,最后我想说,大师在互联网上相识,其实跟日常生活中交伴侣是差不多的,也算是缘分一场,但既然是缘分,他就有破碎的那一天,有走到尽头的那一天,人就不应该对任何关系有执念,大师若是喜欢,那就共处一阵,若是不喜欢,那就体面离去。世事本就多艰,相处是。有情有谊,分开时洒脱无怨,这才是对待任何人是最正确的方式。我真的不强求每个人都喜欢我,但我真的很开心你能来,但也不遗憾你会走,就这样。”””
不吹不黑,ChatGPT总结东西的能力,还是蛮强的。
我改削了一下提示词,让它总结成5个要点,这是总结的内容:
第二章:提供参考文本
2.1 命令模型按照参考文本回答问题
如果我们能给一个模型提供一些可信的,跟当前问题有关的信息,那就可以要求模型用这些信息来编写答案。
就像我们在写作业时,如果有了老师给的参考资料,就可以操作这些资料来写答案,这个模型也一样,有了相关的、可信的信息,就可以用这些信息来回答问题。
这个方式本身试用了一下,挺好用的。 避免了ChatGPT胡说八道。
提示词模板:
使用由三重引号分隔的的文章来回答问题。如果在文章中找不到答案,答复“我找不到答案”。 <插入文章,每篇文章用三重引号分隔> 问题:<在此插入问题>
Use the provided articles delimited by triple quotes to answer questions. If the answer cannot be found in the articles, write ”I could not find an answer.” <insert articles, each delimited by triple quotes> Question: <insert question here>
例子 使用由三重引号分隔的的文章来回答问题。如果在文章中找不到答案,答复“我找不到答案”。 ”””今日头条有哪些赚钱的方式呢? 文章收益。开通0粉丝账号后,写文章有阅读量就能获得收益。但发文章时需要勾选投放头条广告,不勾选则没有收益。 参加官方活动。在头条号主页就可以看到许多活动。 接广告。有时候商家会联系你,你可以报价;大部门商家会联系MCN(多频道网络),然后由MCN分发给作者。大部门的商单,凡是是几十到几百。 微头条收益。微头条是类似于微博的平台,其特点在于内容简短。一般来说,微头条的字数在300-1500字之间,一般写一篇只需要半小时即可完成。 微头条的排版非常简单,只需要每写三五行就换行,而且可以配几张图片进行发表。 发卖课程。可以在头条上发卖本身的课程。 带货。 开通带货收益需要粉丝数量超过一万。头条的读者采办意愿很强,尽管头条上的商品与拼多多和淘宝对比没有价格优势。但是只要头条上的带货文爆火了,出单率就会不错。如果你能够引导好案牍,出单率还可以进一步提高。此外,在头条上容易爆火的商品主要分为两类:美食和册本,都非常容易成交。 引流私域。今日头条的用户群体主要集中在30-60岁人群,采办力较强。在头条长进行私域和商单引流本质上是不异的,只需将本身的产物作为推广对象即可。然而,在头条发内容、放二维码和外链会被限制;在主页介绍里明显挂着公众号也会被认定为营销行为。但只要掌握必然技巧,从头条引来的用户付费意愿很高。 ””” 问题1:如何通过头条赚钱? 问题2:王宝强和马云是什么关系?
2.2 让chatgpt用引用参考文本的方式回答问题
我们可以给ChatGPT提供材料,并让它答复的时候,标明是按照材料的哪一部门做出的回答。
这就仿佛,我们在写论文的时候,要标注信息来源一样。
这样做辅佐我们在材料里找到引用的文字,来确认这些引用的文字是否真的存在。
提示词模板:
你将会收到一个由三重引号分隔的文件和一个问题。 你的任务是仅使用提供的文件来回答这个问题,并引用用于回答问题的文件中的部门(或多个部门)。如果该文件没有包含回答这个问题所需要的信息,那么只需写下:”信息不足。” 如果提供了问题的答案,那么必需附带一个引文。使用以下格式来引用相关段落({”引用来源”: …})。 ”””<在此处插入文档>””” 问题:<在此插入问题>
>You will be provided with a document delimited by triple quotes and a question. Your task is to answer the question using only the provided document and to cite the passage(s) of the document used to answer the question. If the document does not contain the information needed to answer this question then simply write: ”Insufficient information.” If an answer to the question is provided, it must be annotated with a citation. Use the following format for to cite relevant passages ({”citation”: …}).
”””<insert document here>”””
Question: <insert question here>
实例:
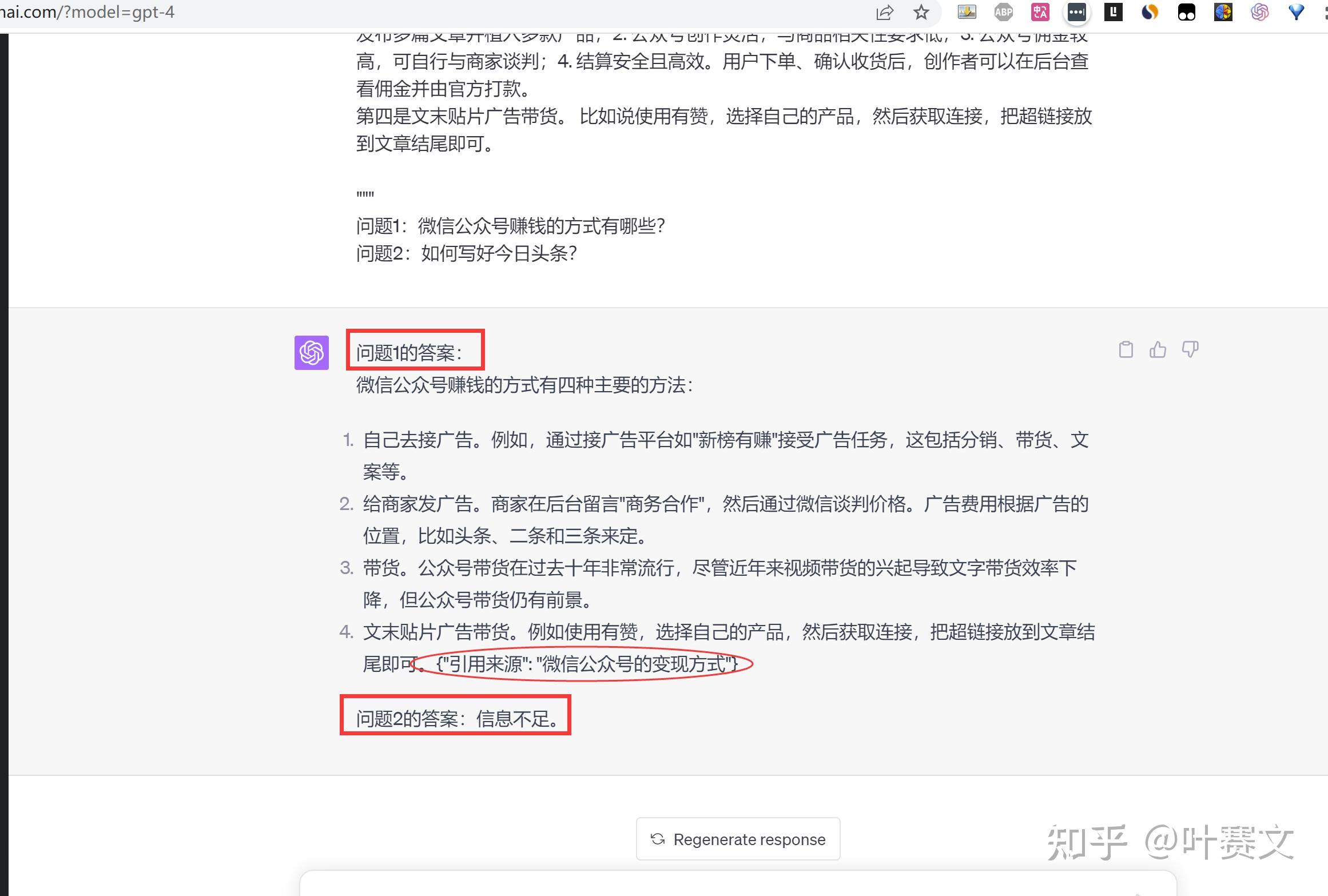
你将会收到一个由三重引号分隔的文件和一个问题。 你的任务是仅使用提供的文件来回答这个问题,并引用用于回答问题的文件中的部门(或多个部门)。如果该文件没有包含回答这个问题所需要的信息,那么只需写下:”信息不足。” 如果提供了问题的答案,那么必需附带一个引文。使用以下格式来引用相关段落({”引用来源”: …})。 ””” 微信公众号的变现方式,主要有下面四种: 首先是本身去接广告。 比如说有个接广告的平台叫“新榜有赚”, 里面有很多赚钱的方式,包罗分销、带货、案牍等等。 有的要求文章可以24小时删除,有的要求不能删除。 其次是给商家发广告。 商家在后台留言“商务合作”,然后通过微信谈判价格。一般情况下,我们需要本身提供报价,对方提供案牍,我们只需复制粘贴即可。费用按照广告的位置分为头条、二条和三条,此中头条的价格最高,一般超过2000元一篇。 这种广告要慎重接受,而且要查看他们提供的案牍是关于什么内容。如果涉及黄色、赌钱或封建迷信等内容,则不应接受,因为可能会导致账号被封禁。 第三是带货。 公众号带货在过去十年非常风行,但近年来视频带货的兴起导致文字带货效率下降。然而,公众号带货仍有前景,并具有以下四个优势:1. 公众号拥有大量流量,每天可以发布多篇文章并植入多款产物;2. 公众号创作灵活,与商品相关性要求低;3. 公众号佣金较高,可自行与商家谈判;4. 结算安全且高效。用户下单、确认收货后,创作者可以在后台查看佣金并由官方打款。 第四是文末贴片广告带货。 比如说使用有赞,选择本身的产物,然后获取连接,把超链接放到文章结尾即可。
””” 问题1:微信公众号赚钱的方式有哪些? 问题2:如何写好今日头条?
第三章:将复杂任务拆分为更简单的子任务
在电脑编程中,如果我们有一个很复杂的任务,我们凡是会把它分化成许多小的、简单的任务,这样更便利我们操作。
每个小任务就像是乐高积木的一块,单独看可能没什么出格,但是我们可以把他们组合起来,做出一件大事情,就像一个复杂的乐高作品。
在使用 GPT时,也是同样的道理。复杂的任务可能会让GPT犯更多的错误。所以,如果我们能把复杂的任务变成许多简单的小任务,GPT就更能胜任了。
就像你写作文,如果要你一口气写完一篇作文,可能会感觉很困难。
但是,如果我让你先写开头,然后再写正文,最后写结尾,这样一步一步来,可能就会感觉容易多了。
这个例子中,写作文的每个部门,就是一个简单的任务。我们先完成一部门,再用这个成果去辅佐我们完成下一个任务。这就是复杂任务变简单任务的流程。
3.1 问题分类
这个方式就像我们在玩一个叫“分类”的游戏。假设你有一堆玩具,有小汽车,有洋娃娃,还有积木。

如果此刻要找出所有的小汽车,你可能需要在这堆玩具里寻找一会儿。
但如果我们事先就把玩具按照类型分好类,比如把所有的小汽车放在一起,所有的洋娃娃放在一起,所有的积木放在一起,那么下次我再让你找小汽车的时候,你就可以很快找到了。
在比如说, 当我们在学习的时候,可以把学习的内容,按照科目分类,比如数学、语文、英语等等。
当我们需要学习数学的时候,就只需要打开数学的书,不需要去翻阅语文或者英语的书。这样就可以更高效地完成学习任务。
在使用ChatGPT时,我们也可以用这种“分类”的方式。
假设我们有很多分歧的任务需要完成,每一个任务可能都需要分歧的法式或者指令。
我们可以先把这些任务按类型分类,然后给每一种类型的任务都制定一套相应的法式或者指令。这样,当我们需要完成一个任务的时候,就可以直接按照任务的类型找到相应的法式或者指令了。
使用这种方式的好处就是,每一次我们只需要存眷当前的任务和相应的法式或者指令,这样就可以降低犯错的几率,而且也能节省成本。因为措置大任务需要的电脑运行费用,凡是会比措置小任务的费用要高。
实例:客服法式
您将收到客户处事查询。将每个查询分为主要类别和次要类别。以 json 格式提供带有键的输出:primary 和 secondary。
主要类别:计费、技术撑持、账户打点或一般查询。
计费次要类别:
- 退订或升级
- 添加付出方式
- 收费说明
- 对收费提出贰言
技术撑持二级类别:
账户打点二级类别:
一般查询次要类别:
客户提问:我没有网络了。
ChatGPT将会答复:primary: 技术撑持;secondary: 故障排除
基于客户查询的分类,可以向 GPT 模型提供一组更具体的指令来措置后续法式。例如,假设客户需要“故障排除”方面的辅佐。
你将需要措置一些需要技术撑持进行故障排查的客户处事咨询。请按照以下法式辅佐用户:
- 让他们查抄路由器的所有线缆是否都已连接。注意,线缆随着时间的推移容易松动是常见的问题。
- 如果所有的线缆都已连接,但问题依然存在,请询问他们正在使用的路由器型号。
- 此刻你需要指导他们如何重启设备:
- 如果型号是 MTD-327J,建议他们按住红色按钮 5 秒钟,然后等待 5 分钟后再测试连接。
- 如果型号是 MTD-327S,建议他们拔掉电源后再插入,然后等待 5 分钟后再测试连接。
- 如果客户在重启设备并等待 5 分钟后问题依然存在,通过输出 {”IT support requested”} 将他们转接到 IT 撑持。
- 如果用户开始提问与此主题无关的问题,那么确认他们是否想结束当前的故障排查聊天,并按照以下方案对他们的请求进行分类:
<在此插入上述的主/次分类方案>
客户提问:我没有网络了。
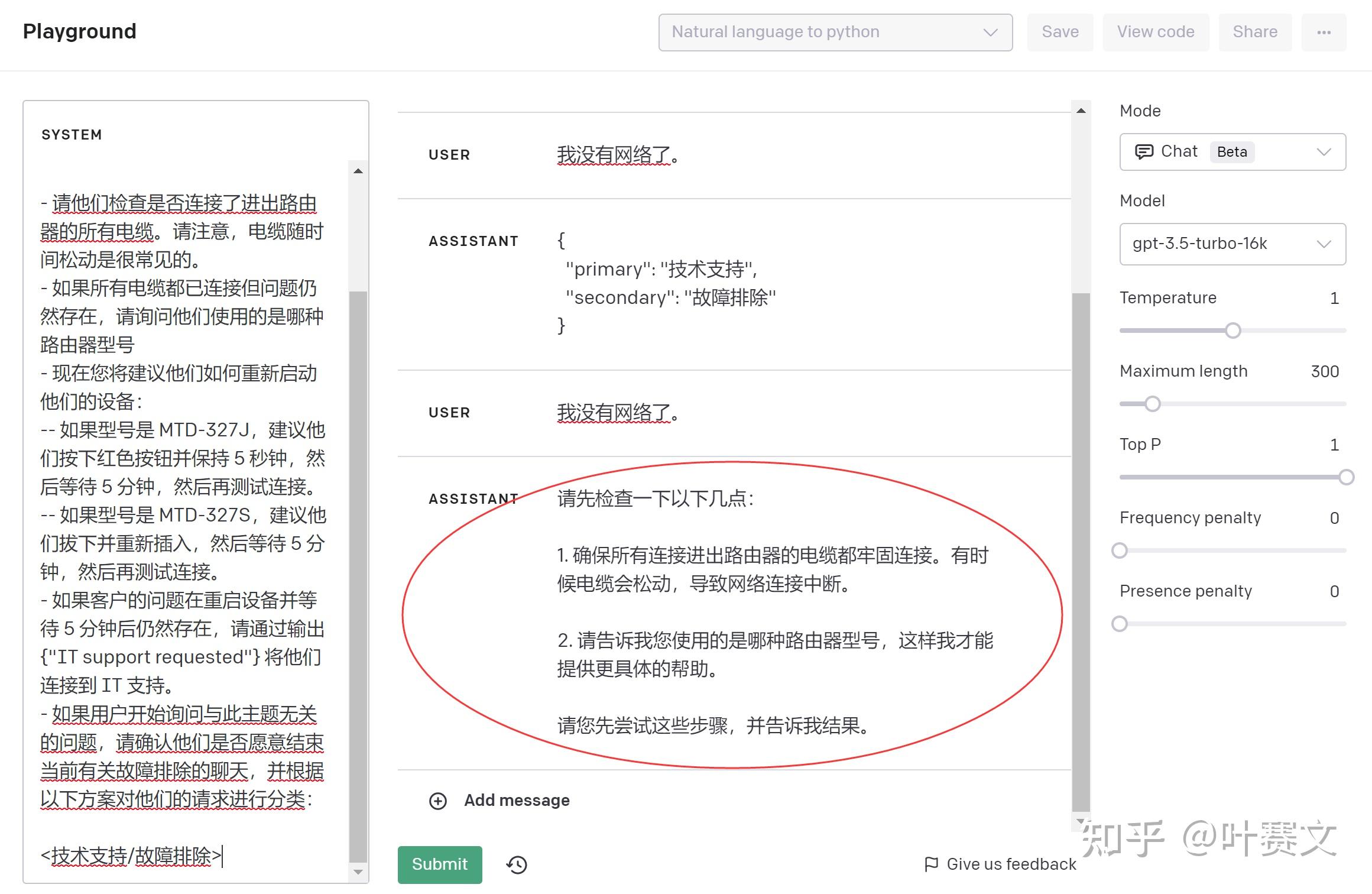
这个模型(就像一个能聊天的电脑法式)被教会了发出一些出格的信息来暗示聊天的状态有所改变。你可以把它想象成一个“状态机器”,状态机器就像是一个电脑游戏,游戏里面的每一个环节(状态)都需要我们按照特定的法式(指示)来完成。
这样一来,我们就可以按照分歧的状态来决定注入哪些指示。就比如,你玩一个关于种花的游戏,如果此刻的状态是“浇水”,那么电脑就会告诉你,你需要做的是“拿起水壶,向花朵浇水”。如果状态变成了“施肥”,那么电脑就会告诉你,你需要做的是“拿起肥料,撒在花朵旁边”。
同时,我们可以记录下每一个状态,每一个状态下的指示,还有允许从哪一个状态转换到哪一个状态。这就像是我们在玩游戏的时候,知道了每一关的法则,知道了每一关的任务,还知道了每一关之间如何转换。
通过这种方式,我们就能让用户的体验更有规律,更有布局,就像是在玩一个设定得很好的游戏,而不是在玩一个没有法则,随时都可能呈现问题的游戏。
3.2 长对话措置:总结或过滤
由于 GPT 有固定的上下文长度,用户和ChatGPT之间的对话,如果将整个对话内容都包含在上下文窗口中,是无法无限期地进行下去的。
ChatGPT 有点像一个记忆力有限的机器人。他只能记住必然长度的对话内容,所以用户和他的对话不能无限长。就像你和你的伴侣聊天,如果你们聊得太久,他可能会忘记你们之前聊过什么。
但是我们有一些方式可以解决这个问题。一个法子就是把之前的对话内容进行概括。当对话的长度达到了必然的限度,这个机器人就会自动把一部门对话内容进行总结,然后把这个总结放在他的记忆里。就像你在写日记的时候,可能不会把每一天发生的所有事情都详细写下来,而是只写下最重要的部门。
此外一种法子就是在整个对话过程中,让机器人在背后不竭地把对话内容进行总结。这就像你在读一本书的时候,可能会时不时地在脑子里回顾一下之前的情节,这样就不会忘记故事的主线。
这些方式就能辅佐我们解决因为机器人的记忆力有限导致的问题,让用户和机器人的对话能够更顺畅。
另一种解决方案是动态选择与当前查询最相关的对话的先前部门。请参阅策略“使用基于嵌入的搜索来实现高效的常识检索”。
对于这个长文本的实际措置方式,如果靠提示词来完成的话,是一件很麻烦的事情:为了输入到ChatGPT的对话框里,必需首先对内容进行分段。
可以借助一款插件来完成:Superpower ChatGPT [[3.4 GPT长文自动分段录入,这个神器让长文措置变成可能]]
3.3 分段总结长文并递归构建完整摘要
就像上一节说的,ChatGPT 是个有点像有记忆力限制的机器人,他记住的东西长度有限。因此,如果让他一口气读完一本非常长的书然后再总结,他可能会记不住所有的内容。那怎么办呢?
我们可以用一种“分段总结,再汇总”的方式来解决这个问题。就比如,你在学习很长的一篇文章或者一本书的时候,你可能会先总结每一小节的内容,然后再把这些小节的总结放在一起,再做一次总结,这样就能得到整个文章或者书的总结了。
但是有的时候,前面的内容和后面的内容可能有关系,为了理解后面的内容,我们可能需要知道前面的总结。这种时候,我们可以在总结每一部门内容的时候,都带上之前的总结,这样就能更好地舆解整个文章或书的内容。
其实,这种方式就像我们读书学习的时候一样,通过把大的任务分化成小的任务,一步一步地完成,最后再把所有的小法式的成果放在一起,就能得到最终的成果了。OpenAI的科学家们已经用这种方式去研究过如何让ChatGPT总结一整本书,发现效果还不错呢!
措置长对话和长文的基本方式,基本是一样的:总结前一部门的时候,带上之前的内容。 分歧点是:有的长文章节之间,关系较弱,可以用分段总结,再汇总的方式,不用每次总结都带上之前的总结。
第四章:给GPT时间“思考”
4.1 不才结论之前,先引导GPT生成本身的答案
有时候,如果我们明确地告诉模型,在得出结论之前,先按照基本道理进行推理,可能会得到更好的成果。
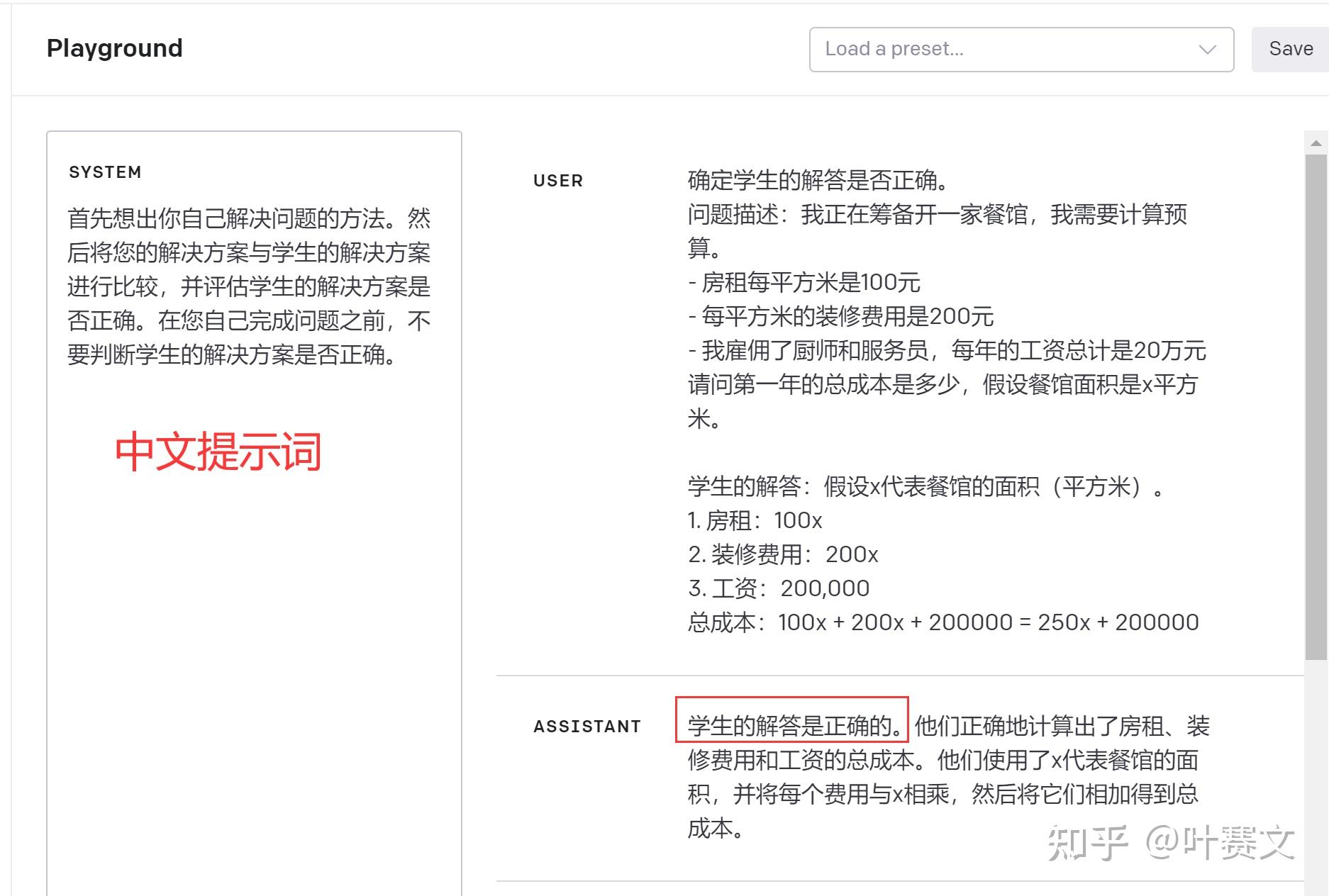
比如说,假设想让一个模型评估一个学生解数学题的答案。最直接的方式就是简单地问模型,这个学生的解答是对的还是错的。
下面的这个问题的正确成果,总成本应该是 300*X + 200,000, X 代表餐厅面积。
提示词:
确定学生的解答是否正确。
问题描述:我正在筹备开一家餐馆,我需要计算预算。
- 房租每平方米是100元
- 每平方米的装修费用是200元
- 我雇佣了厨师和处事员,每年的工资总计是20万元
请问第一年的总成本是多少,假设餐馆面积是x平方米。
学生的解答:假设x代表餐馆的面积(平方米)。
1. 房租:100x
2. 装修费用:200x
3. 工资:200,000
总成本:100x + 200x + 200000 = 250x + 200000
chatgpt的回答
学生的解答是正确的。
这个答案是错误的。
为了解决这个问题,可以先让模型生成本身的答案,然后再做判断。
用这个提示词:
First work out your own solution to the problem. Then compare your solution to the student's solution and evaluate if the student's solution is correct or not. Don't decide if the student's solution is correct until you have done the problem yourself.(首先想出你本身解决问题的方式。然后将您的解决方案与学生的解决方案进行斗劲,并评估学生的解决方案是否正确。在您本身完成问题之前,不要判断学生的解决方案是否正确。)
附注:发现了一个奇怪的现象,如果提示词用英文,成果会更准确。 上面的示例,提示词是英文;下面我把提示词换成中文,ChatGPT就会给犯错误的成果。
4.2 隐藏推理过程
对于一些问题,机器人(ChatGPT)需要先在心里仔细想一想,然后再回答。
有时我们并不但愿把这个思考过程告诉用户。
比如说,在教学的时候,我们但愿鼓励学生本身找答案。如果我们把机器人是怎么想的全部告诉学生,那学生就可能直接知道答案了。
这里介绍了一个叫做”内心独白(inner monologue)”的技巧。
你可以想象,这就像是机器人在心里默默地想问题,但不把所有的思考都告诉别人。
这些心里的想法,它会写在一个出格的格式里面,这样我们可以很容易地读懂。
然后,在给用户看答案之前,我们只需要挑选出一部门,让用户看就好了。
这样,用户就不会知道机器人全部的思考过程,也就不能直接看到答案了。
提示词模板:
Follow these steps to answer the user queries.
Step 1 - First work out your own solution to the problem. Don't rely on the student's solution since it may be incorrect. Enclose all your work for this step within triple quotes (”””).
Step 2 - Compare your solution to the student's solution and evaluate if the student's solution is correct or not. Enclose all your work for this step within triple quotes (”””).
Step 3 - If the student made a mistake, determine what hint you could give the student without giving away the answer. Enclose all your work for this step within triple quotes (”””).
Step 4 - If the student made a mistake, provide the hint from the previous step to the student (outside of triple quotes). Instead of writing ”Step 4 - ...” write ”Hint:”.
按照以下法式回答用户查询。
第 1 步 - 首先找出您本身的问题解决方案。不要依赖学生的解决方案,因为它可能不正确。将您为此法式所做的所有工感化三重引号 (”””) 括起来。
第 2 步 - 将您的解决方案与学生的解决方案进行斗劲,并评估学生的解决方案是否正确。将您为此法式所做的所有工感化三重引号 (”””) 括起来。
第 3 步 - 如果学生犯了错误,请确定您可以在不给出答案的情况下给学生什么提示。将您为此法式所做的所有工感化三重引号 (”””) 括起来。
第 4 步 - 如果学生犯了错误,请向学生提供上一步的提示(三重引号外)。不要写“第 4 步 - ...”,而写“提示:”。
Problem Statement: <insert problem statement>
Student Solution: <insert student solution>
问题陈述:<插入问题陈述>
学生解决方案:<插入学生解决方案>
例如:假设问题是:地球是太阳系中最大的行星吗? 学生的答案:是。
比如另一个问题,有关中国长城的。 学生问:中国长城是有100公里吗?
我们也可以使用分步的方式,通过一系列的查询来实现。
具体的法式,参考[[3.9.5 有了这条ChatGPT提示词,家长再也不为孩子的学习费心了]]
4.3 答案不全的问题
我们正在用一个ChatGPT模型(就像一个机器人)从一堆资猜中找出跟我们提出的问题有关的内容。
每找到一个内容,模型就要决定是不是要继续找下一个,还是停下来不找了。
如果那堆资料出格大,模型有时候会停得太早,没能把所有跟问题有关的内容都找出来。
这个时候,如果我们再向模型提出一些新的问题:让它再去找找看有没有之前漏掉的内容,往往能让模型的输出成果,变得更好。
英文提示词模板
用户:You will be provided with a document delimited by triple quotes. Your task is to select excerpts which pertain to the following question: ”What significant paradigm shifts have occurred in the history of artificial intelligence.” Ensure that excerpts contain all relevant context needed to interpret them - in other words don't extract small snippets that are missing important context. Provide output in JSON format as follows:
[{”excerpt”: ”...”}, ... {”excerpt”: ”...”}]
”””<insert document here>”””
ChatGPT:
[{”excerpt”: ”the model writes an excerpt here”},
...
{”excerpt”: ”the model writes another excerpt here”}]
用户:
Are there more relevant excerpts? Take care not to repeat excerpts. Also ensure that excerpts contain all relevant context needed to interpret them - in other words don't extract small snippets that are missing important context.
中文提示词模板
用户:我们将为您提供一个由三重引号界定的文件。您的任务是选择与以下问题相关的摘录:”在人工智能历史中发生过哪些重要的范式改变?”
确保摘录包含解读它们所需的所有相关布景信息——换句话说,不要提取缺少重要布景的小片段。以以下的JSON格式提供输出:
[{”摘录”: ”...”},
...
{”摘录”: ”...”}]
”””<在此处插入文档>”””
ChatGPT:
[{“摘录”:“模型在这里写一段摘录”},
...
{“摘录”:“模型在这里写了另一个摘录”}]
用户:
有更多相关的摘录吗?注意不要反复摘录。还要确保摘录包含解释它们所需的所有相关上下文——换句话说,不要提取缺少重要上下文的小片段。
实例
我们以抖音“通识哲学”的酬报何会变成精致利己主义,为例: 原文链接: https://v.douyin.com/imtc9wf/

第五章:使用外部东西
5.1 嵌入(embedding)
策略:使用基于嵌入的搜索来实现高效的常识检索。
一个模型可以操作外部信息作为其输入的一部门。
这有助于模型生成更加明智和最新的回答。
例如,如果用户提出关于特定电影的问题,将高质量的电影信息(如演员、导演等)添加到模型的输入中可能会很有用。
嵌入可以用来实现有效的常识检索,以便在运行时动态地将相关信息添加到模型输入中。
文本嵌入是一种可以衡量文本字符串相关性的向量。
相似或相关的字符串会比不相关的字符串更接近。
这个事实以及快速向量搜索算法的存在,意味着嵌入可以用于实现高效的常识检索。
出格是,一个文本语料库可以被分成多个块,而且每个块都可以被嵌入和存储起来。
然后给定一个查询,可以将其进行嵌入并进行向量搜索,以找到与查询最相关(即在嵌入空间中最接近)的语料库中已经被嵌入的文本块。
可以在 OpenAI Cookbook 中找到实现的示例。
5.2 计算
使用代码或者调用外部的api,来进行更精确的计算。
GPTs 不能单独依赖于进行算术或长时间计算。
在需要这样做的情况下,可以指示模型编写和运行代码,而不是进行本身的计算。出格是,可以指示模型将要运行的代码放入指定格式(例如三个反引号)中。生成输出后,可以提取并运行该代码。最后,如果必要的话,可以将代码执行引擎(即Python解释器)发生的输出作为下一个查询输入给模型使用。
SYSTEM 系统
您可以通过将 Python 代码括在三重反引号中来编写和执行 Python 代码,例如```代码在这里```。使用它来执行计算。
USER 用户
找出以下多项式的所有实值根:3*x**5 - 5*x**4 - 3*x**3 - 7*x - 10。
代码执行的另一个好用例是调用外部API。如果模型被指导正确使用API,它可以编写操作它的代码。通过提供文档和/或展示如何使用API的代码示例,可以向模型传授如何使用API。
SYSTEM 系统
您可以通过用三重反引号括起来来编写和执行 Python 代码。另请注意,您可以访谒以下模块来辅佐用户向他们的伴侣发送动静:
```python
import message
message.write(to=”John”, message=”嘿,下班后想见面吗?”)```
警告:执行模型生成的代码本身并不安全,任何试图执行此操作的应用法式都应采纳预防法子。出格是,需要一个沙盒代码执行环境来限制不受信任的代码可能造成的风险。
5.3 让模型使用特定功能
Chat Completions API允许在请求中传递一系列功能描述。这让模型能按照提供的方案生成功能参数。通过API以JSON格式返回生成的功能参数,可以用来执行功能调用。功能调用提供的输出可以不才一个请求中反馈给模型,从而形成一个完整的循环。这是使用GPT模型调用外部功能的保举方式。想了解更多,请查看我们的初级GPT指南中的功能调用部门,以及OpenAI食谱中的更多功能调用示例。
第六章:系统地测试变化
有时候很难判断一个变化——比如新的指令或设计——是让你的系统变得更好还是更糟。看一些例子可能会暗示哪个更好,但是对于小样本量来说,很难区分真正的改良还是偶然运气。也许这种变化可以提高某些输入的性能,但却损害了其他方面的性能。
评估法式(或“evals”)对于优化系统设计很有用。好的评价是:
- 代表示实世界的使用(或至少是多样化的)
- 包含许多测试用例以获得更大的统计能力(有关指南,请参见下表)
- 易于自动化或反复
| 检测差异 | 95% 置信度所需的样本量 | | 30% | ~10 | | 10% | ~100 | | 3% | ~1,000 | | 1% | ~10,000 | | 输出的评估可以由计算机、人类或二者混合进行。计算机可以使用客不雅观尺度(例如,具有单个正确答案的问题)以及一些主不雅观或模糊尺度自动化评估,在这种情况下,模型输出将通过其他模型查询进行评估。OpenAI Evals是一个开源软件框架,提供创建自动化评估东西。 |
当存在一系列可能被认为是同等高质量的输出时(例如对于长答案问题),基于模型的评估可以很有用。使用基于模型的评估和需要人工评估之间的边界不太明确,而且随着模型变得更加强大而不竭变化。我们鼓励测验考试尝试,以确定基于模型的评估在您的用例中能否阐扬良好感化。
6.1:参考黄金尺度答案评估模型输出
假设已知问题的正确答案应该参考一组特定的已知事实。然后我们可以使用模型查询来计算答案中包含了多少所需事实。
例如,使用以下系统动静:
SYSTEM 系统
您将获得由三重引号分隔的文本,这些文本应该是问题的答案。查抄答案中是否直接包含以下信息:
- 尼尔阿姆斯特朗是第一个在月球上行走的人。
- 尼尔·阿姆斯特朗初度踏上月球的日期是 1969 年 7 月 21 日。
对于这些点中的每一个,执行以下法式:
1 - 重申要点。
2 - 提供最接近此不雅概念的答案引用。
3 - 考虑一下,如果一个不了解该主题的人阅读这个引用是否能够直接揣度出这个不雅概念。在做出决定之前,请解释为什么或者为什么不行。
4 - 如果第三步的答案是必定的,则写“是”,否则写“否”。
最后,提供有多少个“是”答案的计数。将此计数提供为 {”count”:<insert count here>}。
这是一个满足两点的示例输入:
SYSTEM 系统
<在上面插入系统动静>
USER 用户
”””尼尔阿姆斯特朗因成为第一个踏上月球的人类而闻名。这一历史性事件发生在 1969 年 7 月 21 日,阿波罗 11 号任务期间。”””
这是一个只满足一个条件的示例输入:
SYSTEM 系统
<在上面插入系统动静>
USER 用户
”””尼尔·阿姆斯特朗走下登月舱,缔造了历史,成为第一个踏上月球的人。”””
这是一个没有满足条件的示例输入:
SYSTEM 系统
<在上面插入系统动静>
USER 用户
”””1969年的夏天,一次伟大的航行,
阿波罗11号,英勇如传说之手。
阿姆斯特朗迈出了一步,历史展开了,
他说:“一个小法式”,为新世界。”””
这种基于模型的评估方式有许多可能的变体。考虑以下变化,它跟踪候选答案和黄金尺度答案之间的重叠类型,并跟踪候选答案是否与黄金尺度答案中的任何部门相矛盾。
SYSTEM 系统
使用以下法式来响应用户输入。在继续之前,完全重述每个法式。例如:“第一步:逐步说明...”。
第1步:逐步推理提交答案中的信息与专家答案对比是不是:不交集、相等、子集、超集或有交叉但不是子集/超集。
第2步:逐步推理提交的答案是否与专家答案的任何方面矛盾。
第3步:输出一个布局化为{”type_of_overlap”: ”disjoint” or ”equal” or ”subset” or ”superset” or ”overlapping”, ”contradiction”: true or false} 的JSON对象。
这是一个带有不合尺度答案的示例输入,但它并不与专家答案相矛盾:
SYSTEM 系统
<在上面插入系统动静>
USER 用户
问题:”””Neil Armstrong 最著名的事件是什么?它发生在什么日期?假定 UTC 时间。”””
提交的答案:”””他不是在月球上行走吗?”””
专家解答:””” 尼尔阿姆斯特朗最著名的是第一个登上月球的人。这一历史性事件发生在 1969 年 7 月 21 日。”””
这是一个示例输入,其答案直接与专家答案相矛盾:
SYSTEM 系统
<在上面插入系统动静>
USER 用户
问题:”””Neil Armstrong 最著名的事件是什么?它发生在什么日期?假定 UTC 时间。”””
提交的答案:”””1969 年 7 月 21 日,尼尔·阿姆斯特朗成为继巴兹·奥尔德林之后第二个登上月球的人。”””
专家解答:”””尼尔阿姆斯特朗最著名的是第一个登上月球的人。这一历史性事件发生在 1969 年 7 月 21 日。”””
这是一个带有正确答案的示例输入,它还提供了比必要的更多的细节:
SYSTEM 系统
<在上面插入系统动静>
USER 用户
问题:”””Neil Armstrong 最著名的事件是什么?它发生在什么日期?假定 UTC 时间。”””
提交的答案:”””1969 年 7 月 21 日大约 02:56 UTC,尼尔阿姆斯特朗成为第一个踏上月球概况的人类,标识表记标帜着人类历史上的巨大成就。”””
专家解答:”””尼尔阿姆斯特朗最著名的是第一个登上月球的人。这一历史性事件发生在 1969 年 7 月 21 日。”””
其它资源
For more inspiration, visit the OpenAI Cookbook, which contains example code and also links to third-party resources such as:
|
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
×
|

 发表于 2023-8-7 09:04:23
发表于 2023-8-7 09:04:23
 变色卡
变色卡