|
|
如何识别 AI 生成图片?or 如何识别 AIGC 图?or 如何识别 AI 换脸?or AI生成图伪造检测?
类似的说法有很多种,总之就是操作AI技术来分辩一张图是不是AI生成的,这种AI技术就是本文的内容。
伴侣好,我是卷了又没卷,薛定谔的卷的AI算法工程师「陈城南」~ 担任某大厂的算法工程师,带来最新的前沿AI常识和东西,欢迎大师交流~,后续我还会分享更多 AI 有趣东西和实用玩法,包罗 ChatGPT、AI绘图等。
- 公众号「陈城南」或 加「cchengnan113」备注AI交流群
- 知乎账号「陈城南」
视觉AIGC识别
现阶段视觉AIGC(AI-generated Content,人工智能出产内容)主要包罗图片(Image)和视频(Video),视频的本质是持续的图片帧,忽略其音频信息的情况下,视频生成则是图片生成的延伸。因此,视觉AIGC识别主要聚焦在AIG图片的识别。
在AIGC这个概念爆火之前,图片生成的应用一直存在,比如操作GAN进行AI换脸等。因为AI绘图和ChatGPT等大规模语言模型(LLMs)分袂在两个范围表示出惊人的效果并成功出圈,AIGC这一概念才开始被大师熟知。本文所说的「视觉AIGC识别」则同时包含AI换脸等前AIGC时代的检测,也包含Midjourney、SD等AI绘图场景的识别。

img
由于AI换脸等人脸伪造技术在应用和负面影响上较大,技术相对成熟,其识别难度也较大,识此外相关研究也便相对集中。因此,本文按照已有的研究工作调研,将视觉AIGC识别粗略划分为:
- 人脸伪造检测(Face Forgery Detection):包含人脸的AIG图片/视频的检测,例如AI换脸、人脸操控等。此类方式主要存眷带有人脸相关的检测方式,检测方式可能会涉及人脸信息的先验。
- AIG整图检测(AI Generated-images Detection):检测一整张图是否由AI生成,检测更加的泛化。这类方式相对更存眷生成图与真实图更通用的底层区别,凡是专注于整张图,比如近年爆火的SD、Midjounery的绘图;
- 其他类型假图检测(Others types of Fake Image Detection):此类方式更方向于 局部伪造、综合伪造等一系列更复杂的图片造假,当然人脸伪造也属于局部、复杂,但是是人脸场景。将AIG图与真实图拼凑、合成的图片识别也属于这一类。
这三种类型之间划分并不明晰,很多方式同时具有多种检测能力,可划分为多种类型。严格意义上说AIG整图和其他造假图检测类型可能城市包含人脸信息,但三种类型方式往往技术出发点也分歧。
生成式模型总览
img
图片生成模型斗劲受欢迎的主要有3种基础架构[0],变分自动编码器VAE系列(Variational Automatic Encoder)、对抗生成网络GAN系列(Generation Adversarial Network)和扩散模型DM系列(Diffusion Model)。此中AI绘图以2020年的去噪扩散概率模型DDPM(Denoising Diffusion Probabilistic Model)为一个较大的里程碑,在此之前的生成模型主要以GAN居多。当下最火的开源AI绘画模型 Stable Diffusion 则为扩散模型,据悉 MidJourney 是变形注意力GAN的变体[1]。
人脸伪造检测(Face Forgery Detection)
特指包含涉及人脸相关内容生成的图片/视觉生成,例如AI换脸、人脸操控等;
人脸伪装图生成
了解人脸伪装检测技术前,需要先了解人脸造假图片生成的技术有哪些,分歧的生成技术/场景可能有分歧的检测方式。基于论文ForgeryNet[2]中的内容,人脸伪装图片生成的相关方式(截止2021年前)可以总结如下:
img
此中,StarGAN2-BlendFace-Stack (SBS), DeepFakes-StarGAN2-Stack (DSS)
人脸伪装图按照身份信息是否更改划分为身份信息不变类和身份替换类。
身份不变类伪造图在图片改削/生成时不改削图片中人物的身份信息,包罗:
- 人脸编纂:编纂人脸的外部下性,如春秋、性别或种族等。
- 人脸再制定:保留源主体的身份,但独霸其口部或表情等固有属性;
身份替换类伪造图在图片改削时同时改变此中人的身份信息:
- 人脸转移:它将源脸部的身份感知和身份不相关的内容(例如表情和姿势)转移到方针脸部,换脸也换表情等等,相当于把本身脸贴在别人的头上;
- 换脸:它将源脸部的身份信息转移到方针脸部,同时保留身份不相关的内容。即换脸,但不换表情,本身的脸在别人脸上做不变的事情;
- 人脸堆叠操作(FSM):指一些方式的调集,此中部门方式将方针图的身份和属性转移到源图上,而其他方式例在转移身份后改削交换后图的属性,多种方式的复合;
伪造图检测方式
本部门主要为相关查抄方式的部门论文简介。
【综述】GAN-generated Faces Detection: A Survey and New Perspectives
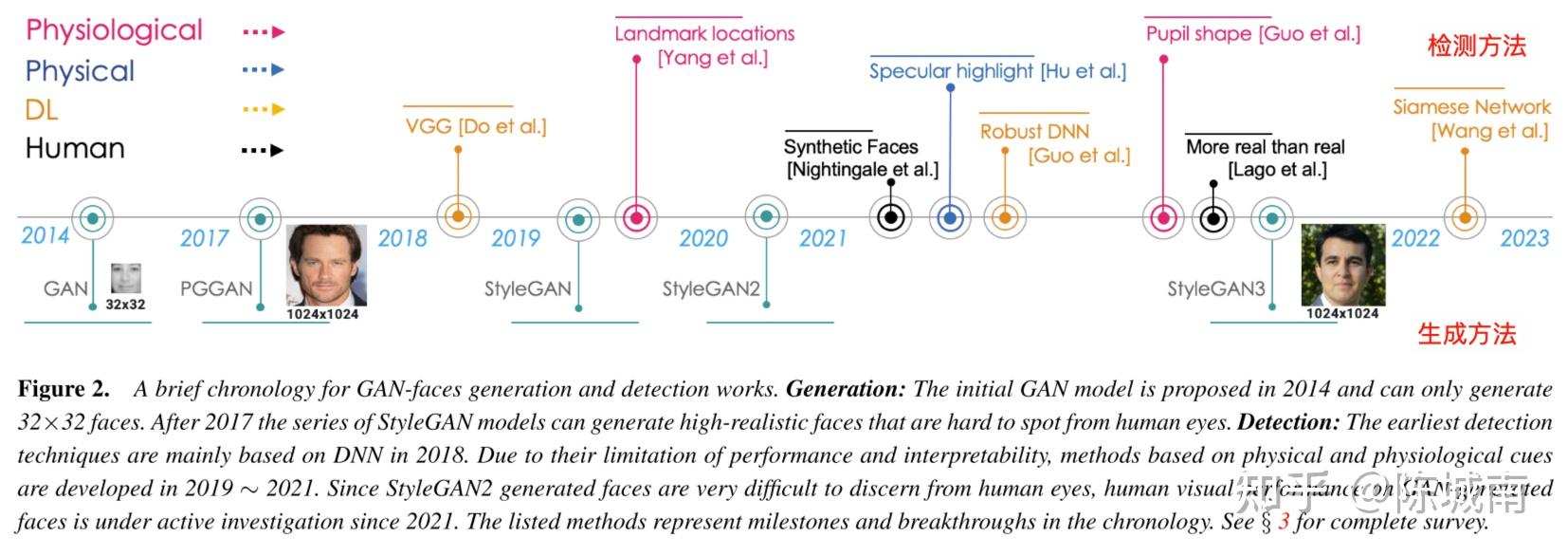
img
Arxiv 2023 工作,介绍了DL方式、物理学方式(Physical-based Methods)、生理学方式(Physiological-based Methods)的检测方式,同时给出了分歧生成模型的时间线(上图)。文章指出按照调研显示,GAN-face此刻AI检测性能高于人,因为有些图一眼看过去非常真,人的识别准确率也只有50%~60%。在这三类方式中
- DL方式的图片识别(分类)可解释性不太行,如果人看不出来,AI识别出来但又没有原因,斗劲难解释;
- 基于物理的方式通过寻找人工信息或面部与物理世界之间的纷歧致,例如透视中的照明和反射,来识别gan-face;
- 基于生理学的方式研究人脸的语义方面[14],包罗对称性、虹膜颜色、瞳孔形状等线索,此中识此外伪像用于表露gan人脸。
- 作者还给出了归类的分歧方式及性能(如下),但我分析后发现这个表存在不足:
- 作者在第3章提到的很多DL方式的成果没有呈此刻此表中;
- 该表格的测试集不统一,每个方式的成果不能与其他方式公平的斗劲,无法较高凸显性能优劣;
img
【音画分歧步】Not made for each other- Audio-Visual Dissonance-based Deepfake Detection and Localization
img
MM 2020 工作,针对虚假视频问题,作者给视频定义了模态掉调得分(Modality Dissonance Score, MDS) 来衡量其音画同步的程度。
- 视频支路 3D ResNet,独霸续视频切成n个Seg,每个Seg又有m个帧,最终颠末3D特征抽为 n 个特征;
- 音频支路 ,独霸续声音1-秒间隔转化为 MFCC特征(一种音频的热力图),然后同样是送入卷积网络得到n个音频特征。
- 然后两个特征进行对比学习,对于Fake video最大化纷歧致得分MDS,Real video最小化纷歧致得分MDS。此外还有分类损掉进行分类。
该方式太依靠同步信息了,很多网络延迟引起音画分歧步、或者视频中环境声较大的情况..都不能使用;
可检测场景:换脸、人脸独霸等;
【唇部变化识别】Lips Don't Lie: A Generalisable and Robust Approach to Face Forgery Detection
img
CVPR2021 工作,该文章也针对视频检测,操作唇部运动进行检测,是文章最大的亮点。
- 在lipreading任务上预训练CNN(freeze框内),作者称按照之前经验“在正常任务上训模型能提高模型对异常值(虚假)的敏感性”,事实上他的尝试证实了这一点,lipreading的预训练任务能大幅提升其成果;
- 在虚假检测(也就是假脸检测)任务上finetune 时空网络(我个人理解这里的时空网络其实就是一个多帧特征融合,直接用个Transformer应该效果一样甚至更优)
- 损掉用交叉熵做 2 分类;
预措置方面细节:
- 使用25帧图作为输入,使用RetinaFace[16]检测每一帧的脸,只提取最大的脸同时Crop 1.3 倍防止丢掉信息;
- 用FAN[15]计算脸部 landmarks 进行唇部的裁剪,同时还做了对齐,作为模型输入;
尝试:
- lipreading的预训练任务能大幅提升其成果
- 在其他数据集上泛化性也斗劲好,毕竟主要针对唇部还用其他模型做了对齐,泛化性好可以理解;
【削弱身份信息】Implicit Identity Leakage: The Stumbling Block to Improving Deepfake Detection Generalization
旷视科技的CVPR2023工作,开源在其官方github中,落地性应该有背书,属于训练复杂推理简单的。
凡是用一个二分类训deepfake模型时可能存在一个问题,模型会把身份信息也学到,导致在分辩fake图片时借用了id信息来辅助判决(比如某ID的脸都是真脸,模型通过记住ID来检测真假)。这些泄露的ID信息会在unseen数据上误导判决,这显然是不利于模型泛化的。作者将这一现象称为 隐式身份泄露(Implicit Idenetity Leakage)。
作者认为ID信息凡是是由全局信息反映的,局部特征斗劲难反映出这些信息(比如单独的嘴、鼻子等),因此为了防止“隐式身份泄露”,作者干了两件事:
- 提出人工伪装检测模型(Artifact Detection Module,ADM)来使模型聚焦于局部信息;
- 同时为了配合ADM训练,设计了多尺度的面部交换方式(Multi-scale Facial Swap,MFS)来生成具有分歧尺度的人工伪造信息(Artifact)的图片,增强数据集。
img
尝试效果:
- 比上面的 LipForensices 在 FF++ 数据集上鲁邦性效果好;
- 在FF++,Celeb-DF 上效果略优于 SBI[17]
【自监督对抗】Self-supervised Learning of Adversarial Example: Towards Good Generalizations for Deepfake Detection
img
CVPR 2022 工作,论文通过3个角度来提高检测器的泛化能力(A数据训 B数据集测),泛化能力也是论文的主要卖点。如上图,训练框架由 合成器G、图片合成 和 判别器 D 组成,形成对抗训练。
- 合成器:生成配置参数,用来合成更丰硕的自监督样本数据(注意是生成配置的参数)
- 原生假图:不措置,即不进入合成器,直接用来训判别器;
- 原生真图:不增广的真图不进入合成器,直接训判别器;
- 合成假图:有必然概率与一个随机图(Reference)进行增广,形成局部虚假的假图;
- 图片合成:合成器G会生成配置方案(区域选择10个;混合blending类型选择;以及合成比例选择ratio),基于此进行合成(即数据增广)
- 此中合成器输出区域的下标index,具体的区域需要操作 landmarks 网络生成该脸的 landmarks并进行拔取;
- 判别器G:对图片进行分类,同时添加辅助任务,用合成器的G的输出作为label
- 区域预测:分割Loss,label就是 landmarks 组成的掩码;
- Blending type:分类loss
- Blending ratio:L1距离loss;
因此,3个角度为:1. 合成数据,数据量大;2. 对抗训练,优化配置和判别器;3. 辅助任务且自监督;
其他可参考论文/项目
人脸伪装检测的论文太多了,上面总结的也只是此中一角,包含的类别也不够多。
AIG整图检测**(AI Generated-images Detection)**
检测一张图是否由AI生成,便是否为 VAE、GAN、扩散模型DM生成的图(后简称为VAE图、GAN图和DM图)。凡是这种判断是整图粒度的,但如果某个图的部门区域为生成图片,部门方式也是可以识此外。
本类识别生成图的方式大体上遵循一个整体的思路:将真实图(Real)和生成图(Fake)送到深度网络进行特征提取,并基于此构建一个二分类模型来进行最终的判断,细节差异在于:
- 模型分歧。分歧的方式采用分歧的模型提取真实图/生成图的特征,从而性能分歧。
- 特征分歧。分歧的方式使用分歧的特征参与训练。
- 一些模型使用纯视觉信息区分真假图,包罗伪影[8][9]、混合边界[10]、全局纹理一致性[11]等;
- 一些模型引入图频率信息[12][13],通过额外的频率信息区分真假图;
- 一些模型通过重建待检测图来发现出产网络的固有属性[14],操作重建图和待检测图间的差异来训练模型进行判断,以获取更泛化的检测方式;
- 数据分歧。
- 一些方式通过对抗手段生成更hard的图片,从而增强模型识别能力;
目前这些大部门方式均有一个共同的不足:跨模型检测泛化性差。具体来说,训练集中的生成图(Fake)由特定的生成器G发生,检测器在检测同为生成器G生成的图片时表示很好,而对于新生成器生成的图片检测器表示会差很多。
- 举例说明:此刻有图片生成器GAN-1,生成了一批数据Data-1参与检测器Det的训练,则Det在GAN-1的另一批数据Data-1'上表示会很好。可是如果有新的出产器GAN-2或者DM-1发生数据Data-2,在Det对Data-2的检测性能就会差很多。
GAN图识别
在扩散模型呈现之前,检测方式大多是针对GAN图的。
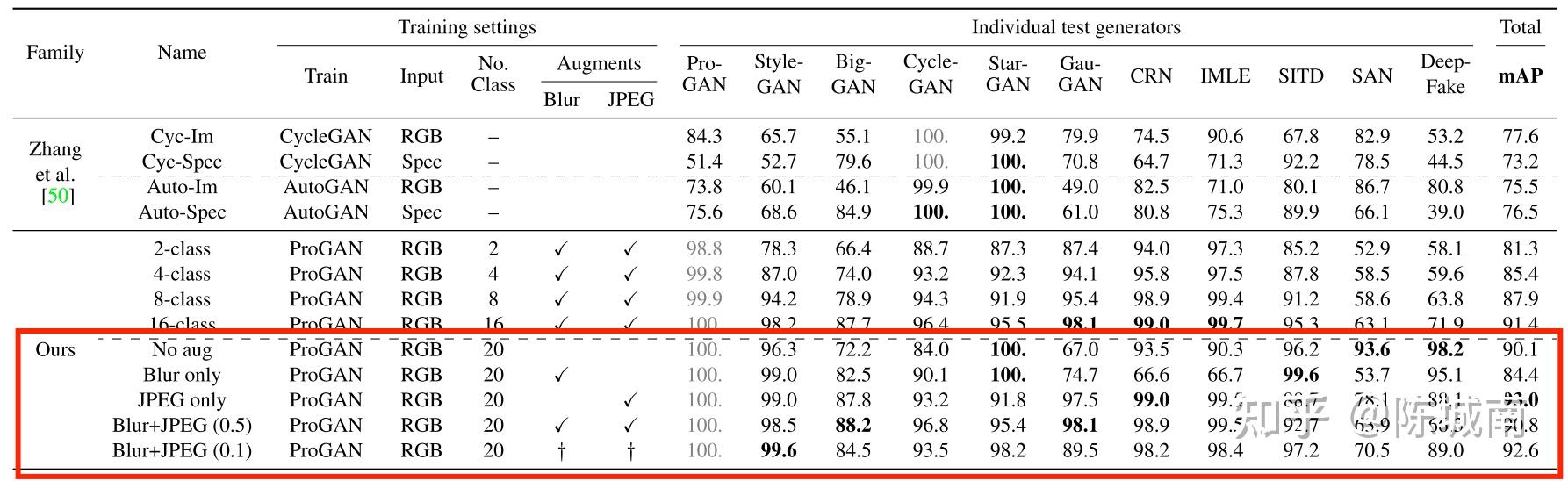
【二分类】CNNDetection: CNN-Generated Images Are Surprisingly Easy to Spot.. For Now
CVPR 2020工作(github) Baseline方式
该方式使用最朴素的二分类网络训练思路构建了一个“universial”检测器,在分歧的网络布局上均能取得较好的成果,具体的:
- 二分类网络为 ResNet50;
- 训练集使用ProGAN进行图片生成,为了凸显其对分歧布局的泛化性,测试集使用了 ProGAN,StyleGAN,BigGAN,Deepfakse等11个网络的生成图片。
- 数据增广使用了 无增广、高斯模型、JPEG压缩和模糊+JPEG压缩等多个增广。
img
通过尝试证明:
- 数据增广凡是能有效提高检测器泛化性和鲁邦性;
- 高斯模糊可能会掉点,比如SAN(超分辩模型)的生成图中高频信息斗劲重要,使用高斯模糊的训练集会降低检测器对高频信息的获取,则效果变差。
- 在构建训练集时,更丰硕数据多样性能提高检测器的能力;
【二分类plus】Are Gan Generated Images Easy To Detect? A Critical Analysis of the State-of-the-Art
ICME 2021,Github
该方式延续了CNNDetection中的思路对现有的检测方式进行了分析,在其基础上,
- 将ResNet50改为 XceptionNet 和 Efficient-B4;
- 对 XceptionNet 和 EffectionNet 不进行第一个Down-sampling的Trick,简称No-down,这个trick对性能提升挺大的(论文中称这个idea引用自steganalysis问题,“to preserve features related to noise residual, it performs no down-sampling in the first layers of the network”, 在我看来其实是从网络最初去掉了一个降采样,增大了特征图的大小,细粒度特征更多)。
【频率特征】BiHPF: Bilateral High-Pass Filters for Robust Deepfake Detection
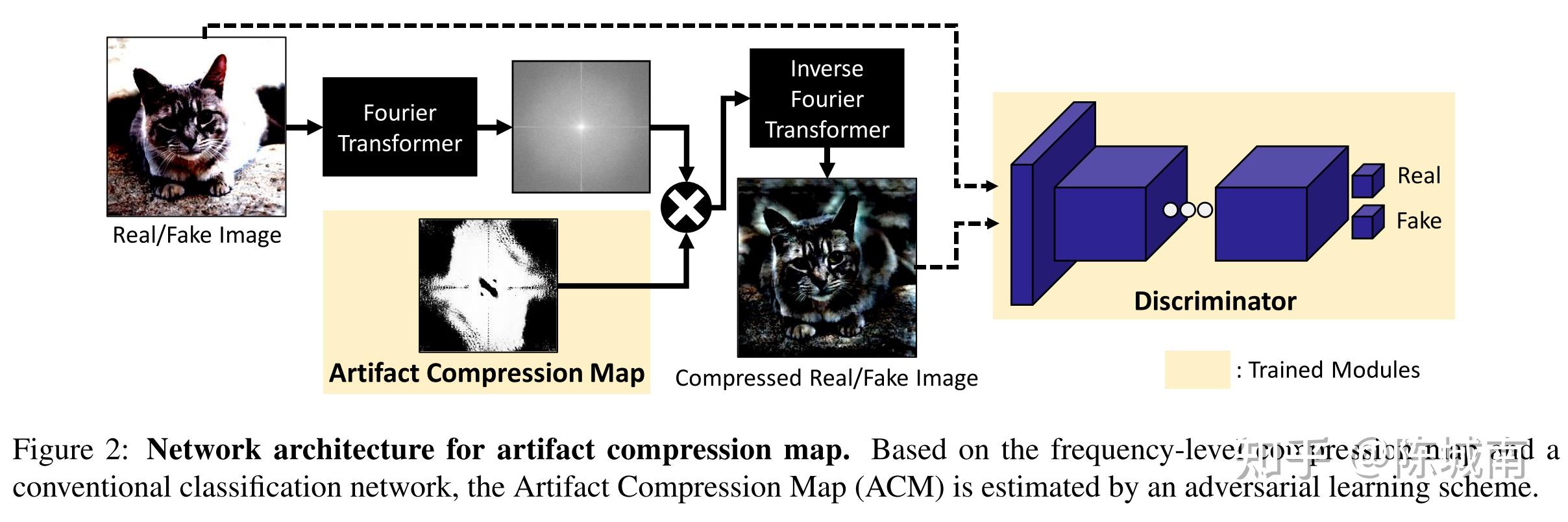

WACV 2022 工作
作者认为频率空间也有人工信息,并构建了上述模型进行人工信息提取和证明。
- 操作可学习的人工压缩映射(ACM)模块压缩频率空间的人工信息,与判别器组成对抗学习进行训练,最终训练好的ACM就能提取出伪影区域。
- 通过分析,作者得出结论:伪影在高频分量中有很大的幅度;伪影位于图像的周围布景,而不是中心区域;
基于这些分析,作者提出 双边机制高通滤波器(BiHPF) 对原图进行措置,它能放大了生成模型合成图像中常见的频率级伪影的影响。BiHPF由两个高通滤波器(HPF)组成:
- 频率级HPF用于放大高频分量中伪像的幅度;
- 像素级HPF用于在像素主体中强调周围布景中的像素值。
最终将措置后的增强图片进行分类训练。
【频率扰动】FrepGAN: Robust deepfake detection using frequency-level perturbations
AAAI 2022 工作
作者发现**忽略频率的人工信息能提供检测模型对分歧GAN模型的泛化能力,**而直接训一个分类器容易对训练集过拟合,所以要在训练集上做频率扰动;
img
- 核心思路是在Fake图片生成时,同时让频率信息参与,这样生成图的频率就被扰动了,并用此来训练检测分类器。检测分类器从而提高对频率的抗干扰能力。
- 频率扰动生成器G:让频率信息参与图片生成。具体来说,输入图片 x 颠末快速傅里叶变换(Fast Fourier Transform, FFT)得到 x~,其size为hw2c,通道数为2倍。通过一个image-to-image的生成器H,得到输出z~,再颠末逆FFT。通过这种方式,频率信息在生成时也被考虑,生成图G(x)(称为扰动特征图)就具有频率信息。整体的频率扰动生成器为:
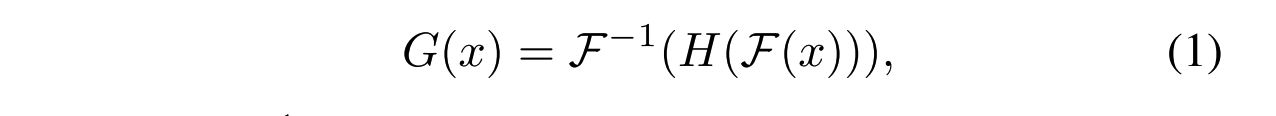
img
- 扰动判别器D(Perturbation Discriminator):尺度的对抗生成思路,用来强化G(x)假图,使其生成的图片不能被识别出来,这样的话频率信息参与了生成,但生成的图与真实图无法被视觉区分。
- 检测识别器C:让图片x和其扰动特征G(x)一起当做输入进行二分类,这样频率信息就能被考虑进去并忽略。
【梯度特征】Learning on Gradients: Generalized Artifacts Representation for GAN-Generated Images Detection
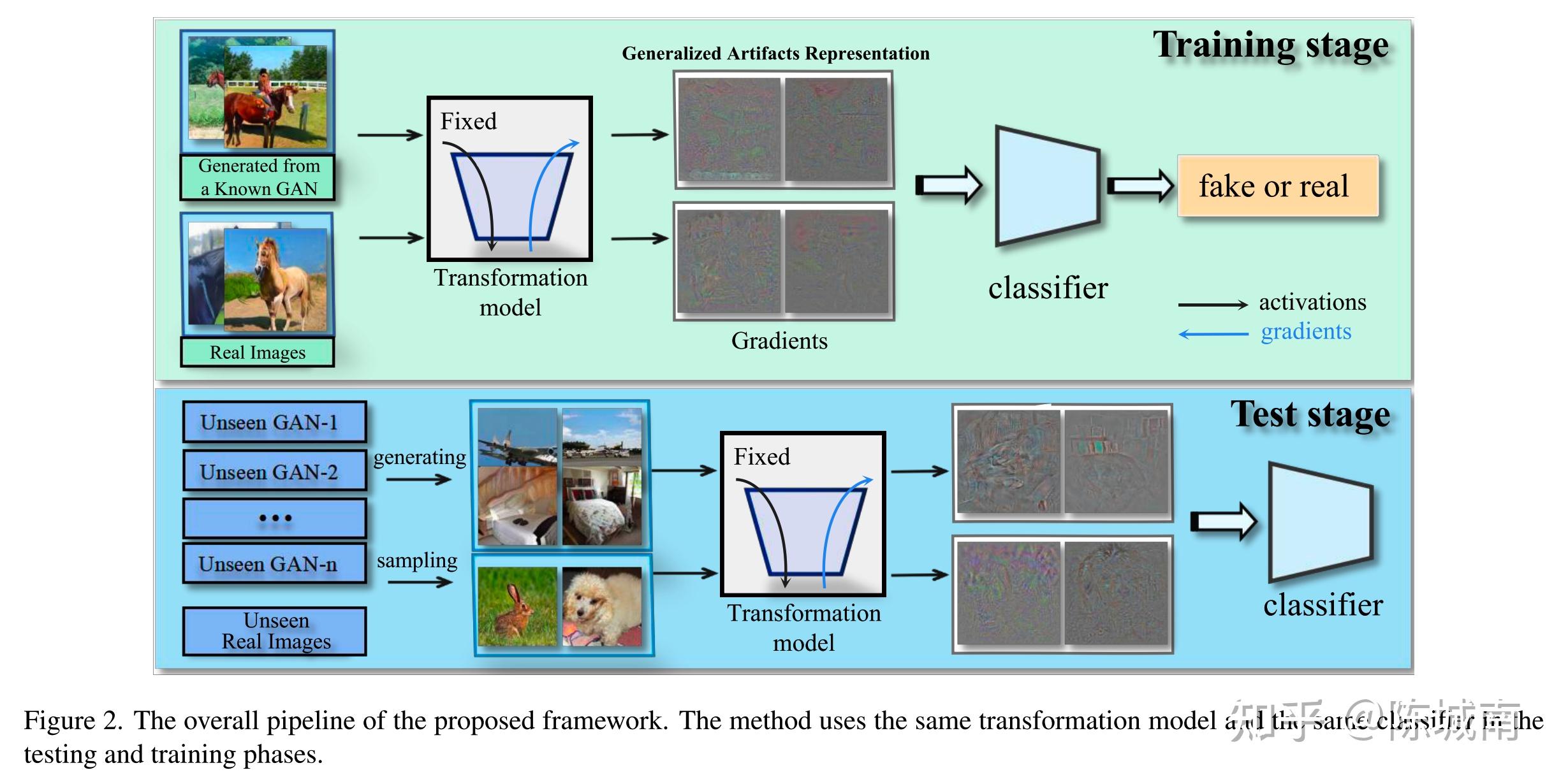
img
CVPR2023,Github
- 使用Transformation model (转换模型,预训练的CNN模型,各种现有的模型都行,VGG,ResNet50,ProGAN的判别器,StyleGAN等等)将图片转化为梯度图,作为该图的人工特征;
- 将梯度图送进分类器进行分类训练,判断其是否伪造;
跨模型能力对比
img
- Wang42是CNNDetection 2分类,比起纯2分类要好很多,也比频率方式也好。
- 此中StyleGAN-badroom作为转换模型最优;
TransformationModel对比
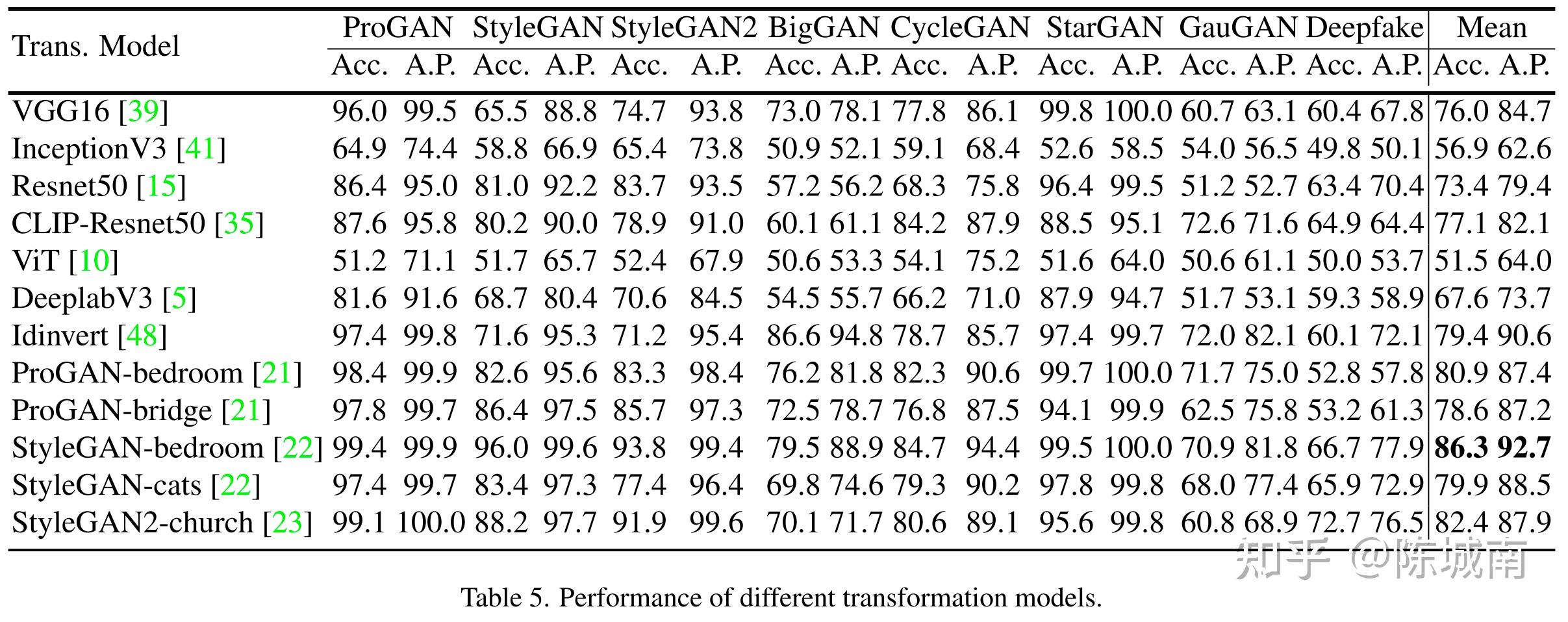
img
TransModel使用分歧模型效果纷歧样,StyleGAN-Bedroom相对最优;
DM图识别
扩散模型的生成图识别属于探索阶段,偏探索性的论文也较多。
【DM图与GAN图检测可行性分析】Towards the Detection of Diffusion Model Deepfakes
ICLR 2023 在投,Github
这篇文章作者探索了之前的GAN识别方式(CNNDetection, Grag[4] 等模型)能否用于 DM 模型图的识别,是否有统一的检测器可以识别两种模型生成的图:
- 使用的数据集是LSUN Bedroom[6],包罗卧室(Bedroom)、客厅(Living Room)、餐厅(Dining Room)、办公室(Office)、厨房(Kitchen)、街景(Street View)等场景。
- 测了5个GAN和5个DM模型,发现GAN上的模型直接用在DM模型的图上检测效果会变差很多,但Finetune一下性能就会恢复;
- 对比于GAN图,DM图在频率人工信息更少;
- DM图识别比GAN图识别更难;
【DM图检测分析】On the detection of synthetic images generated by diffusion models
Arxiv 2023,Github
该文章也是做检测分析的,通过频域分析、模型检测能力分析(将之前GAN识此外CNNDetection[3]模型和 Grag[4] 模型用于 DM检测,当做鲁邦的二分类进行)。论文通过尝试分析认为:
- 不异网络布局生成的图片有相似的陈迹(比如DM图的暗影和反射不合错误称等等),这些陈迹有些在空间域可以发现;
- 通过对现有的12个检测器进行训练和测试(真实数据源自COCO、ImageNet和UCID;合成图来自COCO的langage prompts使用ProGAN生成),成果表白现有模型的泛化性能依然有限,比如在DM上训,在DM的图上测试,效果还可以,但跨模型测就不行了。
- 此外,如果图片颠末二次措置(比如压缩等社交媒体的变换),这些生成图就更难判断了,因为压缩会损掉一些陈迹(比如高频信息等)。
作者还用了一些训练方式(Platt scaling method [34]),在多模型融合基础上,比单个模型性能要好。在作者测试的几个模型中,Grag2021[4]单模型最优(使用了No-down ResNet);这些篡改模型部门来自于IEEE VIP Cup [5]比赛。
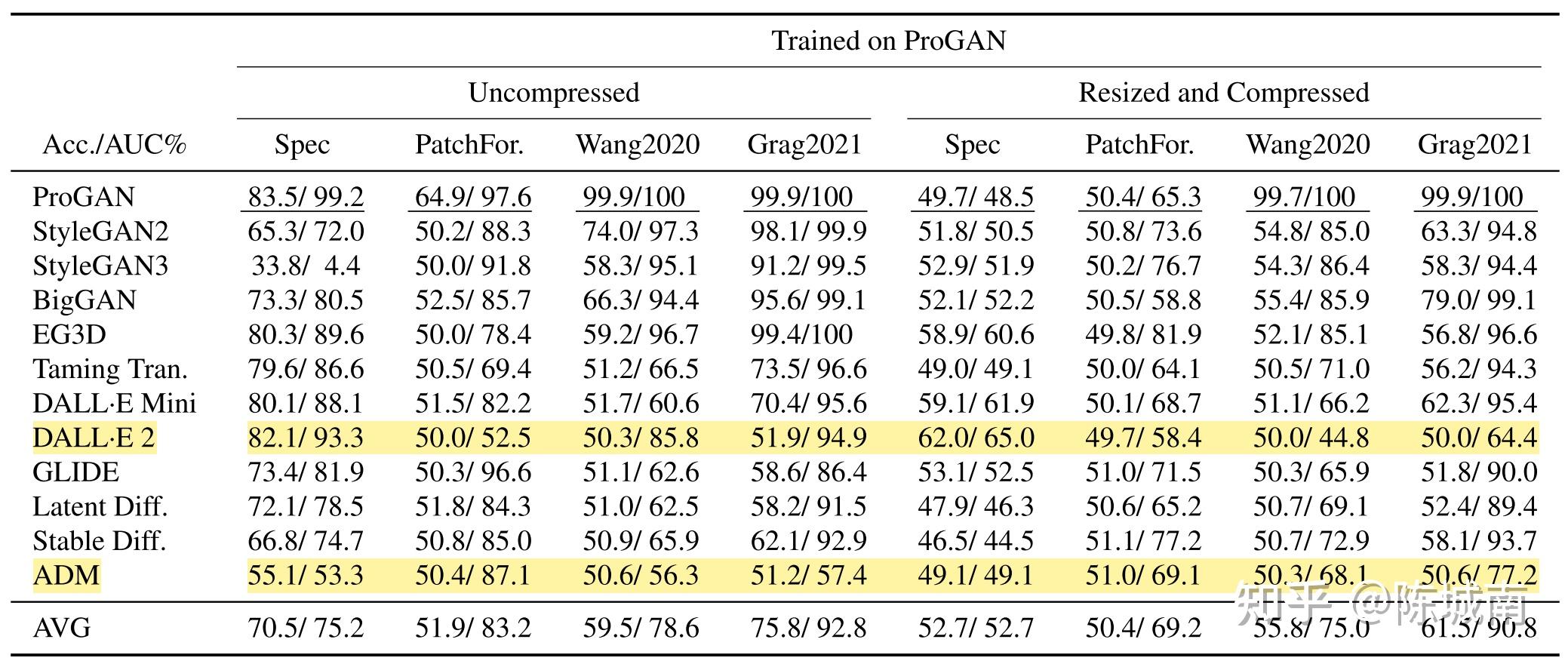
img
- ProGAN上训,跨模型测,发此刻众多模型中,DALL·E 2 和 ADM 的泛化能力最差。这一难度也从频域的指纹分析上可以看出,ADM和DALL · E 2 的频率特征与其他模型的分歧最大。
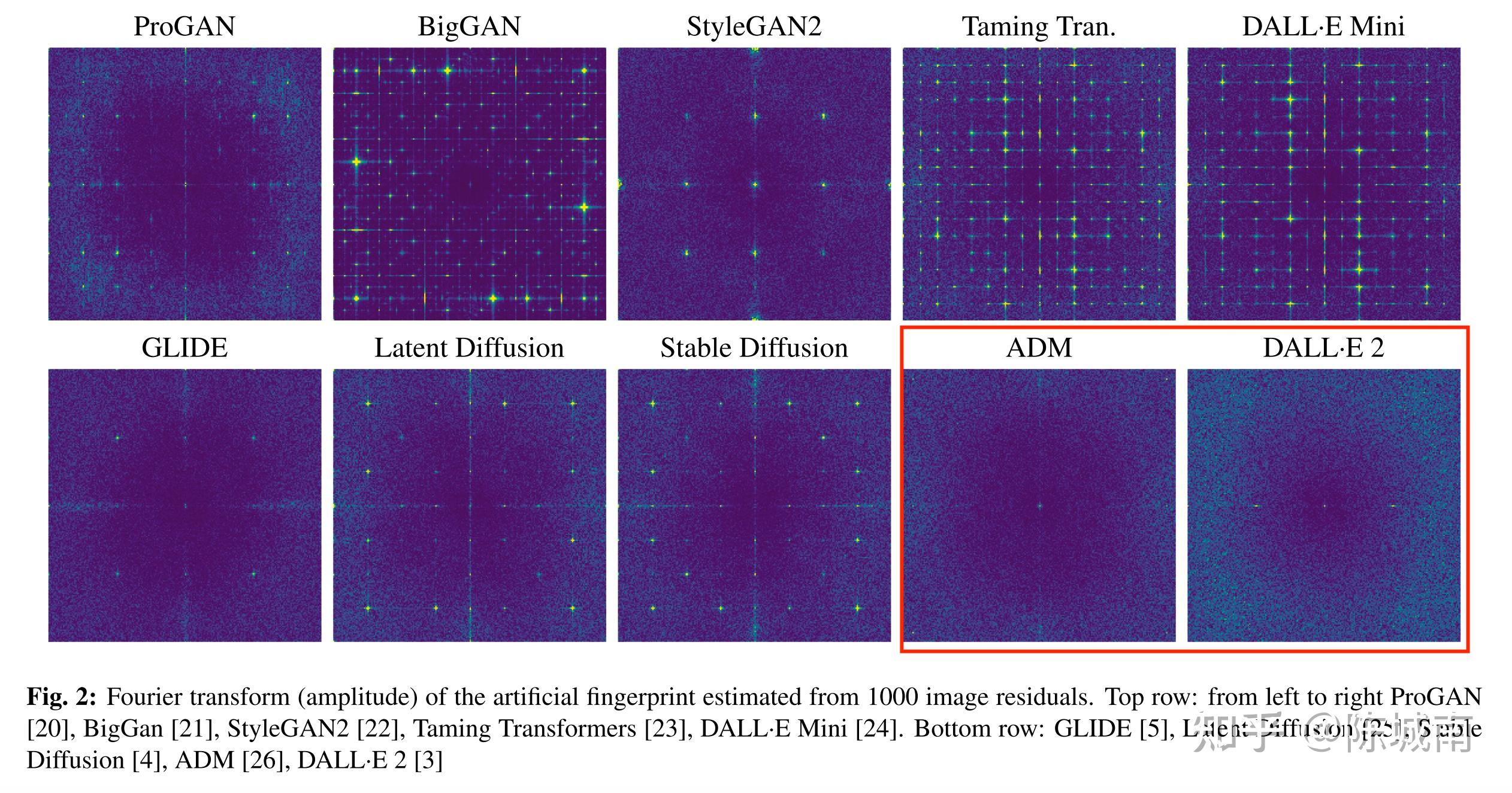
img
【误差特征】DIRE for Diffusion-Generated Image Detection
Arxiv 2023
作者发现DM 图可以被近似地被扩散模型重建,但真实图片不行。将重建图和原图的图片差异记为扩散重建差(DIffusion Reconstruction Error,DIRE),则DIRE可以作为特征进行2分类训练,判断是否虚假,泛化性会高很多;
重建图像差DIRE可以区分真实图和合成图的原因如下图:
- 合成图在重建后变化往往较小;
- 真实图在重建后变化相对较大;
我得理解是,真实图在重建时会丢掉很多信息,而生成图由于本身就是模型生成的,重建时信息变化相对不大。因此差异可以反映其真假。

该方式通过预训练的扩散模型(Denoising Diffusion Implicit Models,DDIMs[7])对图片进程重建,测量输入图像与重建图像之间的误差。其实这个方式和上面梯度特征的方式LGrad很像,区别在于上面是通过 Transformation Model转换模型获得图像梯度,这里通过 DDIM 重建图计算差。
此外,作者提出了一个数据集 DiffusionForensics,同时复现了8个扩散模型对提出方式进行识别(ADM、DDPM、iDDPM, PNDM, LDM, SD-v1, SD-v2, VQ-Diffusion);
- 跨模型泛化较好:比如ADM的DIRE 对 StyleGAN 也撑持,
- 跨数据集泛化:LSUN-B训练模型在ImageNet上也很好;
- 抗扰动较好:对JPEG压缩 和 高斯模糊的图,性能很好;
最后看下尝试指标,看起来在扩散模型上效果很好,这ACC/AP都挺高的,不知道在GAN图上效果如何。
img
其他可参考论文/项目
其他类型假图检测(Others types of Fake Image Detection)
- 社交媒体中发的篡改图:Robust Image Forgery Detection Against Transmission Over Online Social Networks, CVPR 2022: Paper Github
- 通用图片造假检测(局部造假等):Hierarchical Fine-Grained Image Forgery Detection and Localization, CVPR 2023: Paper Github
Reference
[0] AIGC图像生成模型成长与高潜标的目的
[1] 绘图软件midjourney的底层模型是什么? - 互联网前沿资讯的回答 - 知乎 https://www.zhihu.com/question/585975898/answer/3013595427
[2] ForgeryNet: A Versatile Benchmark for Comprehensive Forgery Analysis
[3] CNNDetection: CNN-Generated Images Are Surprisingly Easy to Spot.. For Now
[4] D. Gragnaniello, D. Cozzolino, F. Marra, G. Poggi, and L. Ver- doliva, “Are GAN generated images easy to detect? A critical analysis of the state-of-the-art,” in IEEE ICME, 2021.
[5] R Corvi, D. Cozzolino, K. Nagano, and L. Verdoliva, “IEEE Video and Image Processing Cup,” https://grip-unina.github.io/vipcup2022/, 2022.
[6] Yu, F., Seff, A., Zhang, Y., Song, S., Funkhouser, T., and Xiao, J. LSUN: Construction of a large-scale image dataset using deep learning with humans in the loop, June 2016.
[7] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020.
[8] Lucy Chai, David Bau, Ser-Nam Lim, and Phillip Isola. What makes fake images detectable? understanding prop- erties that generalize. In European conference on computer vision, pages 103–120. Springer, 2020.
[9] Ning Yu, Larry S Davis, and Mario Fritz. Attributing fake images to gans: Learning and analyzing gan fingerprints. In Proceedings of the IEEE/CVF international conference on computer vision, pages 7556–7566, 2019.
[10] Lingzhi Li, Jianmin Bao, Ting Zhang, Hao Yang, Dong Chen, FangWen, and Baining Guo. Face x-ray for more general face forgery detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5001–5010, 2020.
[11] Zhengzhe Liu, Xiaojuan Qi, and Philip HS Torr. Global texture enhancement for fake face detection in the wild. In Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8060–8069, 2020.
[12] Yonghyun Jeong, Doyeon Kim, Youngmin Ro, and Jongwon Choi. Frepgan: Robust deepfake detection using frequency-level perturbations. arXiv preprint arXiv:2202.03347, 2022.
[13] FrepGAN: Robust deepfake detection using frequency-level perturbations
[14] DIRE for Diffusion-Generated Image Detection
[15] Adrian Bulat and Georgios Tzimiropoulos. How far are we from solving the 2d & 3d face alignment problem?(and a dataset of 230,000 3d facial landmarks). In Proceedings of the IEEE International Conference on Computer Vision, pages 1021–1030, 2017.
[16] Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kot- sia, and Stefanos Zafeiriou. Retinaface: Single-shot multi-level face localisation in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5203–5212, 2020.
[17] Detecting Deepfakes with Self-Blended Images |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
×
|

 发表于 2023-8-5 10:14:46
发表于 2023-8-5 10:14:46
 变色卡
变色卡