假如你对 ChatGPT 和 AIGC 感兴趣,欢迎存眷华妹聊AI,华妹将持续分享 AIGC 系列相关的干货文章。
<hr/>前两周 AI 范围的当红辣子鸡,毫无疑问是 ChatGPT,但在 ChatGPT 一波又一波刷屏的背后,你可能错过了一场本年典中典的 AI 诈骗案。
是的,AI 还没来得及改变普通人的生活,却已经改变了割韭菜的生财姿势。。。
这事相当具有戏剧性,起初,网上传布了一场 Party 的宣传海报,四个大字,「女仆之夜」。
这种活动本来没啥诧异的,哪怕 3000 元/位的入场费,也不能让活动本身更出彩,除非,它不三不四。
没错,女仆之夜的活动,哪能没有女仆呢,这个 Part 最大的亮点,在于为每一位参与者,都配备有随身陪玩女仆一名。
更附带了 43 张女仆小姐姐的「照片」:
大师不用猜了游艇女仆趴的大结局了,因为活动本身就是一场闹剧,这 43 张照片全部都是 AI 绘画赋能的产物。
好家伙,过去诈骗是 P 图变脸,此刻诈骗直接无中生有,比九转大肠绕绕还多,但我对 AI 绘画的印象还逗留在去年的二次元涩涩上,此刻怎么都进军真人了?
本着当真负责的态度,我决定一探此刻 AI 绘图的究竟,这两天在我看了大量 AI 涩绘图的基础上,终于顺藤摸瓜理清了此次 AI 绘图大变样的节点。
虽然还没跑起来,但我想着独乐乐不如众乐乐,先给大师复盘一下 AI 绘画是怎么开始画照片的。
PS:多图预警,请在 WIFI 下不雅观看。
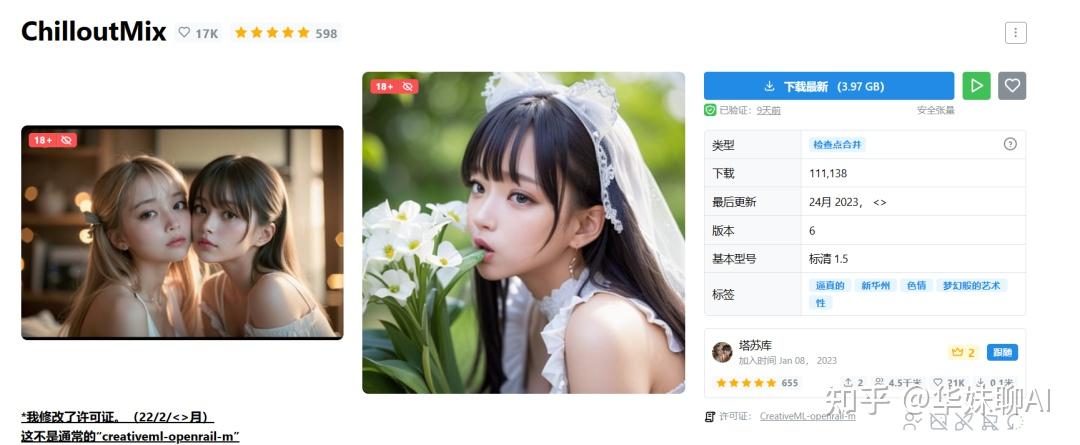
Chilloutmix
本年二月初,各大网络社区,包罗不限于微博、贴吧、NGA、小红书、推特、油管,都开始呈现真人风格,质量极高的 AI 绘制的作品。
此中最出圈的,概略是微博上 @勘云工造 大佬制作的赛博 Coser 系列,放几张这两天网上疯传,很多人估计都眼熟了的作品:
这个身材傲人,装扮精致的小姐姐图片,无论光影,还是面部细节,亦或衣服褶皱,都算得上真实,妥妥的美女 Coser。
但你品一品这作图风格,是不是和前面阿谁游艇女仆趴有点像?嘿,因为这些图啊,都是基于一个模型实现的,也就是 ChilloutMix。
至于为啥 AI 画照片都扎堆呈此刻了 2 月?无他,ChilloutMix 这个模型是 2 月初登录在了 AI 绘画模型分享社区 C 站(CivitAI)。
不到 1 个月的时间,这个模型就已经拥有了 11 万的下载量。
在 C 站里,有各种基于这个模型跑出来的「照片」。
偷偷说一句,如果你在 C 站搜这个模型,需要在设置里开启 adult 模式(成人模式),因为 Chilloutmix 除了正经出图,还能直接产出 NSFW 内容。
不外有一说一啊,Chilloutmix 模型并不是 AI 绘图从 0 到 1 的打破,而是基于多个开源的 Stable Diffusion 衍生模型实现的。
展开讲就全是模型介绍了,小白也能看懂的说法是,Chilloutmix 是一个集大成的写实风模型,用分歧指令调用分歧模型的专精标的目的,就能生成这么一张以假乱真的图片了。
等等,AI 绘图应该是风格附近,样子各异才对,Chilloutmix 当然也不例外,网上的大佬们是怎么让 AI 持续生成同一副面孔的套图呢?
一句话,微软的功劳。 LoRa
就像前面说的那样,AIGC 的背后是一个又一个被提前训练好的模型,这些模型决定了生成内容的整体走向。
但是,模型是成果也是桎梏,就像焊好的手机没法子单独只换个芯片,想让模型跑出纷歧样的风格,只有从头训练。
早在 2021 年的时候,微软搞大语言模型时就发现了这一点,并提了个微调的解决方案:LoRa。
具体什么意思呢?不用再去从头训练大模型了,直接打补丁,把单独训练好的模块拿来覆盖原先的模型参数,达到不变产出的效果。
而 LoRa 这项技术于去年底,被应用到了 AI 绘图上,也就是说只要搭配微调好的 LoRa 模型,就可以轻松固定 AI 绘图时的人物形象。
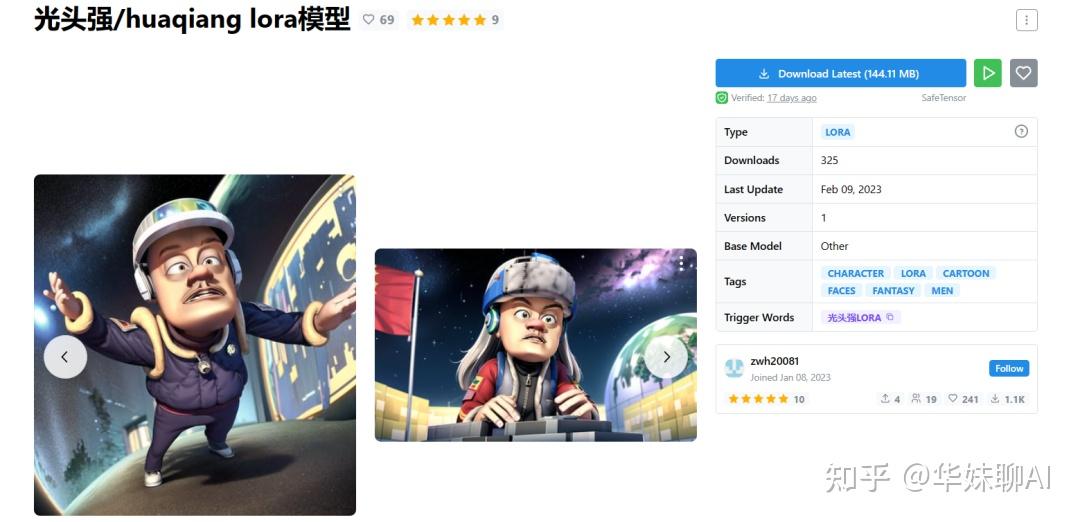
这么搞,AI 绘图的自由度一下子就丰硕起来了,举几个例子,以光头强图集训练好的 LoRa 模型:
就可以跑出光头强的效果,当然了,具体内容还要看你的描述语。
那用深田咏美老师的 LoRa 模型呢?
跑出的,自然也是深田老师的样子。
说真的,这样的模型有太多太多了,并不局限于写实的真人,如果你比来刷到了神似谁谁谁的 AI 二创,要么是本身训练跑出来的模型,要么是从 C 站上下载的 LoRa 模型。
怪不得 AI 绘画能被用于诈骗,这看了谁不迷糊啊。。。
不外我盲猜,这个时候必定会有小伙伴说,AI 绘画看手啊,这是 AI 的盲区。
确实,现阶段手对于 AI 来说仿佛是 bug 一般的存在,但未来,真不好说。
比来 AI 绘图圈又有了船新打破:ControlNet 模型。 ControlNet
同样是微调,但它能让 AI 输出更加精细,举个火爆推特的例子,这是一张普普通通的合照。
但在 ControlNet 的加持下,可以生成这样的效果:
发现亮点没有,人物的姿势并没有发生什么变化,这就很牛。
以往的 AI 模型,你想让它生成分歧的姿势,必需要有具体的提示词,比如歪头、跑步等等。
但很多时候,AI 不必然能正确理解,因为模型本身是有惯性的,会更方向于拿来训练的图集。
ControlNet 牛在什么处所,它能更精准的控制人物的整体布局和构图细节,此中就包罗了手部姿势。
不免感慨,在短短半年的时间里,AI 绘图的成长实在是太快了,快到感觉和我以前把玩过的 AI 绘图不是一个东西。
总说 AI 会代替代替谁,但当你了解的越多,你会感觉一开始可能它降低了门槛,但从某个时候起,它又增加了门槛。
这篇纯粹是个吃瓜,不外等我整理好了资料,再来和大师分享玩法,等不及的小伙伴可以多去 B 站搜搜教程。
保举一位 B 站的秋叶大佬,@秋叶aaaki。

 发表于 2023-7-7 18:02:30
发表于 2023-7-7 18:02:30









 变色卡
变色卡