|
|
 发表于 2023-6-28 09:43:21
|
显示全部楼层
发表于 2023-6-28 09:43:21
|
显示全部楼层
前言
这篇文章的主要内容是,解读 AlphaTensor 这篇论文的主要思想,如何通过强化学习来探索发现更高效的矩阵乘算法。
1、二进制加法和乘法
这一节简单介绍一下计算机是怎么实现加法和乘法的。
以 2 + 5 和 2 * 5 为例。
我们知道数字在计算机中是以二进制形式表示的。
整数2的二进制表示为: 0010
整数5的二进制表示为: 0101
1.1、二进制加法
二进制加法很简单,也就是两个二进制数按位相加,如下图所示:
当然具体到硬件实现其实是包含了异或运算和与运算,具体细节可以阅读文末参考的资料。
1.2、二进制乘法
二进制乘法其实也是通过二进制加法来实现的,如下图所示:
乘法在硬件上的实现本质是移位相加。
对于二进制数来说乘数和被乘数的每一位非0即1。
所以相当于乘数中的每一位从低位到高位,分别和被乘数的每一位进行与运算并产生其相应的局部乘积,再将这些局部乘积左移一位与上次的和相加。
从乘数的最低位开始:
若为1,则复制被乘数,并左移一位与上一次的和相加;
若为0,则直接将0左移一位与上一次的和相加;
如此循环至乘数的最高位。
从二进制乘法的实现也可以看出来,加法比乘法操作要快。
1.3、用加法替换乘法的简单例子
上面这个公式相信大家都很熟悉了,式子两边是等价的
左边包含了2次乘法和1次加法(减法也可以看成加法)
右边则包含了1次乘法和2次加法
可以看到通过数学上的等价变换,增加了加法的次数同时减少了乘法的次数。
2、矩阵乘算法
对于两个大小分别为 Q x R 和 R x P 的矩阵相乘,通用的实现就需要 Q * P * R 次乘法操作(输出矩阵大小 Q x P,总共 Q * P 个元素,每个元素计算需要 R 次乘法操作)。
根据前面 1.2内容可知,乘法比加法慢,所以如果能减少的乘法次数就能有效加速矩阵乘的运算。
2.1、通用矩阵乘算法
首先来看一下通用的矩阵乘算法:
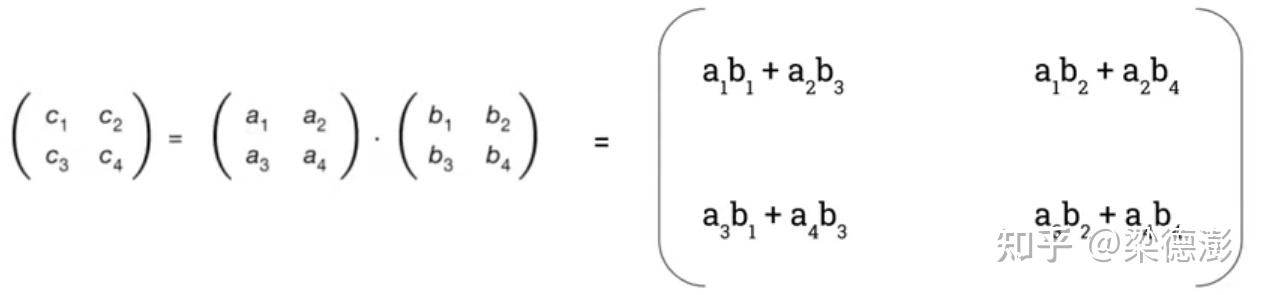
如上图所示,两个大小为2x2矩阵做乘法,总共需要8次乘法和4次加法。
2.2、Strassen 矩阵乘算法
上图所示即为 Strassen 矩阵乘算法,和通用矩阵乘算法不一样的地方是,引入了7个中间变量 m,只有在计算这7个中间变量才会用到乘法。
简单用 c1 验证一下:
可以看到 Strassen 算法总共包含7次乘法和18次加法,通过数学上的等价变换减少了1次乘法同时增加了14次加法。
3、AlphaTensor 核心思想解读
3.1、将矩阵乘表示为3维张量
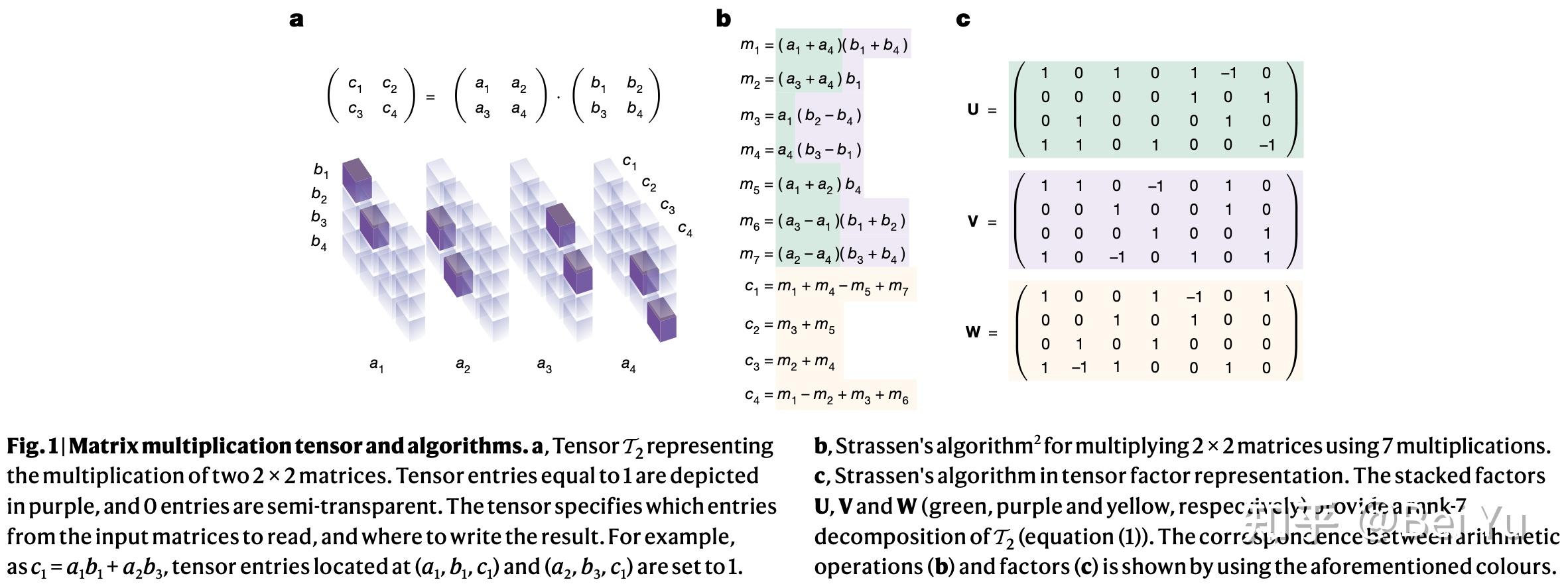
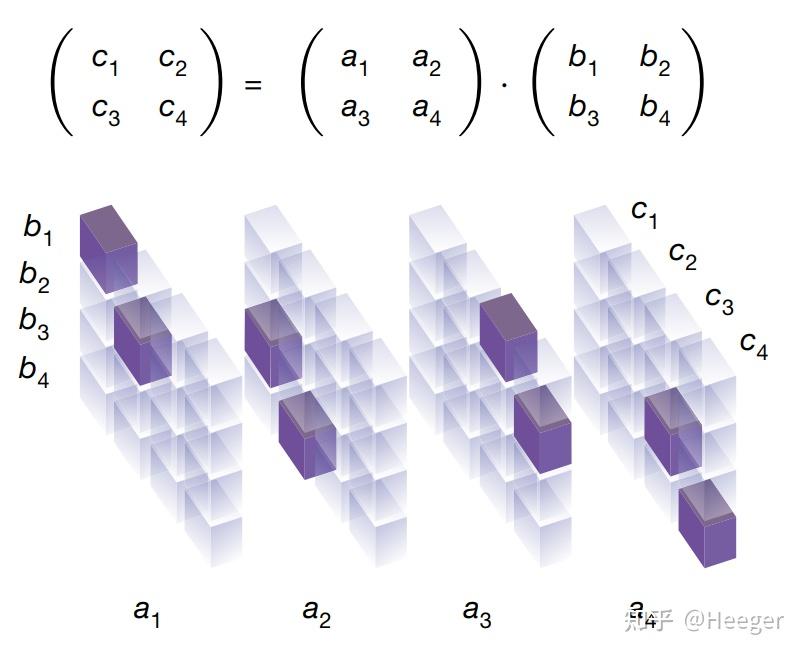
首先来看下论文中的一张图
图中下方是3维张量,每个立方体表示3维张量一个坐标点。
其中张量每个位置的值只能是 0 或者 1,透明的立方体表示 0,紫色的立方体表示 1。
现在将图简化一下,以[a,b,c]这样的维度顺序,将张量以维度a平摊开,这样更容易理解:
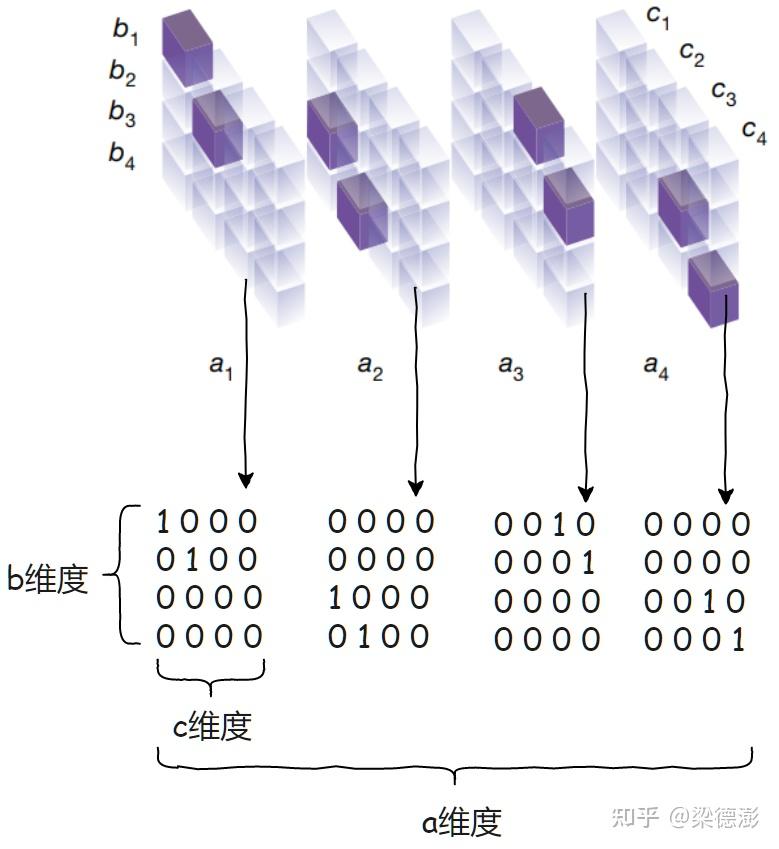
这个3维张量怎么理解呢?
比如对于 c1,我们知道 c1 的计算需要用到 a1,a2,b1,b3,对应到3维张量就是:
而从上图可知,对于两个 2 x 2 的矩阵相乘,3维张量大小为 4 x 4 x 4。
一般的,对于两个 n x n 的矩阵相乘,3维张量大小为 n^2 x n^2 x n^2。
更一般的,对于两个 n x m 和 m x p 的矩阵相乘,3维张量大小为 n*m x m*p x n*p。
然后论文中为了简化理解,都是以 n x n 矩阵乘来讲解的,论文中以
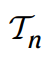
表示 n x n 矩阵乘的3维张量,下文中为了方便写作以 Tn 来表示。
3.2、3维张量分解
然后论文中提出了一个假设:
如果能将3维张量 Tn 分解为 R 个秩1的3维张量(R rank-one terms)的和的话,那么对于任意的 n x n 矩阵乘计算就只需要 R 次乘法。
如上图公式所示,就是表示的这个分解,其中的
就表示的一个秩1的3维张量,是由 u^(r) 、 v^(r) 和 w^(r) 这3个一维向量做外积得到的。
这具体怎么什么理解呢?我们回去看一下 Strassen 矩阵乘算法:
上图左边就是 Strassen 矩阵乘算法的计算过程,右边的 U,V 和 W 3个矩阵,各自分别对应左边 U -> a, V -> b 和 W -> m。
具体又怎么理解这三个矩阵呢?
我们在图上加一些标注来解释,其中 U , V 和 W 矩阵每一列从左到右按顺序,就对应上文提到的,u^(r) 、 v^(r) 和 w^(r) 这3个一维向量。
然后矩阵 U 每一列和 [a1,a2,a3,a4] 做内积,矩阵 V 每一列和 [b1,b2,b3,b4] 做内积,然后内积结果相乘就得到 [m1,m2,m3,m4,m5,m6,m7]了。
最后矩阵 W 每一行和 [m1,m2,m3,m4,m5,m6,m7] 做内积就得到 [c1,c2,c3,c4]。
接着再看一下的 U,V 和 W 这三个矩阵第一列的外积结果
如下图所示:
可以看到 U,V 和 W 三个矩阵每一列对应的外积的结果就是一个3维张量,那么这些3维张量全部加起来就会得到 Tn 么?下面我们来验证一下:

可以看到这些外积的结果全部加起来就恰好等于 Tn:
所以也就证实了开头的假设:
如果能将表示矩阵乘的3维张量 Tn 分解为 R 个秩1的3维张量(R rank-one terms)的和,那么对于任意的 n x n 矩阵乘计算就只需要 R 次乘法。
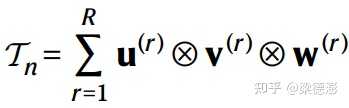
因此也就很自然的可以想到,如果能找到更优的张量分解,也就是让 R 更小的话,那么就相当于找到乘法次数更小的矩阵乘算法了。
通过强化学习探索更优的3维张量分解
将探索3维张量分解过程变成游戏
论文中是采用了强化学习这个框架,来探索对3维张量Tn的更优的分解。强化学习的环境是一个单玩家的游戏(a single-player game, TensorGame)。
首先定义这个游戏进行 t 步之后的状态为 St:
然后初始状态 S0 就设置为要分解的3维张量 Tn:
对于游戏中的每一步t,玩家(就是本论文提出的 AlphaTensor)会根据当前的状态选择下一步的行动,也就是通过生成新的三个一维向量从而得到新的秩1张量:
接着更新状态 St减去这个秩1张量:
玩家的目标就是,让最终状态 St=0同时尽量的减少游戏的步数。
当到达最终状态 St=0 之后,也就找到了3维张量Tn的一个分解了:
还有些细节是,对于玩家每一步的选择都是给一个 -1 的分数奖励,其实也很容易理解,也就是玩的步数越多,奖励越低,从而鼓励玩家用更少的步数完成游戏。
而且对于一维向量的生成,也做了限制
就是生成这些一维向量的值,只限定在比如 [−2, −1, 0, 1, 2] 这5个离散值之内。
AlphaTensor 简要解读
论文中是怎么说的,在游戏过程中玩家 AlphaTensor 是通过一个深度神经网络来指导蒙特卡洛树搜索(MonteCarlo tree search)。关于这个蒙特卡洛树搜索,我不是很了解这里就不做解读了,有兴趣的读者可以阅读文末参考资料。
首先看下深渡神经网络部分:
深度神经网络的输入是当前的状态 St也就是需要分解的张量(上图中的最右边的粉红色立方体)。输出包含两个部分,分别是 Policy head 和 Value head。
其中 Policy head 的输出是对于当前状态可以采取的潜在下一步行动,也就是一维向量(u(t), v(t), w(t)) 的候选分布,然后通过采样得到下一步的行动。
然后 Value head 应该是对于给定的当前的状态 St ,估计游戏完成之后的最终奖励分数的分布。
接下来简要解读一下整个游戏的流程,还有深度神经网络是如何训练的:
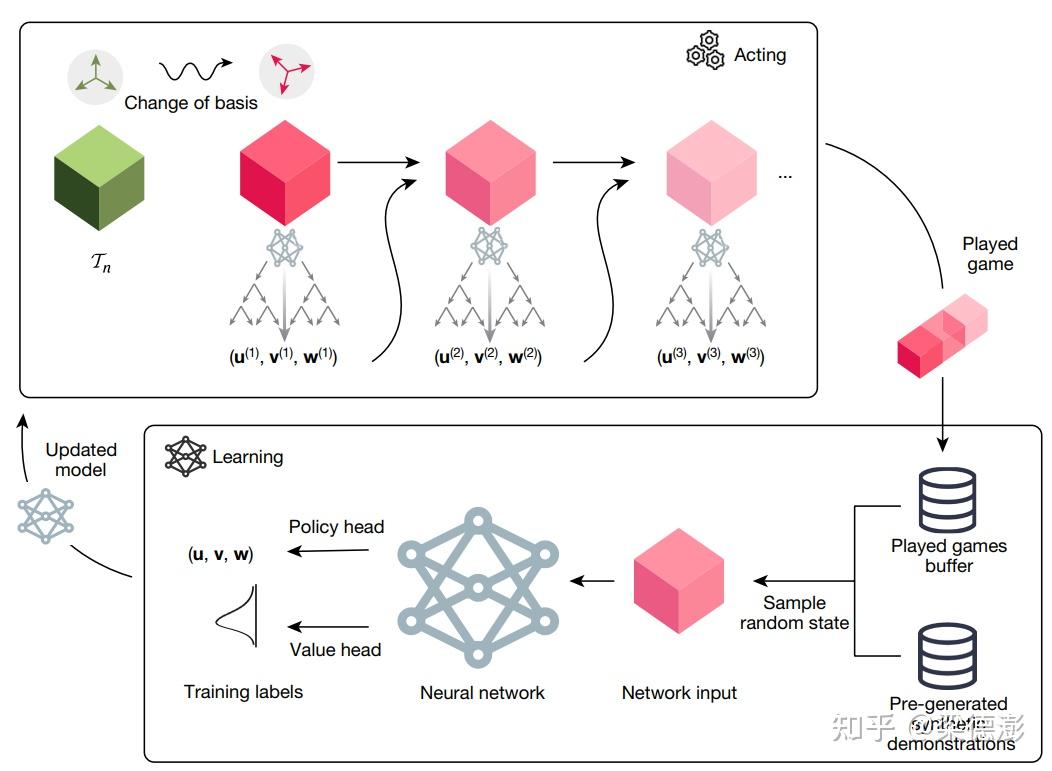
先看流程图的上方 Acting 那个方框内,表示的是用训练好的网络做推理玩游戏的过程。
可以看到最左边绿色的立方体,也就是待分解的3维张量 Tn变换到粉红色立方体,论文中提到是作了基的变换,但是这块感觉如果不是去复现就不用了解的那么深入,而且我也没去细看这块就跳过吧。
然后从最初待分解的 Tn 开始,输入到神经网络,通过蒙特卡洛树搜索得到秩1张量,然后减去该张量之后,继续将相减的结果输入到网路中,继续这个过程直到张量相减的结果为0。
将游戏过程记录下来,就是流程图最右边的 Played game。
然后流程图下方的 Learning 方框表示的就是训练过程,训练数据有两个部分,一个是已经玩过的游戏记录 Played games buffer 还有就是通过人工生成的数据。
人工怎么生成训练数据呢?
论文中提到,尽管张量分解是个 NP-hard 的问题,给定一个 Tn 要找其分解很难。但是我们可以反过来用秩1张量来构造出一个待分解的张量嘛!简单来说就是采样R个秩1张量,然后加起来就能的到分解的张量了。
因为对于强化学习这块我不是了解的并不深入,所以也就只能作粗浅的解读。
实验结果
最后看一下实验结果
表格最左边一列表示矩阵乘的规模,最右边三列表示矩阵乘算法乘法次数。
第一列表示目前为止,数学家找到的最优乘法次数。
第2和3列就是 AlphaTensor 找到的最优乘法次数。
可以看到其中有5个规模,AlphaTensor 能找到更优的乘法次数(标红的部分):
两个 4 x 4 和 4 x 4 的矩阵乘,AlphaTensor 搜索出47次乘法;
两个 5 x 5 和 5 x 5 的矩阵乘,AlphaTensor 搜索出96次乘法;
两个 3 x 4 和 4 x 5 的矩阵乘,AlphaTensor 搜索出47次乘法;
两个 4 x 4 和 4 x 5 的矩阵乘,AlphaTensor 搜索出63次乘法;
两个 4 x 5 和 5 x 5 的矩阵乘,AlphaTensor 搜索出76次乘法;
参考资料
Discovering faster matrix multiplication algorithms with reinforcement learning - NatureThis is a game changer! (AlphaTensor by DeepMind explained)AlphaTensor by DeepMind Explained – Talk by Emma Chen at Harvard Medical AI LabHardware for addition and subtraction: By OpenStax (Page 3/3)「一沙一世界」之硬件加法器-面包板社区硬件乘法器_百度百科[算法系列之十五]Strassen矩阵相乘算法_@SmartSi的博客-CSDN博客AlphaZero ExplainedWhat is Monte Carlo Tree Search? - Artificial IntelligenceAlpha Zero and Monte Carlo Tree Search蒙特卡洛树搜索|AlphaGo的核心算法 |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
×
|

 变色卡
变色卡