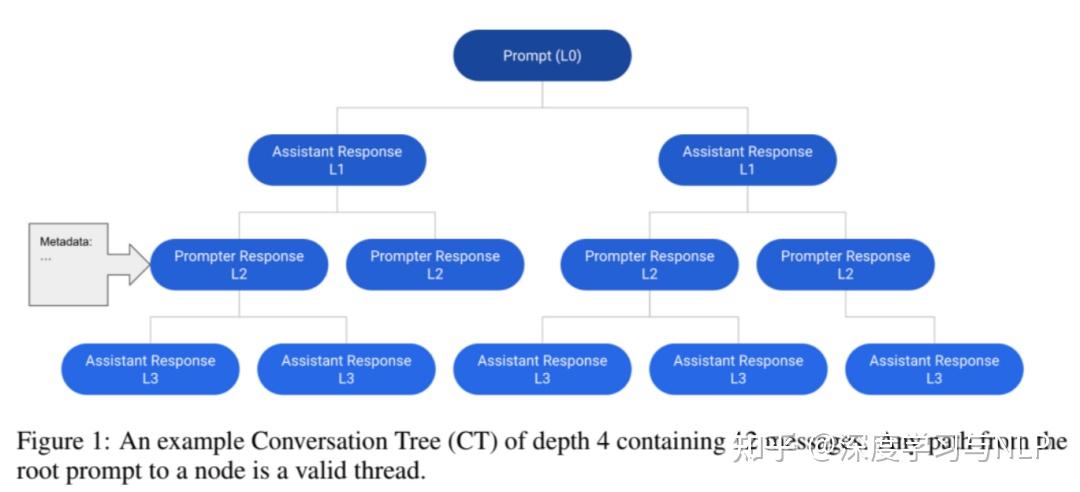
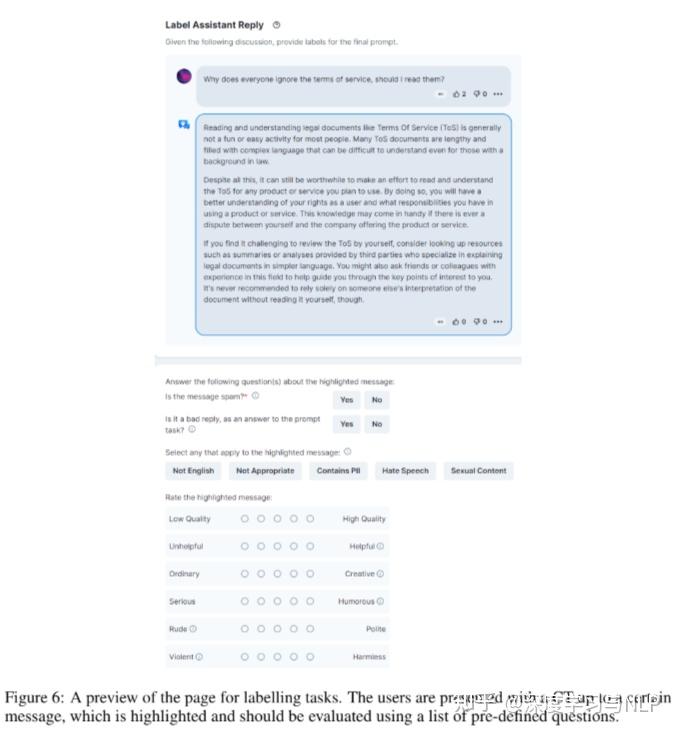
|
|
 发表于 2023-6-13 15:12:37
|
显示全部楼层
发表于 2023-6-13 15:12:37
|
显示全部楼层
几年前我一直被谷歌的bert带沟里,一直在潜水研究bert.....直到chatgpt打了全体地球人的脸,我才开始研究gpt...
我手头有不少逻辑题,能一定程度上测试出模型的推理能力。
我认为有了推理能力,模型才能比较正确的根据自己知识回答用户的各种问题。推理能力差,大部分回答会比较梦幻。。。所以我很看重推理能力。
本次未测试高难度题,只测试简单和中等难度逻辑题。
下边是我测试了一些模型的推理能力(2023年4月-5月测试),基准得分用的是chatgpt网页版。测试环境在各自的母语下。比如llama系列是英文的测试。
本次测试仅仅对于逻辑题的逻辑能力测试,且都是zero shot,单轮对话,没有任何prompt参与,直接问他考题。如果启用高级框架,比如prompt优化,cot,autocot,autogpt,tot这些新一代框架,得分高的模型会更更更好。
打分的数值会由于我的主观估算有一些误差,但是由于每次测试是同一道题横向对比,所以模型的差距清晰可见,所以几乎不存在排名的先后错误,排名次序已经明确说明了模型推理能力的差距。
测试结果(结合测试结果大致打分):
claude 108
chatgpt官方网页版 100
讯飞星火 93
llama 65b (未做测试 但是微调过的版本得分肯定大于90)
openassistant llama 30b gptq4bit 128g 90
vicuna 13b 8bit 86
alpaca 30b gptq4bit 128g 79
bard 75
vicuna 13b gptq4bit 128g 65
alpaca 7b 50
chinese alpaca plus 7b 58
glm 6b 50
文心一言 35
结论
个人电脑中离线版开源模型首选:openassistant llama 30b gptq4 128g 这个版本,推理非常ok.
个人电脑首选离线翻译模型:
chinese alpaca plus7b 。他的翻译效果能达到chatgpt的90%
联网模型首推claude. 推理, 翻译,总结, 样样领先。还免费。且国内网络可用。
文心一言拉胯的要死。。。实测推理能力太差
看到有人回答文新得分比gpt4还要高,我吐了一地。。。。什么鬼?
个人测试,仅供参考。 |
|

 变色卡
变色卡