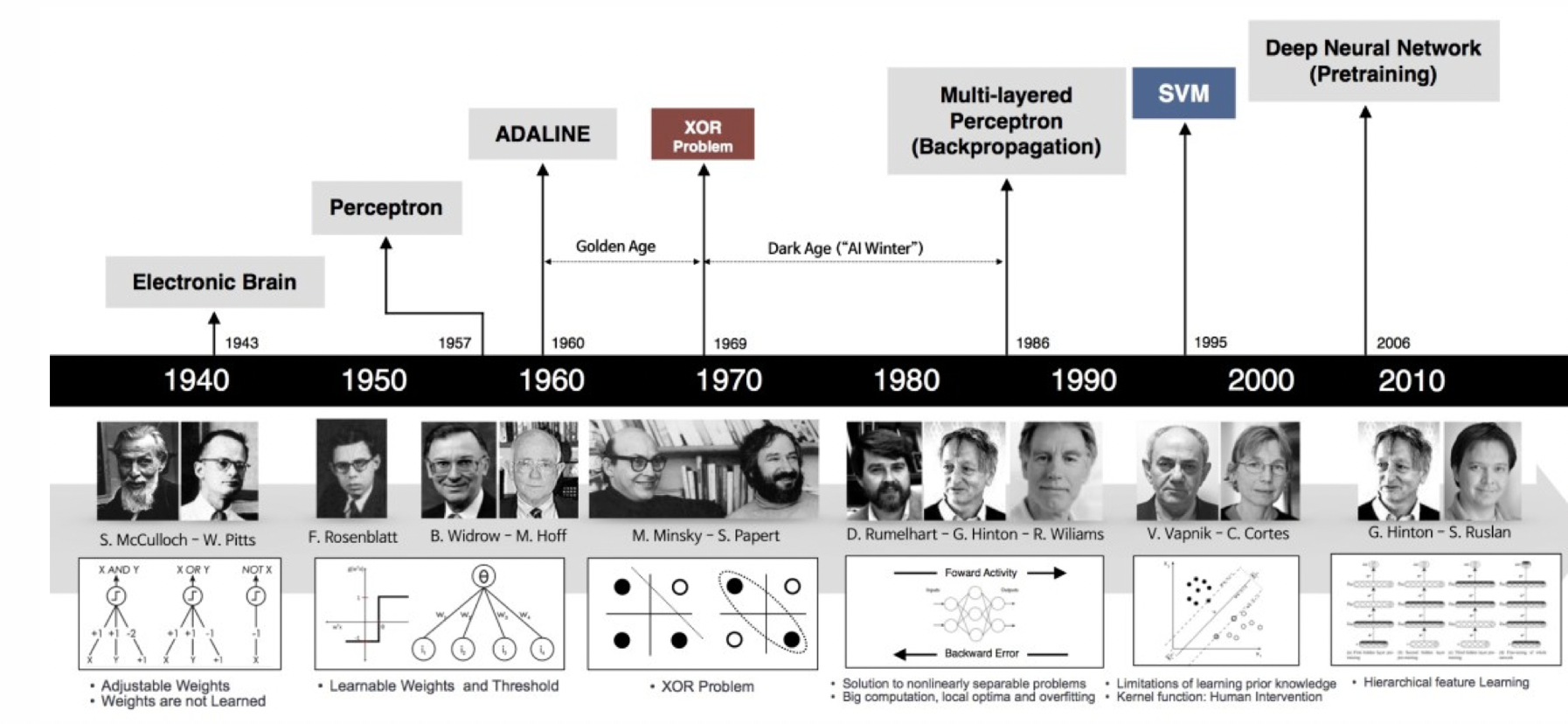
|
|
 发表于 2023-5-12 09:48:42
|
显示全部楼层
发表于 2023-5-12 09:48:42
|
显示全部楼层
首先, 是都和 C++ 有关, 还有比 C++ 更令人头大的 CUDA
其他语言的话, 坚决演进的就一个 Julia 了吧, 其他纯 Java, 纯 Rust 都是玩具罢了.
Python 那真的是生态好, 几个巨头都带着玩.
这东西没有巨头带就是不行, 大公司都玩不动, 小公司就是送.
分享一个小公司小语言的惨痛经历
<hr/>我第一次见深度学习是 16 年的 Image Style Transfer(IST)
当时我还在写 Wolfram, 那天 Mathematica 讨论组里放出了风格迁移的星月夜
当时讨论组就炸了, 这个真的是任何传统手段都难以望其项背的效果
Mathematica 挺进深度学习就这样被提上了日程, 后来综合观察了一下口碑, Wolfram 的技术选型就选了 MXNet
当时自我感觉良好, 现在看还不如押宝 TF
再说一遍这玩意儿没巨头真带不动, 现在还在用 MXNet 的公司, 那......
不过反正大家早期都半斤八两, 社区优势也没啥, 大不了我自己造算子呗
17年我在 Wolfram 复现的 Progressive Growing of GANs(PGGAN)
PGGAN 当年还是相当惊艳的
结构现在看来整体相当简单, 要手写的算子也就 PixelNorm 一个, 也是个非常简单的算子.
计算力现在看来, 就这?
<hr/>18 年上半年感觉就不行了, 没有一个强大的社区带, 那年花式 Norm, 花式 Attention, Paper 井喷
压根实现不过来, 全部自己写太不现实了, 只能挑重点.
18 年我国内跟进的 Style-Based Generator Architecture (StyleGAN)
因为之前有个 StarGAN 还是什么玩意儿, 记不清了, 反正不能缩写为 SGAN
StyleGAN 效果拔群, 其他 GAN 都歪瓜裂枣的, 就他有个人样
原版 StyleGAN 的实现有问题, 会有个伪影, 是连续8个FC放大了某个随机 bug, 我从头实现的就没这个伪影.
算子还行吧, 就一个 AdaIN, loss 稍微算难的, 主要就研究源码里这个 loss
源码魔改了 TF, 直接把我给看蒙了, 没见过这种操作
但是计算量那是突破个人显卡的水平了, 不过还是属于租个高配能玩的地步, 不跑 1024 还是承受得起的
<hr/>后来 SG2 出了, 我一是水平跟不上了, 而是也没那么多卡, 三是 MXNet 都没落了, 四是那年下半年 DL 杀疯了, 我混不到饭吃了
总之, 跟不上版本了, 我就半主动半被动的脱坑了当时 Wolfram 讨论要不止损转 libtorch, 想了想还是舍不得前期投入, 那就祝 ONNX 能一统天下吧? 我 Emmmmmm
可以看出这种要烧钱的玩意儿, 你还是得听巨头的, 巨头用啥你用啥, 别和钱过不去 |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
×
|

 变色卡
变色卡