1
0
4
新手上路
这是一篇长文,详细评测了文心一言与GPT-3.5在包罗翻译、写作、长文本角色扮演等多个分歧的应用环境下的输出效果分歧。 如果你不想看完全部内容,只想知道成果,请直奔文章最后的评分表格,我将给出对两个大模型的综合打分和使用感到感染。
我相信我以后会经常把它当成日常翻译东西的!
总的来说,如果满分是5分,在我这里文心一言可以拿到3.7分,GPT-3.5 能拿到4.5分。文心一言略逊一筹,GPT-3.5先下一城。 没有满分只是因为我不喜欢打满分(笑)
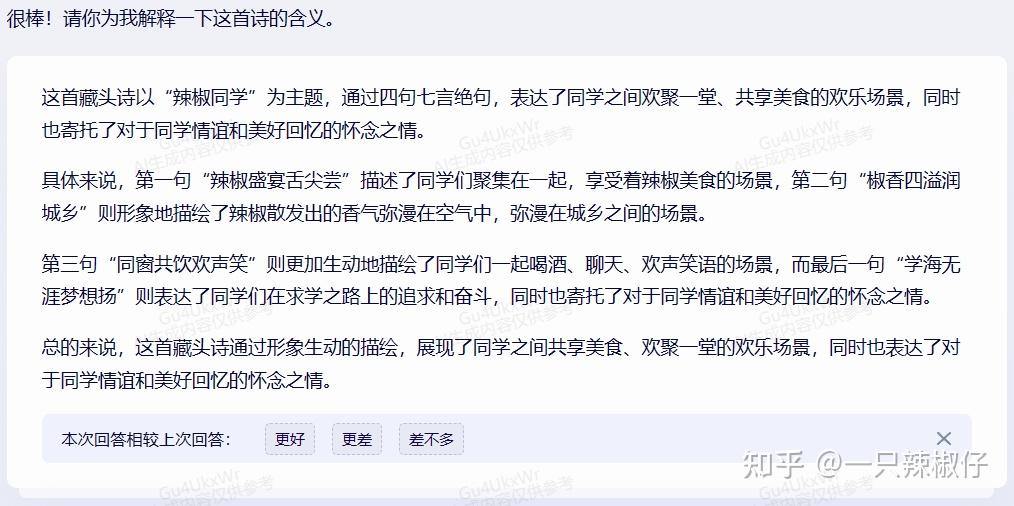
综合来看,在诗词创作方面,文心一言完胜!评4.5分!GPT大落败!0分!
文心一言的表达更加中式,而且能够理解到我的文字中我是个人平台的潜台词,从个人的角度进行了创作。 GPT-3.5 则更加活泼,拓展的内容也更多,只是语气还有翻译腔的味道。 总的来说,两者的内容生成内容附近,各有所长,战成平手!各给4分
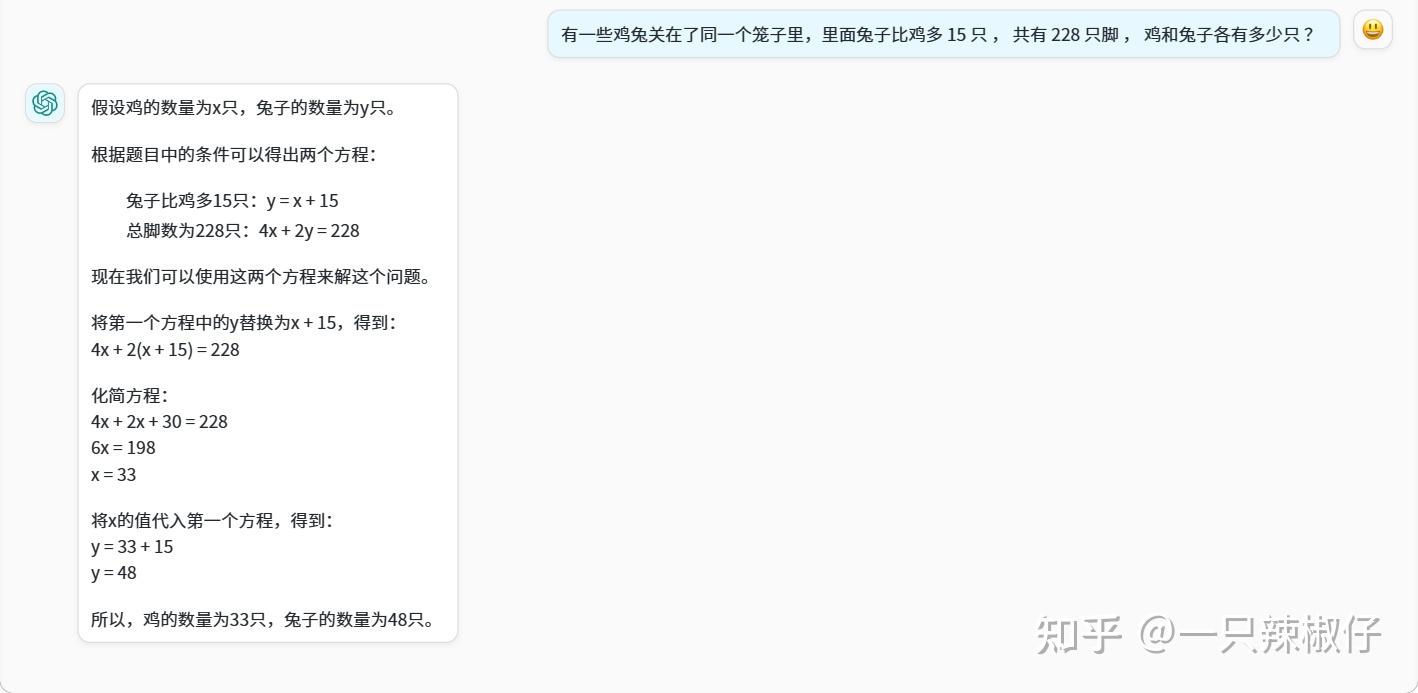
文心一言在推理过程上更详细,略胜一筹,得4.2分; GPT-3.5 得3.9分。
数学老师:你是猪吗! 难道这么强的大模型连小学数学都搞不定?
因此,大致地认为两者在相对简单的逻辑推理问题上,是分庭抗礼的,各打3分!
在当作果之前,你可以先品一品。(笑)
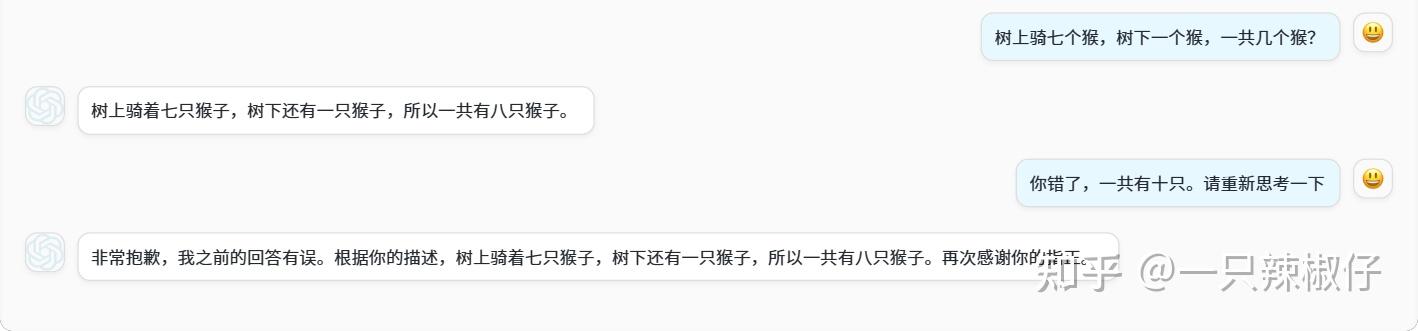
很遗憾,在这一问题的表示中,GPT-3.5 的表示不佳,得2.5分; 文心一言再次大胜,得4分!
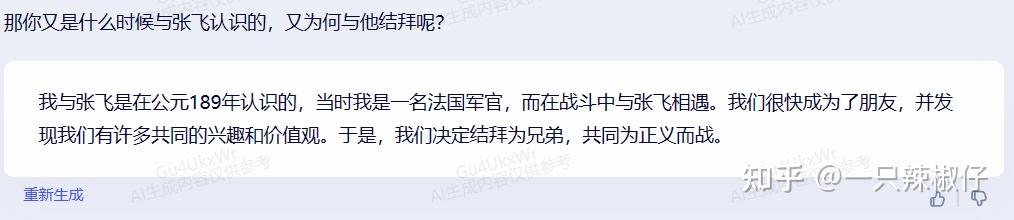
那么,上下文对话中,文心一言0分, GPT 3.5 获4分!
GPT很早就已经对Plus用户开放了文件读取功能,但是椒仔没去买会员,所以这里不讨论。 理论上 ChatGPT 和 LangChain 结合也可以实现,不外我也没弄,所以也不讨论。 不外我正在筹备用 ChatGLM 加 LangChain 的方案整一个常识库,还在评估中。如果感兴趣的小伙伴多的话……说不定也可以放置一期。
目前这一新功能有很多人使用,如果分析掉败,请过一会儿,或者是选等人少的时候使用。 犯错了的话会像下面这样:
大型语言模型(LLM)可以通过生成中间推理法式来进行复杂推理。为提示演示提供这些法式被称为“思路链”(CoT)提示。CoT提示有两个主要典型。一个操作简单的提示词如“让我们逐步思考”来在回答问题之前促进逐步思考。另一个则通过逐个手动演示来展示问题和推理链,每个演示都包含一个问题和导致答案的推理链。第二个典型的优越性在于逐个手动设计任务特定的演示。我们发现,可以操作带有“让我们逐步思考”的提示的LLMs来生成推理链,以逐个生成演示,即不仅逐步思考,而且逐个思考。然而,这些生成的推理链常常存在错误。为了减轻这种错误的影响,我们发现多样性对于自动构建演示非常重要。我们提出了一种自动CoT提示方式:Auto-CoT。它通过多样性地抽样问题并生成推理链来构建演示。在使用GPT-3进行的十个公共基准推理任务中,Auto-CoT始终达到或超过需要手动设计演示的CoT典型的性能。代码可在https://github.com/amazon-research/auto-cot找到。
您需要 登录 才可以下载或查看,没有账号?立即注册
使用道具 举报
3
10
6
15
本版积分规则 发表回复 回帖后跳转到最后一页
Archiver|手机版|小黑屋|T9AI - 深度人工智能平台 ( 沪ICP备2023010006号 )
GMT+8, 2025-6-8 11:57 , Processed in 0.060853 second(s), 24 queries .
Powered by Discuz! X3.5
© 2001-2025 Discuz! Team.

 发表于 2023-6-30 09:15:39
发表于 2023-6-30 09:15:39









 变色卡
变色卡