|
|
 发表于 2023-6-25 17:01:31
|
显示全部楼层
发表于 2023-6-25 17:01:31
|
显示全部楼层
最近很多小伙伴的 ChatGPT 被封号了,Midjourney [1]也宣布不再对新注册的用户提供免费的画图体验,即便是原来用来分享模型的 C 站[2]也被挡在了墙外…
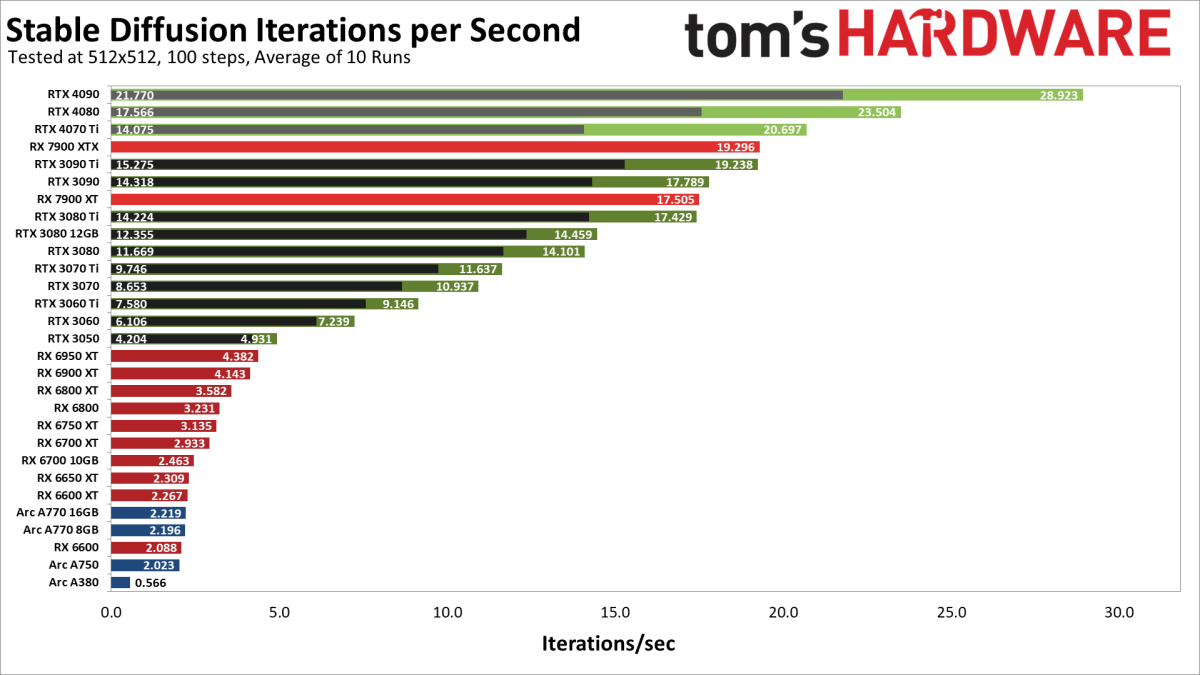
可以说使用这些AI 工具的门槛也是越来越高了,还是把模型握在自己手里最稳妥,但是本地炼模型、画图动辄 4090 起步,8 卡 A100 不够用,普通玩家肯定是没这样的条件的。网上有很多教程教大家用谷歌 Colab,但是 Colab 还是有一定的访问限制。
今天带大家用最低的成本来体验一下云端部署 Stable Diffusion 炼图:
1、国内访问无障碍;
2、不需要自己买显卡,可使用云端的 3090、A100 显卡;
3、Stable Diffusion 一键部署,云服务中自带部分底模/LoRA,也可以自己上传;
4、价格低廉,而且服务开启后,可在任意电脑远程操作画图,支持多人使用(按提交任务顺序排队)。
简单来说就是,用比网吧还低的价格,体验 RTX3090 24G 显卡,独享 Stable Diffusion WebUI [3]的云服务器。
以下是操作步骤:
一、注册账号
揽睿星舟-GPU算力平台平台本身是 GPU 算力平台,提供箱即用的训推环境,大容量、高可用的分布式文件存储以及开放的镜像生态。
除了部署 Stable Diffusion 以外,还可以用作其他模型的训练和使用,适合没有显卡但又有需求的小伙伴使用~趁着现在人少不排队,赶紧用起来。
(每次用完记得关机,要记得看账单,数据盘会导致额外计费)
二、新建运行环境并部署 Stable Diffusion
这一步是重点,有两种方式(甚至三种):
1、在应用市场中新建 Stable Diffusion 应用,再为这个应用建立服务器实例;
2、在算力市场中购买服务器实例,在新建直接安装使用官方提供的 Stable Diffusion 镜像;
3、新建一个空白的服务器,然后自己从零开始配环境(鉴于开机就会收费,为什么要浪费时间安装环境呢…)
不过根据我实际测试,如果在应用市场直接新建 SD 服务,就会默认选择一台原价的 3090 显卡:
所以我选择更便宜的做法…
我们先新建一个服务器实例,镜像选择「公有镜像 - others - sd-webui - output」,数据集选择「sd-base」
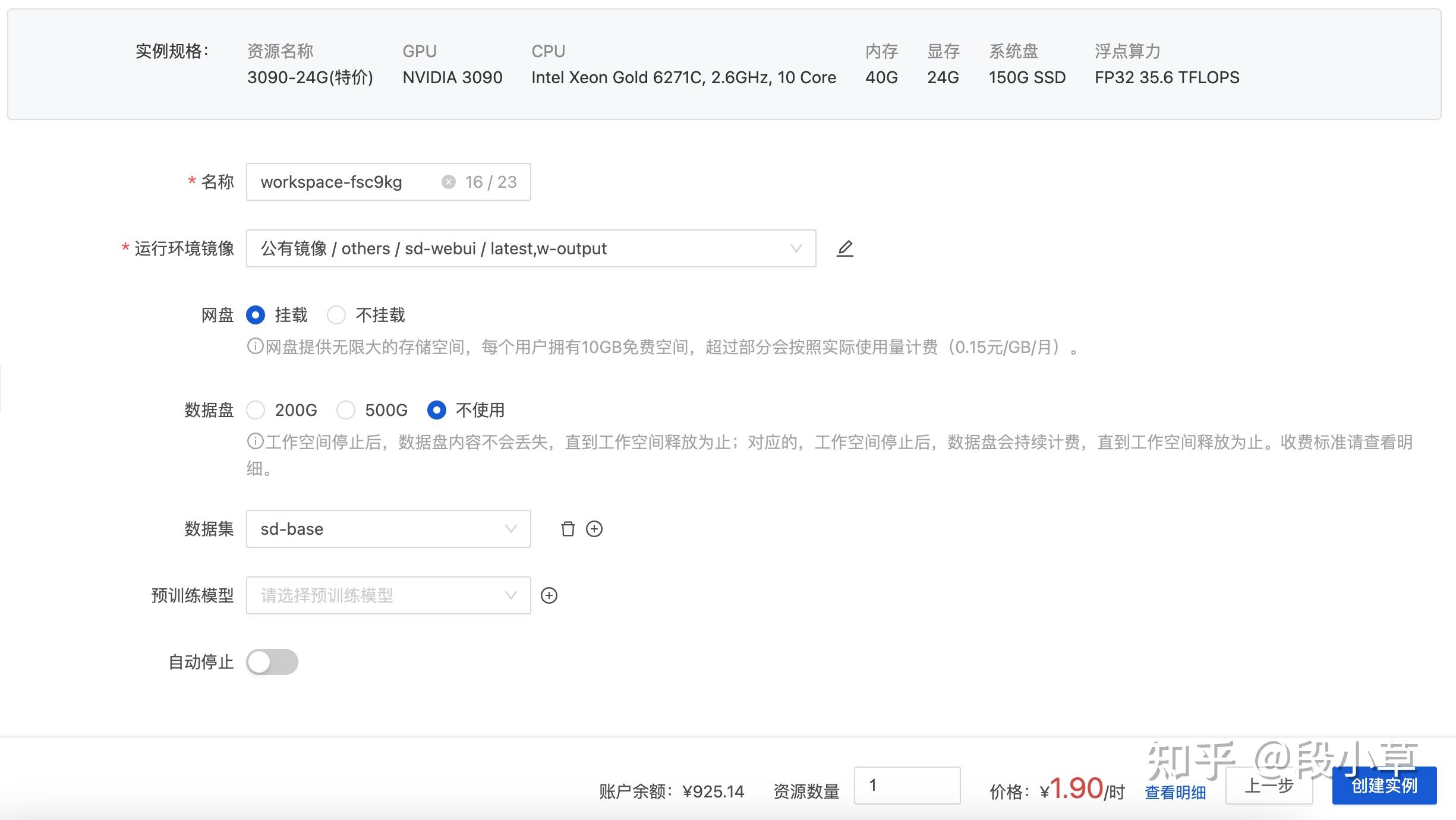
注意非必要不选择数据盘,会额外计费!
稍等几分钟,镜像启动好之后,选择进入 JupyterLab:
页面左边是文件目录,在页面右边的窗口中,既可以使用 Notebook,也可以直接使用终端 Terminal。
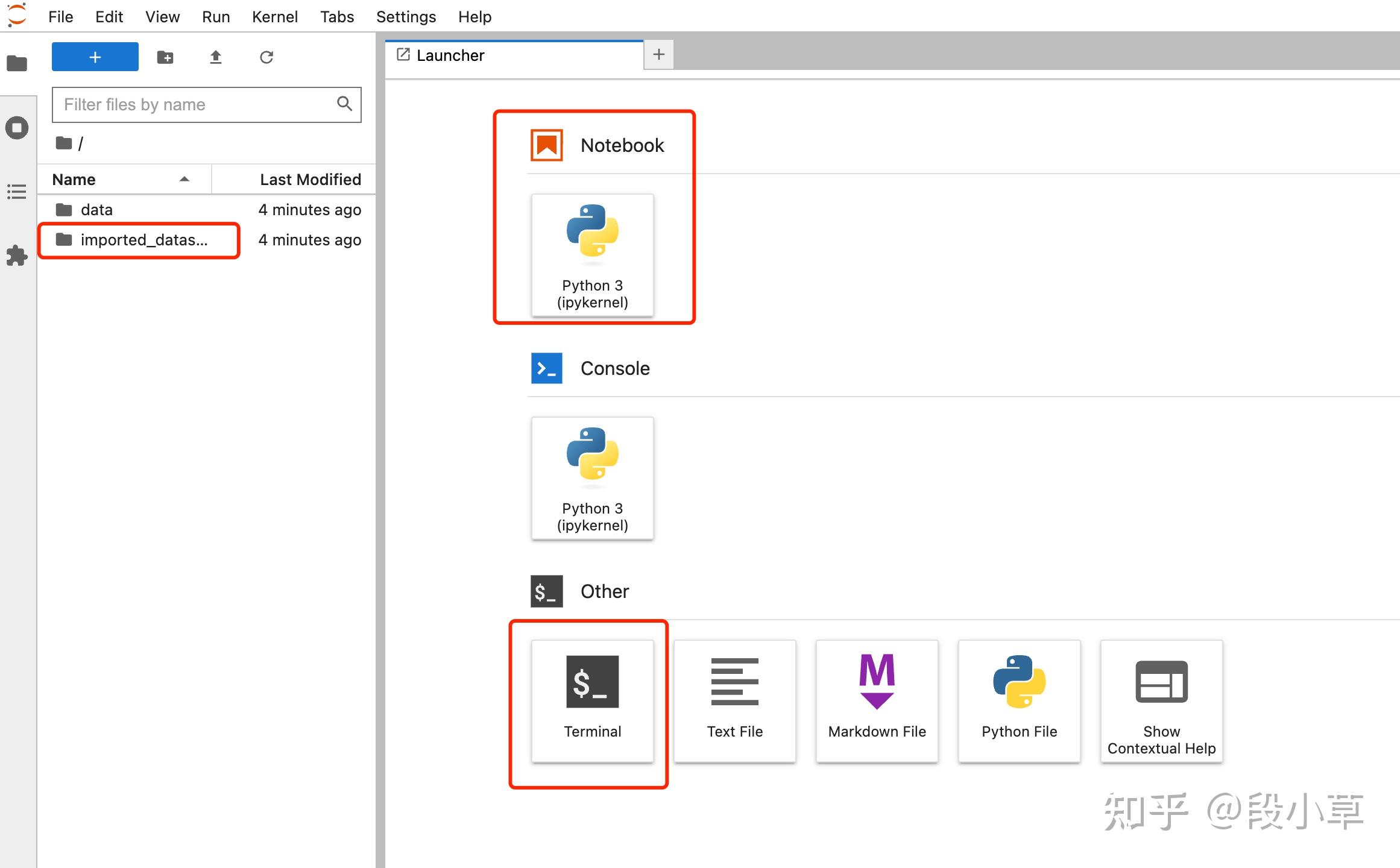
新建一个 Terminal,我们可以先用 nvidia-smi 命令查看一下显卡详情:
然后分别运行这两行命令:
cd /app
bash webui.sh --port 27777 --listen --xformers --enable-insecure-extension-access
等待启动完成,回到控制台,点击复制调试地址,会自动复制一个网址。
这样我们就拥有了专属于自己的 SD 服务器,可以开始画画了~
(以上全过程耗费 5-10 分钟,之后每次只需要启动/终止镜像,并启动 SD 服务即可。类比开机+运行软件)
三、使用 Stable Diffusion 作图
我们访问上一步最后复制的网址,网址应该类似于
ws-xxxxx-xxxx-xxxxx-xxxx-xxxxxxxx-debug.rde-ws.lanrui-ai.com
注意,这个网址可以在多台电脑同时使用,相当于是一个公网的作图服务。但是!实际作图并不会多线程进行,而是根据提交的顺序排队作图,所以…不要把自己的地址分享给太多小伙伴~
下面是简单的界面介绍,详细的教程大家可以自己摸索或者到 B站看一下视频讲解。
我们可以看到,服务器在预设中已经为我们准备了很多常用的模型:
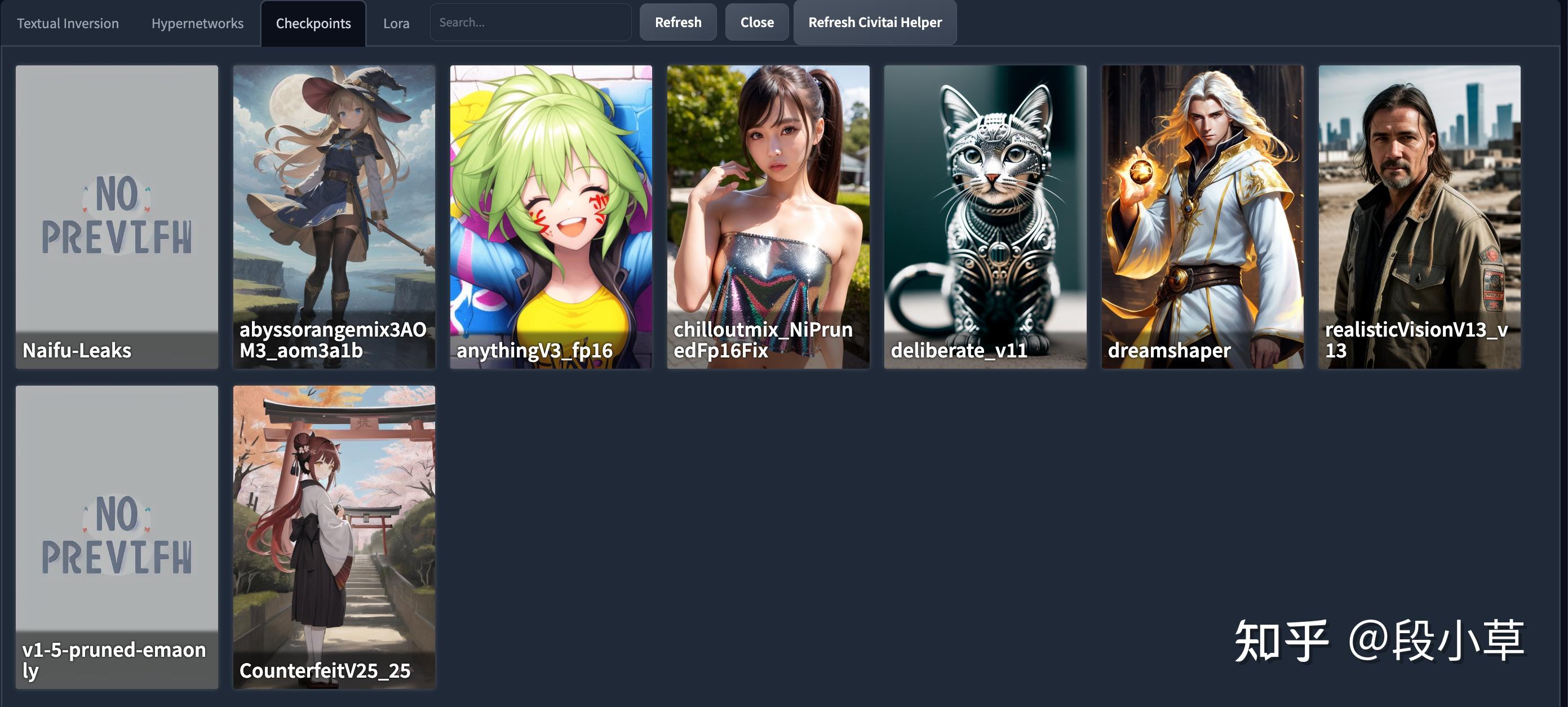
我们先来小试牛刀~测试一下 Stable Diffusion 服务是否启动正常:
四、上传 LoRA 模型
Stable Diffusion 中的模型主要分两种:
1、底模:基础模型,比较大,体积一般都在 5G 左右甚至更大;底模每次只能载入一个。
2、LoRA:微调模型,在 AI 绘画中主要指画面风格滤镜、特定的角色、人脸人像等。体积一般 200MB 左右。 我们主要寻找一些 LoRA 模型就可以了。
如果服务中预置的模型不能满足需求,我们就需要自己通过其他途径先下载到 LoRA 模型再自己上传到相应的目录。
由于现在 C站[4]不能直接访问了,所以在命令行下也不能直接用 wget 下载模型了(需要配置代理)。好在 LoRA 文件一般都不大,大家可以通过其他方式下载好之后,上传到自己的服务器网盘即可。
比如我们要下载 Moxin 模型[5]:
点击右上角 Download 下载到本地。
来到服务器的网盘页面:
每个用户都有 10G 的免费网盘空间,在新建 SD 时我们已经用掉了一部分。
把我们自己下载的 LoRA 模型,上传到 /data/sd/models/Lora/ 目录即可。
如果你下载的是体积更大的底模,则需要上传到 /data/sd/models/Stable-diffusion/ 目录。
上传完整后,无需重启服务器,直接刷新页面,即可完成新模型的加载,可以直接使用。
我自己上传了 Moxin 模型和之前很火的明日方舟德克萨斯模型[6]。
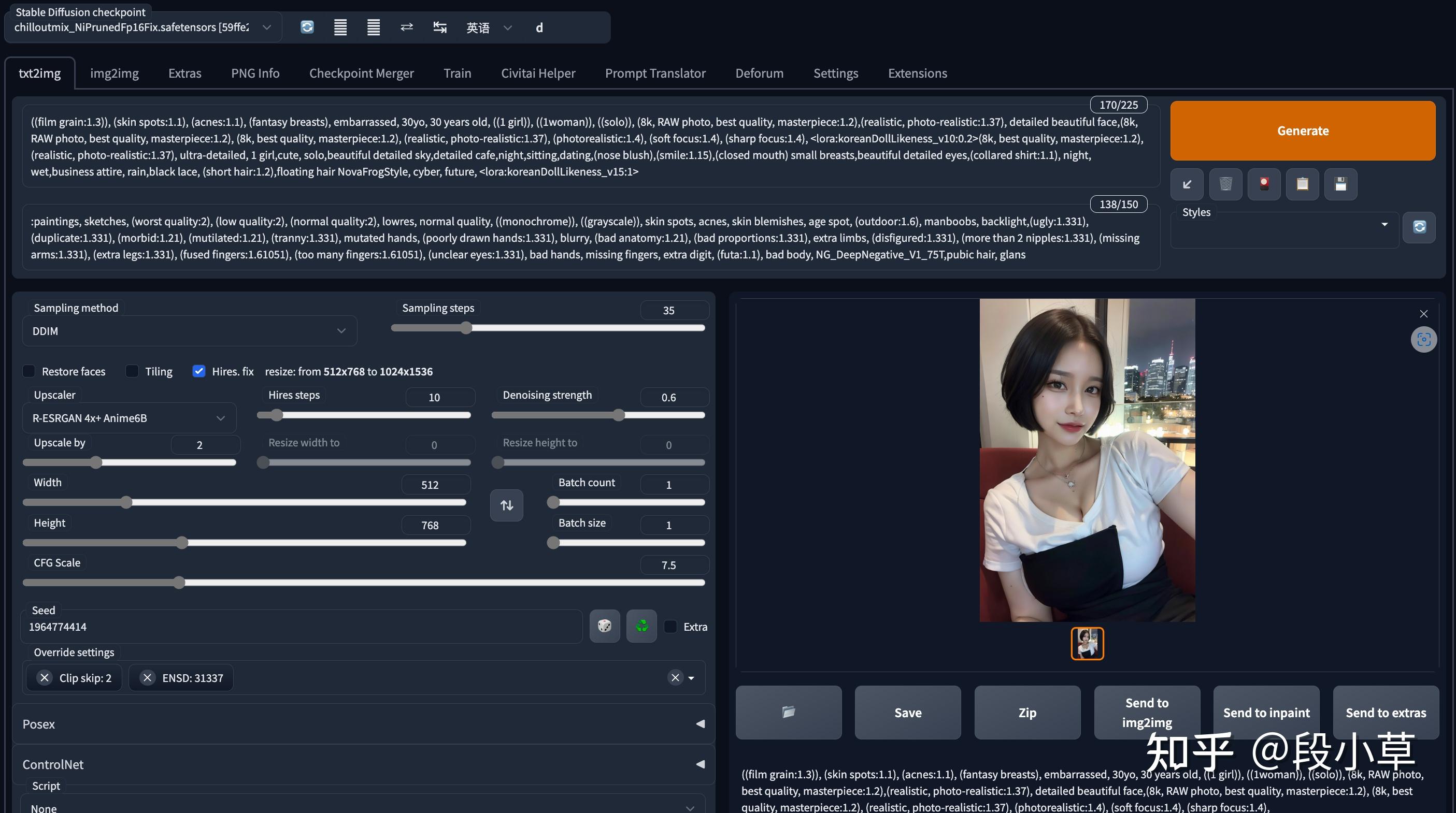
下面简单分享两张图片及 prompt(生成的图片会自动保存到网盘里):
shukezouma, negative space, , shuimobysim , <lora:Moxin_10:0.6>, portrait of a woman standing , willow branches, (masterpiece, best quality:1.2), traditional chinese ink painting, <lora:Moxin_Shukezouma11:0.8>, modelshoot style, peaceful, (smile), looking at viewer, wearing long hanfu, hanfu, song, willow tree in background, wuchangshuo,
Negative prompt: (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, skin spots, acnes, skin blemishes, age spot, glans, (watermark:2),
Steps: 30, Sampler: DPM++ SDE Karras, CFG scale: 3.5, Seed: 2774560679, Size: 640x1024, Model hash: 59ffe2243a, Model: chilloutmix_NiPrunedFp16Fix

(8k, RAW photo, best quality, masterpiece:1.1), (realistic, photo-realistic), omertosa,1girl,arknights,cute,cityscape, night, rain, wet, city street, standing facing viewer, black hair,open clothes,bare_shoulders, blue skirt,black stockings, professional lighting, photon mapping, radiosity, physically-based rendering, <lora:koreanDollLikeness_v15:0.5>, <lora:arknightsTexasThe_v10:0.8>
Negative prompt: easynegative, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,strange fingers,bad hand
Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 8, Seed: 3387909407, Size: 576x792, Model hash: 59ffe2243a, Model: chilloutmix_NiPrunedFp16Fix, ENSD: 31337, Eta: 0.68
祝大家都能实现显卡自由和 AI 画画自由~之后也会继续分享自己炼 LoRA 的记录。
以上。 |
本帖子中包含更多资源
您需要 登录 才可以下载或查看,没有账号?立即注册
×
|

 变色卡
变色卡